Плодовый клоп, сидящий на кусте садовой малины, уверен, что малина существует для того, чтобы он её ел. Мысль о том, что этот куст кто-то посадил для себя, не приходит ему в голову, и глупо укорять клопа за эту ошибку. Хотя соглашаться с тем, что малину выращивают для клопов, ещё глупее.
Однако мы сами отчасти уподобляемся этому неразумному насекомому, когда говорим "цифровизация – это прежде всего удобно". Малина – это прежде всего вкусно, да. Но кому? Клопу? А с какой стати? Кто сказал, что именно клоп главный, а не вот это существо, например?
Или не его дедушка, посадивший малину? Или не тот, кто выпустил постановление, согласно которому дедушка получил право на шесть соток и выращивание малины... Но клопу это абсолютно неинтересно. Клоп считает всё это натягиванием совы на глобус.
Что ж, оставим сову в покое. Поговорим о прогрессе.
Останови́м он или неостановим – вопрос философский, а вот управлять прогрессом можно. Можно, например, притормозить заморозить исследования по искусственным углеводам, заменив их исследованиями в области генной модификации сельскохозяйственных культур. Или вот в 50-60-е годы прошлого века магистральным путём прогресса считалось освоение космоса. Космос тогда рассматривали как возможность экстенсивного развития технологической цивилизации: космос – это ещё больше ресурсов: ещё больше пространства для жизни и производства.
Почему космос был так важен для человечества в первые послевоенные десятилетия? Нет, не потому, что таков был побочный эффект прогресса – развития военных ракетных технологий. Дело было в другом.
Производство не может достичь определённого уровня и остановиться: производство либо расширяется, либо гибнет. Почему? Таковы законы придуманной людьми в XVII–XIX столетиях индустриальной экономики. Допустим вы решили заняться производством сковородок. Для этого нужно закупить сырьё, арендовать оборудование, нанять рабочих...
У вас на всё это денег нет. Они есть у кого-то, кто сам заниматься производством сковородок не хочет – ну вот не хочет и всё! Однако согласен дать денег вам – при условии, что вы долг вернёте, конечно. И вот это вот долг, именуемый кредитом либо инвестицией, будет заставлять вас всё время выпускать и продавать больше продукции, чем необходимо для окупаемости производства. Вы должны не только окупить производство, но и окупить долг. А для этого вам придётся выпустить больше продукции, чем вы планировали. А чтобы выпустить больше продукции, понадобится больше сырья, больше рабочих, больше оборудования и... да что же это такое, опять больше денег! Которых, напомним, у вас нет, но вы можете и их тоже взять у кого-то в долг. А чтобы вернуть и этот долг, вам понадобится в следующем производственном цикле выпустить и продать ещё больше сковородок, а для этого ещё больше закупить... нанять... и занять.
Вот почему производство должно всё время расти.
Но на Земле оно бесконечно расти не может, потому что Земля конечна, и население её, и ресурсы её конечны. Поэтому-то в 50-е годы и существовала большая (и наивная, как мы понимаем теперь) надежда на освоение космоса. Не у простых людей, разумеется. У «планировщиков».
Однако уже к началу семидесятых стало ясно, что ближний космос для колонизации не годится. А о дальнем мечтать пока рано, да и неизвестно, что там. И космический проект пришлось потихоньку сворачивать. Космос больше не надежда человечества, а так, что-то сбоку припёка, на обочине «магистрального пути прогресса». А «магистральный путь» – это «цифровая трансформация», сокращённо – «цифровизация».
Цифровизация чего?
Это очень интересный вопрос, но сперва закончим с прогрессом. Это, как мы предупреждали, вопрос философский, поэтому, если вы не любите философствований, прокрутите текст до следующей картинки.
Три модели
"Прогресс" – это миропредставительная модель. То есть упрощённая схема, и даже не схема, а образ, с помощь которого мы "понимаем", как устроен мир. Но на самом деле не понимаем, а именно представляем – то есть воображаем. И это воображение (фантазия, миф) заменяет нам понимание.
Модели мира бывают двух типов: циклическая (всё движется по кругу, как солнышко по небу) и направленная (всё движется к некоей цели, к некоему результату, как стрела летит в цель). Микс этих двух типов – хитровыгнутая спиралевидная модель: вроде бы и по кругу, но "на каждом витке выше", а значит – всё-таки направлено, всё-таки к цели. Таким образом, "спиралевидная модель развития" тоже направленная.
А теперь интересное: циклическая модель предполагает, что мир вечен. А направленная модель предполагает, что он конечен. Ведь если у процесса есть цель – то есть и конец процесса. (Либо, если цель недостижима, она бессмысленна.)
Вы скажете, дудки: одной цели достигли – ставим перед собой другую, потом ещё другую и ещё другую, и так бесконечно? Но знаете ли, как в философии называется такая модель? "Дурацкая бесконечность".
Ладно, это мы уже вбок от вбока пошли, заканчиваем. Прогресс – модель эсхатологическая. То есть описывающая (невольно) конец мира. Его смерть.
Эта невольная эсхатология постоянно вырывается из подсознания сторонников направленной модели – то в виде концепции "конца истории" японо-американца Фукуямы (над ним у нас принято смеяться), то в виде советской концепции Коммунизма – Светлого будущего, наиболее выдающиймся представителем которой были не Хрущёв, не Суслов и не Маркс-Энгельс-Ленин, а Иван Ефремов, автор "Туманности Андромеды". Ну достигли светлого будущего, а дальше? Ради чего жить и трудиться, за что бороться? (Заметьте: для ответа на этот вопрос – "Что дальше?" – Ефремову тоже понадобился Космос...)
Вот, кстати, три иллюстрации к роману Ефремова. Сюжет один, но обратите внимание на "разночетния". Первая иллюстрация (слева) 1958 года: реалистичная, но слегка обобщённая, с налётом романтичной мечты. Вторая 1962 года: космос стал реалистичнее, добавилось деталей как в материальной среде, так и в характерах персонажей. "Космос реален". Третья – 1999 год, уже нарочитая условность, сказка, миф... (Зато важное значение приобретает бюст героини.) Тоже своего рода "три модели".
Так вот, теперь о цифровизации – цифровизация чего она. Если одним словом – то управления. "Цифровизация процессов управления процессами". (Не смейтесь, это правда так.) И начать это объяснение следует сначала – с кибернетики...
Кибернетика
Вы, конечно, знаете, что каких-нибудь полвека назад именно так называли всё то, что мы сегодня в быту называем "цифровизацией", то есть – "всё связанное с компьютерами".
Автоматический пылесос под названием "Кибернетика" из "Незнайки в Солнечном городе"
Однако само слово "кибернетика" весьма древнее, и история его интересна и примечательна. Ещё в 1834 году физик Ампер в книге «Очерки по философии наук» описал науку под названием «кибернетика». И заимствовал он это слово аж у древнегреческого философа Платона.
По-гречески «кибернетикес» (κυβερνητικης) означает «искусство управления кораблём», но сам Платон использовал это слово в трактате «Республика» как образное описание управления людьми: «Как мудрый кормчий правит в море кораблём, так и мудрый правитель правит своим народом».
То есть кибернетика – это наука об управлении.
В 1948 вышла книга «Кибернетика, или управление и связь в животных и машинах» Норберта Винера – учёного, которого называют основоположником современной кибернетики. Он сделал важное открытие: существуют универсальные законы управления и использования информации, единые как для машин, так и для живых организмов.
Что изучает, чем занимается кибернетика? Её интересуют абсолютно любые системы, в которых присутствует управление. В математической функции значение одной переменной может управлять другой переменной? Да. Значит, кибернетику интересует математика. Кошка бежит туда, куда бежит мышка? То есть можно сказать, что «мышка управляет кошкой»? Обезьяну можно научить дёргать за верёвку, чтобы получить банан? Да. Значит, кибернетику интересует поведение животных.
А поведение человека? Интересует ли оно кибернетику, как вы думаете?
Зачем компьютеры изучают «цифровой след» человека – то есть запоминают, как он ведёт себя в интернете? Какие совершает покупки, какими сервисами пользуется, какими передвигается маршрутами, какую информацию читает, а какую пролистывает, не читая, какие мнения «лайкает», а какие «дизлайкает», а значит, каких придерживается убеждений? Эта информация собирается в огромные базы данных – для чего?
«Очерки по философии наук» Ампера (1843) и «Кибернетика» Винера (1948)
В своей книге «Кибернетика» Норберт Винер писал о том, что законы кибернетики могут применяться для изучения поведения людей, развития общества, взаимодействия социальных групп.
А это значит, что компьютер может не только прогнозировать, как поведёт себя человек, но и программировать его на то или иное поведение. Например – настойчиво предлагать ему определённую информацию, а другую информацию – скрывать. Чтобы одних возможностей лишать, а другие – навязывать.
Для чего это нужно? Для того, чтобы попытаться справиться с индустриально-финансовым кризисом, охватившим планету, – чтобы перейти от "рыночной" системы к "планово-распределительной" – как в СССР, да, но на новом технологическом уровне. От "общества потребления", потребности которого индустриальная цивилизация больше не может обслуживать, – к обществу распределения. К обществу жёсткого экономического и социального регламента.
Вроде бы цель благая, но тут возникает следующая загвоздка...
Один из главных законов науки об управлении – кибернетики называется «закон Винера–Шеннона–Эшби». Он гласит:
«Управляющая система должна иметь бо́льшее разнообразие, чем разнообразие управляемых систем».
В переводе на понятный язык: «Тот, кто управляет, должен знать и уметь больше, чем тот, кем управляют».
А теперь подумаем: что должно произойти, когда средний компьютер будет уметь выполнять разных действий больше, чем средний человек? И когда компьютерная система будет знать о поведении людей больше, чем люди знают о поведении этой системы?
Совершенно верно. Компьютеры начнут управлять людьми.
Конечно, можно сказать, что сегодня и светофоры управляют людьми (кстати, с помощью тех же компьютерных программ), и ничего страшного не происходит – наоборот, от этого только лучше…
Но одно дело, когда светофор командует, как нам ходить по улицам. И совсем другое – если он начнёт командовать, куда нам идти. Как жить. Для чего жить. Чего хотеть, а чего не хотеть… Чувствуете разницу?
Когда люди массово и с охотой отказываются от главных завоеваний эволюции, выделяющих их из животного мира, – от разума и свободы воли, – возникает вопрос: в обмен на что?
На этот вопрос мы предлагаем ответить вам. Как вы думаете?
Представьте, что на ночном небе среди звезд будет созвездие… рекламы, привлекающее внимание миллионов людей
Да, вы не ослышались, реклама выходит на новый уровень - бренды будут рекламироваться прямиком из космоса.
Ракета «Ангара» вывела на орбиту прототип спутников, которые будет транслировать рекламу, собираясь в скопления по несколько десятков штук.
Целая группа таких спутников будет кружить по орбите на высоте в 500 км, группируя логотипы и тексты, которые из Земли будут напоминать созвездия.
Всего-то 1 миллион долларов, и о вашем бренде узнает вся планета! Правда пока на небе будут сиять бренды, которые итак знает вся планета)
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой телеграм канал НейроProfit, там я рассказываю, как можно использовать нейросети для бизнеса.
Nvidia - одна из ключевых компаний мира прямо сейчас. Существует популярное мнение, что они просто везунчики, которые всегда оказываются с нужным продуктом в нужное время. Однако, если историю развития этой компании, то станет отчетливо видно, что эти ребята умеют мастерски конкурировать, делают полезные выводы из провалов и отлично "ловят волны". Сегодня разберемся, как им это удается.
Главный секрет Nvidia в том, что её основатель ходит с стильной кожанке. Спасибо за внимание. Ладно, шучу, сейчас во всем разберемся.
Nvidia обогнала по стоимости Saudi Aramco, и теперь выше детища Дженсена Хуанга лишь Microsoft да Apple. Microsoft за последние годы ИИ-бума влезли в очень плотную зависимость от чипов Nvidia, из-за чего сейчас экстренно пилят собственную замену. Apple же слез с чипов Nvidia в 2010-х, но, уверен, у Nvidia неплохие шансы пободаться и с этим гигантом.
Возможно, кто-то спросит "Аффтар, почему ты так уверено назвал Nvidia главной компанией нашего будущего?". Отвечу: "Потому что Nvidia продает те самые пресловутые лопаты современным золотоискателям. А это самая надежная и устойчивая бизнес-стратегия независимо от эпохи и контекста".
Ладно, к делу. Изучая материалы про Nvidia, я регулярно сталкивался со следующим лейтмотивом:
"Да просто чуваки каждый раз оказывались вовремя с востребованным продуктом. Они просто крайне везучие".
Так вот, если компания умудряется несколько раз подряд оказаться с востребованным продуктом (причем, самым популярным на рынке, или одним из самых) в нужные моменты времени, то это означает, что у компании офигеть какая мощная стратегия, а СЕО - крутой визионер.
Поэтому, в этом материале я хочу не просто рассказать историю развития компании и основные этапы её развития. Но также понять, как Дженсену и ко. удавалось делать настолько верные и точные стратегические ставки. А еще, по ходу дела расскажу, что же за продукцию такую производит эта Nvidia, что на неё всегда есть устойчивый спрос в самых разных индустриях и сегментах рынка.
Disclaimer. История Nvidia - это большой и яркий путь с россыпью крутых бизнес-решений. Так что, я поделю материал на две части. Сегодня расскажу, как из небольшого перспективного "стартапа из кафешки" Nvidia превратилась в важнейшего производителя железа для современной технологических отраслей. А во второй части (coming soon) мы разберемся, как Nvidia из просто крупной и важного игрока превратилась в главную компанию будущего, которая (очень возможно), скоро станет самой дорогой корпорацией в истории.
Этап первый. Как жизнь Nvidia чуть не закончилась после первого же выпущенного чипа
Думаю, многие из вас слышали историю, как Дженсен Хуанг, Крис Малаховски и Кертис Прэм сели за столик в дешевой кафешке в Сан-Хосе и стали думать, какая технология станет the next big thing в этом мире. Еще ходит байка, что эта забегаловка была в таком суровом районе, что в её стенах зияли дырки от гангстерских пуль.
Последний факт, наверно, должен был символизировать стартаперский дух начинания, но на самом деле все трое фаундеров на тот момент уже были состоявшимися взрослыми спецами. Например, наш главный герой трудился руководителем направления в LSI Logic - довольно крупном производителе интегральных схем, а два других партнера инженерили в Sun Microsystems (эту компанию позже поглотит Oracle). В общем, ребята были весьма матерыми профи, а не какими-то оборванцами, бросившими колледж ради стартапа в гараже.
Приятели сходились во мнении, что компьютерная отрасль только набирает обороты, и что в самое ближайшее время машины будут использоваться для все более широкого спектра вычислительных задач. А значит, центральным процессорам (CPU) явно понадобится помощь. Эта помощь называется аппаратное ускорение вычисления.
В двух словах. CPU - это такой "мозг компьютера". Он обрабатывает сигналы и распределяет вычислительные команды. А теперь представьте, что вам на работе подкинули 10-20 задач одновременно. Что случится с вашим мозгом? Правильно, он "перегреется" и вы поймаете мощный приступ прокрастинации (=зависнете). То же самое и с центральным процессором компьютера, который должен выполнять все больше и больше задач одновременно.
Так вот, элементы аппаратного ускорения - это такие вспомогательные мини-мозги, призванные разгрузить основной мыслительный центр.
Без этих штук мы едва бы смогли параллельно запустить на ноутбуке несколько вкладок браузера, эксель, фотошоп, Телегу, и игру в отдельном окошке.
Кстати, на счет игр. Дженсен, Крис и Кертис не сомневались, что за аппаратным ускорением будущее. Оставалось лишь выбрать направление внутри этого тренда. Решили, что это будет гейминг. Если конкретнее, то их особенно привлекала бурно развивающаяся 3D-графика для этого самого гейминга. Продвинутый графон - это штука энергозатратная, вычислительные мощности она жрет как конь. Так что, друзья решили софкусироваться на графических процессорах (GPU).
В 1995 г. Nvidia выпустила свой первый продукт - мультимедийную видеокарту NV1.
Вот так она выглядела.
NV1 отличалась от аналогов тем, что на одной плате размещалось сразу несколько модулей - блок обработи 2D-графики, ускоритель 3D-графики, звуковая карта и порт для игрового геймпада приставки Sega Saturn. Кстати, в рамках этой карты Nvidia сотрудничала с Sega, что позволило портировать некоторые популярные эксклюзивы для этой консоли на ПК.
Нужно отметить, что Nvidia - это fabless (=fabricless) company, т.е. компания без своего производства. По сути, это просто конструкторское бюро. Очень большое и крутое конструкторское бюро! Они всего лишь (ну, если сравнивать с полноценной сборкой) придумывают и разрабатывают свои технологии и продукты, а непосредственной изготовкой занимаются подрядчики по контракту. Например, первый чип NV1 для Nvidia производила компания SGS Thomson-Microelectronics на своем заводе во Франции. Сейчас, конечно, у Nvidia есть кое-какие собственные производственные мощности, но львиная доля производства все равно происходит на стороне - например, с помощью тайваньских компаний.
В итоге NV1 стал прорывом и принес компании известность... хотелось бы мне написать. Но нет, он провалился! Да-да, история третьей по стоимости компании в мире началась с провала.
Дело в том, что NV1 был больше всего заточен на игровую консоль Sega. А в те годы происходит бум ПК-гейминга. Большинство ПК же работает на операционной системе Microsoft. NV1 вышел в мае 1995, а уже в сентября Microsoft представил свой API под названием DirectX.
Если упрощенно, DirectX - это специальный модуль, позволяющий разработчикам задействовать все мощности железа без написания специального кода под каждый элемент комплектующих.
Помните, большинство игрух на ПК в конце 1990-х и начале 2000-х требовали вместе с установкой самой игры поставить DirectX?
Так вот, принцип ускорения графики у чипсета NV1 принципиально расходился с таковым у DirectX. Следовательно, первый продукт Nvidia оказался принипицально несовместим с подавляющим большинством игр, которые геймеры ставили на ПК!
А учитывая, что в создание NV1 стартап бахнул почти все первые привлеченные инвестиции (первый раунд был 10 миллионов долларов - довольно серьезная сумма по тем временам), это был epic fail. Хуангу даже пришлось сократить половину сотрудников, которых к тому моменту уже успели нанять... Был момент, когда у Nvidia хватало денег всего лишь на один месяц зарплат. Тогда родился негласный девиз компании: "У нас есть всего лишь 30 дней, чтобы продолжать делать бизнес".
Так что, да, в начале своего пути сооснователи получили довольно мощный апперкот от жестоких реалий рыночной экономики.
Впрочем, Nvidia сделала правильные выводы. С пор они редко промахивались с трендами рынка, особенно в сегменте ПК.
Интересный факт. Первые годы у Nvidia не было названия. В рабочих переписках компания называла свои первые продукты "NV" - Next Version. Ну типа, новая версия этих ваших видеокарт. Когда компания развилась до такого масштаба, что без названия уже было сложно, основатели решили открыть словарь и найти что-то прикольное из похожего на NV. В итоге остановились на слове "'invidia"', что на латыни значит... "зависть". Да-да, тот самый дух неуёмной конкурентной борьбы, который позже проявился в схватках с 3dfx, ATI, AMD и другими крутыми компаниями.
Этап второй. Первый большой успех и победа над Voodoo
Есть такой миф, что Nvidia придумала видеокарты. На самом деле, это не так. Первый графический видеоадаптеры с поддержкой 3D-графики еще в бородатом 1982 году запилила IBM. Чуть позже многие другие компании выпустили свои версии. Однако первые версии были очень дорогими и не слишком производительными. В общем, узкоспециализированная история для избранных.
Действительно массовые, доступные, универсальные и широкосовместимые 3D-видеокарты появились во второй половине девяностых. Первый образец выпустила та же IBM в 1995 г., был еще чипсет S3 ViRGE от компании S3 Graphics (сейчас принадлежит тайваньской HTC). Еще было сразу несколько популярных моделей от компании Matrox, да и японцы из Yamaha тоже что-то делали... В общем, хотя океан еще не был алым, он уже стремительно краснел.
В 1996 г. на рынок выбрасывается сразу несколько успешных моделей, но настоящий прорыв происходит, когда компания 3dfx выпускает свой 3D-ускоритель под названием Voodoo Graphics.
3dfx специализировалась на графике для игровых автоматов, и их чип выдавал скорость и качество рендера, близкое к автоматам. Тогда это была вершина крутости. К тому же, их карты хорошо совмещались с ПК-играми.
Справа - графон в Quake 1 на чипсете Voodoo, слева - без оного. Как говорится, почувствуйте разницу.
Короче говоря, это был очень крутой 3D-ускоритель, который быстро завоевал популярность. Сначала среди производителей видеокарт, а позже и среди геймдев-компаний, которые целенаправленно начали оптимизировать графон своих проектов под него.
В 1998 г. 3dfx выпустила чипсет Voodoo2, который был еще производительнее первой версии. И вот с этой штукой Nvidia пришлось конкурировать. Скажу сразу, Nvidia выиграла, а позже вообще выкупила 3dfx, интегрировав к себе их наработки. Как же им это удалось?
Если вычленять самую суть, то более массовый и простой продукт победил более продвинутый. В общем, классика. Voodoo2 показывал исключительную производительность и качество текстур, к которым не могли приблизиться конкуренты. Однако Nvidia выпустил свой новый продукт - NV4, также известный как Riva TNT. Дело в том, что поверх набора ускорителей Voodoo2 нужно было отдельно прикрутить внешнюю видеокарту. А Riva TNT имела изначально встроенную видеокарту внутри своего набора (т.е. предлагала готовое решение под ключ). К тому же, Riva TNT была банально дешевле ("дешевые карты Nvidia" сейчас звучит как плохой анекдот, но тогда реально было так). Так что, Nvidia начал активно отжирать бюджетный и средний сегменты, которые благодаря растущей доступности 3D-игр росли быстрее всего.
Тем не менее, Nvidia и 3dfx активно конкурировали следующие 2-3 года. Но Дженсен Хуанг победил. Во-первых, пока у 3dfx каждый следующий чипсеть был масштабным мегапроектом, Nvidia намеренно минимизировал цикл разработки, научившись быстро выкатывать новые версии на рынок. Это позволяло еще быстрее отжимать бюджетный и средний сегмент. К тому же, Nvidia изначально заложила в конструкцию своих продуктов систему проверки чипов на брак, за счет чего у них была ниже доля неисправной продукции.
Закончилось все тем, что в 2002 г. 3dfx проиграла Дженсену Хуангу патентный спор, что окончательно добило некогда мощного игрока. В итоге Nvidia выкупила своего закадычного конкурента за 70 миллионов долларов. Первый громкий триумф.
В 1999 г. компания выпустила один из своих главных продуктов - GeForce 256, который Nvidia с гордостью называла "первым графическим процессором". На самом деле, это было не совсем так. Хотя GeForce 256 умел создавать более сложные и реалистичные трехмерные объекты за счет наложения структур, был способен обрабатывать солидный объем графических примитивов (примитивы - это простейшие объекты, из которых на экране складывается изображение), и вообще очень резво работал с графикой, он точно не был первым графическим процессором. Более того, он был даже не самым мощным в свое время. Однако, он точно выдавал оптимальную "цену-качество", а еще Nvidia весьма талантливо его пиарила (в хорошем смысле этого слова).
GeForce 256. Как говорится, найдите 10 отличий с фото NV1 выше. Но на самом деле, разница примерно как между Nokia 3310 и пятым (ну ладно, четвертым) Айфоном.
К тому моменту Nvidia уже стала крупным поставщиком графических ускорителей и видеокарт. Её выручка была в районе 200 миллионов в год, капитализация достигала 700 млн долл., а в 1999 г. компания провела IPO на NASDAQ, окончательно перестав быть стартапом.
Этап третий. Новая конкуренция на зрелом рынке
В начале 2000-х на рынке графических процессоров уже миновал этап бешеной конкуренции между кучей стартапов. Сформировались три явных лидера - Nvidia, Intel и ATI. У Nvidia и Intel было примерно по 30% рынка, у ATI - чуть меньше. Однако в 1998 г. Intel выпустил неудачный внешний ускоритель i740, так что, через некоторое время решил забить на рынок дискретных (т.е. внешних) видеокарт, состредоточившись на внутренней графике, а также других направлениях, коих у этого диверсифицированного гиганта было предостаточно.
В итоге в сегменте внешних графических модулей образовалась дуополия - Nvidia против ATI. Тут-то Дженсен Хуанг и попал в свою любимую среду ультраконкуренции. В 2000 г. ATI как раз выпустила свой самый жирный продукт, название которого вы наверняка слышали - это чипсет Radeon (сейчас это флагман компании AMD, но об этом позже).
В общем, две компании начали бодаться за самые жирные сегменты и контракты.
Сначала Nvidia стала поставщиком чипов для консоли Xbox, которую только-только начинал развивать Microsoft. Однако в дальнейшем Microsoft ушел к конкурентам из ATI. Дженсен Хуанг подумал "А чем я хуже?", и пошел к Sony с их PlayStation. Вдобавок, Nvidia стала эксклюзивным поставщиком внешних видеокарт для компов Apple. Кстати, в рамках партнерства с Sony Хуанг поступил очень мудро - Nvidia не просто продавала свои чипы, но и помогала Sony разрабатывать собственную графику для PlayStation 3 и PSP. Конечно, в перспективе Sony мог полностью перейти на свои решения, но глава Nvidia понимал, что рано или поздно это случится в любом случае (так и случилось). Так что, лучше поучаствовать в процессе, выжав из сотрудничества максимум хотя бы до создания японцами своего GPU.
Параллельно, Nvidia начала себя вести как настоящая взрослая корпорация. Она начала скупать перспективные компании и стартапы, диверсифицируя технологическую и продуктовую базу. В частности, прикупили:
Exluna - разработчика оборудования для 3D-рендеров в кино.
MediaQ - производителя чипов, которые оптимизируют работу дисплеев и аккумуляторов мобильных телефонов и прочих "беспроводных устройств".
iReady - разработчика чипов, которые "разгружали мозги" сетевого адаптера (это штука внутри компьютера, с помощью которой он ловит сеть или вайфай).
А еще, что любопытно, в 2005 г. хитрая Nvidia купила некую тайваньскую компанию ULI Electronics (сейчас она называется чуть по-другому), которая была важным поставщиком компонентов для главного конкурента - ATI. Этот удар Хуанга был крайне чувствительным для конкурента.
Второй удар по себе нанесла сама ATI. Компания продалась диверсифицированному производителю микропроцессоров AMD. В итоге ATI стала "графическим юнитом" в составе AMD, при этом лишившись большинства контрактов со своим основным потребителем - Intel (ведь AMD - это уже прямой конкурент Intel, а не какой-то там поставщик графических чипов). Угадайте, кому после этого достались безхозные контракты от Intel?
В итоге получилась очень характерная ситуация. С одной стороны, огромный процессорный холдинг купил главного конкурента Nvidia (а также, соответственно, их главный продукт - чип Radeon). С другой стороны, сама Nvidia активно диверсифицировалась, скупала компании в смежных сегментах и готовилась играть по-крупному. Все это предзнаменовало главное противостояние в сегменте графики, рендеров, процессоров и всего что с этим связано - Nvidia vs AMD ("зеленые" против "красных").
Классическое противостояние, которое идет уже почти 20 лет. Иногда еще сюда добавляют Intel, но Intel - это все же прямой конкурент для AMD. Для Nvidia Intel и конкурент, и партнер и покупатель одновременно.
Кстати, есть версия, что AMD сначала хотели купить Nvidia, но Дженсен Хуанг их послал. Этот хитрый CEO что-то знал уже тогда.
Этап четвертый. Первые ростки в направлении ИИ
Середина 2000-х. Nvidia - уже совсем серьезная корпорация, зарабатывающая по 200-300 миллионов баксов за квартал.
В 2007 г. компания выпускает свой, возможно, самый важный продукт. Очень вероятно, что именно он открыл ей путь к нынешним триллионам. Он назывался CUDA (Compute Unified Device Architecture). CUDA - это GPGPU (General-purpose computing on graphics processing units). И здесь я остановлюсь подробнее.
Дженсен Хуанг понимал, что одними ускорениями графона и рендерами сыт не будешь. Так что, Nvidia выпустил, скажем так, адаптер (ну или прееходник), который позволял задействовать мощности большинства своих графическиих чипов для обработки математических вычислений, алгоритмов и прочих веселых штук, которыми занимаются разработчики самых продвинутых технологий.
Проще говоря, с помощью CUDA разрабы смогли делать запросы на упрощенных диалектах языков C, С++ и Fortran, которые обрабатывались прямо на мощностях чипов Nvidia. Позже прикрутили еще Python, MATLAB и другие популярные языки.
Отдельно выделю крайне удачное решение добавить язык Fortran. С одной стороны, этот язык сложно назвать самым популярным для разработки (видели хоть один войтивайтишный курс про Фортран?). С другой стороны, он считается "высоким языком", на котором программисты-ученые любят вести научные изыскания. В том числе, именно Fortran стал одним из ключевых языков для ранних наработок в области искусственного интеллекта и машинного обучения (есть версия, что это вообще первый язык для ИИ).
Таким образом, помимо очевидного стимулирования спроса на чипы, успешный выпуск CUDA, вероятно, стал фундаментом (или хотя бы первым кирпичиком) для лидерства компания в вычислительных мощностях для искусственного интеллекта.
Интересный факт. В 2012 г. прошел ImageNet Large Scale Visual Recognition Challenge - крупный конкурс, где разработчики соревновались, чья технология круче всех распознает разные картинки. Лучший результат показала нейронная модель AlexNet, которая обучалась через мощности графических чипов Nvidia с помощью CUDA. Тогда окончательно стало ясно, что графические чипы в целом и Nvidia в частности ой как пошумят по мере развития ИИ. Кстати, одним из создателей AlexNet был Илья Сутцкевер, который теперь нам известен как сооснователь OpenAI и один из самых важных людей в мире современных технологий.
Молодые Илья Сутцкевер и Алекс Крижевский, а также уже солидный Джеффри Хинтон (один из самых видных ученых в области deep learning) работают над AlexNet.
Этап пятый. Новые вызовы и работа с рисками
В конце 2000-х Nvidia продолжила усиленную диверсификацию. В частности, был куплен Ageia - разработчик движка PhysX, который позволяет моделировать и разрабатывать симуляции физических явлений. PhysX - крайне важная штука для гейминга, которую активно используют Unreal Engine, Unity и другие игровые движки. Он стал весьма важным продуктом для компании.
Однако, к началу 2010-х перед Nvidia встал серьезный вызов - стремительно набирал обороты сегмент интегрированной (внутренней) графики. Это означало, что диверсифицированный крупняк вроде Intel, Sony, Microsoft, Apple и прочих становились гораздо более самостоятельными в плане работе с графическими задачами. Если в 2007 г. Intel контролировал 30% рынка графики, то к началу 2010-х - уже более половины, и продолжал усиливать свои позиции за счет поглощения целой россыпи мелких производителей.
Позиции основного бизнеса Nvidia (дискретных, т.е. "встраиваемых", решений для графики) оказались под серьезной угрозой. К тому же, в 2008 г. Nvidia выпустила большую партию чипов с дефектами, которые отгрузили Apple, Dell, HP и другим крупным ребятам. В итоге Nvidia получила серьезный репутационный ущерб, а еще пришлось раскошелиться на компенсации.
Нужно было что-то менять. В первую очередь - еще активнее диверсифицироваться, чтобы сделать бизнес-модель прочной и устойчивой.
Действовать решили по всем фронтам:
Радикально усилили чипы и прочие вычислительные продукты для игр на ПК и консоли.
Активно пошли в мобильный сегмент. Еще в 2007 г. Nvidia купила разработчика системных чипов PortalPlayer. В 2010-х на основе технологий PortalPlayer была выпущена серия процессоров (не GPU, а полноценных CPU) для мобильных устройств под названием Tegra (их еще называют "кристаллы"). Правда, на мой взгляд, Nvidia слегка промахнулась с операционной системой, ведь большинство Tegra применялось в смарфтонах и планшетах на Windows. Впрочем, это сейчас мы видим, что мобильные потуги Microsoft оказались провалом, а в начале 2010-х это была весьма перспективная история с неплохой долей рынка. Так что, бизнес Nvidia неплохо на этом вырос. Даже CEO Microsoft Сатья Наделла недавно признавался, что сворачивание мобильного бизнеса Microsoft было главной стратегической ошибкой компании.
Nvidia даже отважилась на нетипичный для себя эксперимент - выпустила собственную портативную игровую консоль Nvidia Shield Portable:
Заряженная тем самым процессором Tegra. Работала на ОС Windows.
Вообще, консоль Shield - это крайне нетипичный продукт для Nvidia. Компания всегда отличалась высокой прагматичностью при выборе конфигурации продуктов и оценке будущего спроса, всегда стараясь сделать относительно доступный продукт, который найдет отклик у массовой аудитории. Но тут получилось с точностью до наоборот. Shield стоила дороже аналогов, а игр для неё было крайне мало (хотя Nvidia даже запилила собственную платформу для разработки). Так что, хотя эксперты и игровые издания хвалили консоль за весьма недурную графику и производительность, особой популярности продукт не сыскал. Что ж, видимо, если умеешь производить чипы и процессоры, то не стоит лезть в истории про платформы и пользовательские девайсы.
Еще Nvidia начал активничать в сегменте автомобильной электроники. В том числе, в области начинки для беспилотного управления.
Но про это я расскажу во второй части. Как и про конкуренцию с AMD, качели из-за криптомайнинга, партнерства с китайцами и, собственно, путь к триллионной капитализации за счет лидерства в ИИ в последние годы. Там много интересных историй. А на сегодня хватит.
Если эта статья круто зайдет, то я быстрее сяду за вторую часть. Так что, если вам понравилось, то можете подкинуть мне дополнительной мотивации в виде плюсов, комментов и репостов статьи друзьям.
Если вам заходит такой контент, то подпишитесь на мои тг-каналы. Мне будет приятно, а вы найдете там еще больше подобного:
На своем основном канале Дизраптор я простым человечьим языком разбираю инновации, технологические продукты и знаковые компании (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили).
А на втором канале под названием Фичизм более точечно пишу про новые фичи и функции продвинутых компаний и сервисов.
Их есть у нас! Красивая карта, целых три уровня и много жителей, которых надо осчастливить быстрым интернетом. Для этого придется немножко подумать, но оно того стоит: ведь тем, кто дойдет до конца, выдадим красивую награду в профиль!
Генеративные нейросети любят ловить глюки и выдавать всякую чушь. Причем так массово, что Кембриджский словарь признал «галлюцинировать» главным словом 2023 года. В чем причина этой проблемы? Является ли генеративный ИИ интеллектом? И что общего у ChatGPT и копировального аппарата Xerox? Разбираемся, попутно разрушая мифы про этот наш вездесущий искусственный интеллект.
"ChatGPT заменит поисковики", - говорили они.
Небольшое вступление или "в чем суть проблемы?"
Авторитетный Кебриджский словарь признал словом года «галлюцинировать» (hallucinate). Причем не в вакууме, а применительно к генеративному ИИ. Глюки ИИ — это когда ChatGPT выдает косяки в фактологии, из‑за которых пользователи теряют всякую веру его результатам (и срочно бегут все перепроверять в Гугле). Но не стоит злиться на генеративный ИИ за подобные выкрутасы, ведь дело в самой логике его работы. Ее мы сегодня и разберем с помощью парочки метких аналогий.
Год назад Google впервые представил миру своего чат‑бота Bard. Сейчас он вполне неплохо работает (хотя и уступает первопроходцу), но на той презентации умудрился выдать базу‑основу. Он заявил, что «Джеймс Уэбб» был первым космическим телескопом, сделавшим снимки планет за пределами Солнечной системы. Это была ошибка — первые снимки этих самых планет сделал другой телескоп еще за 17 лет до появления на свет «Джеймса Уэбба». Неточность Барда быстро заметили, в результате чего у Google даже просела стоимость акций.
ИИ чат‑боты регулярно выдают неточности и искажения. Чаще всего они незначительны и касаются отдельных деталей. Однако даже наличие небольших косяков сильно снижает полезность генеративного ИИ на практике. Ведь если вы знаете, что ошибки в целом возможны и даже регулярны, то не можете полностью довериться этому инструменту.
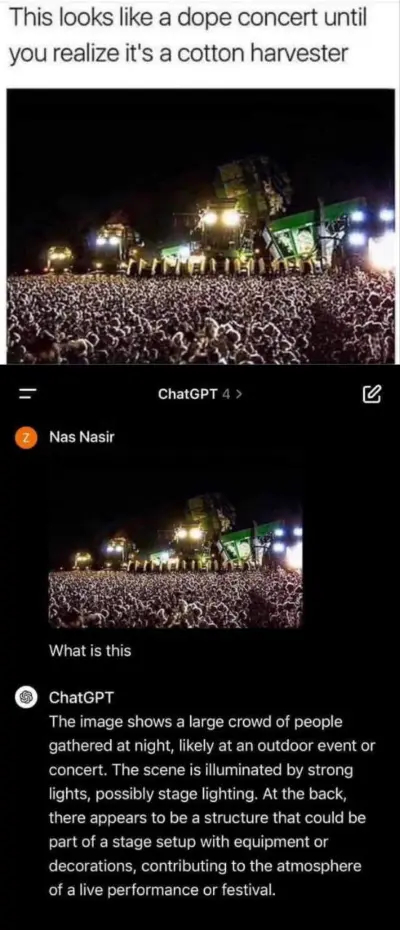
Сферические глюки ИИ в вакууме. Да-да, ChatGPT, конечно же это мероприятие или концерт. День хлопка на плантации отмечают, не иначе. А впрочем, не каждый человек справился бы лучше.
Но не спешите обвинять бездушную машину в злом умысле. У нее нет цели подставить кожаных или намеренно ввести в заблуждение.
Причина в другом. Дело в том, что генеративный ИИ по принципам своего устройства больше напоминает архиватор (т. е. программу для сжатия файлов), нежели полноценное сознание. Именно поэтому эксперты в ИИ зачастую недовольно фыркают, когда генеративные нейросети называют звучным словом «интеллект». А еще это отлично объясняет, почему ChatGPT очень вряд ли превратится в злой скайнет (но это не точно).
Итак, давайте разбираться. В этом нам поможет классная статья издания The New Yorker за авторством Теда Чана, из которой я с большой благодарностью буду заимствовать ключевые тезисы. Подкрепляя их иллюстрациями, дабы нагляднее было.
Хитрый Xerox и внимательные немецкие архитекторы
Осмыслять проблему удобнее чуть издалека, с интересной аналогии.
В 2013 году копировальный аппатар Xerox в офисе одной немецкой строительной фирмы начал творить очень странные дела. Ребята делали копию проекта дома с тремя комнатами и заметили очень любопытное расхождение:
На оригинальной схеме три команты имели разную площадь — 14.13, 21.11 и 17.42 метра. То есть, на чертеже в центре каждой комнаты стояла разная циферка, обозначающая площадь.
Xerox же выдал копию, где на всех трех комнатах стояла одинаковая цифра — 14.13 (как площадь первой комнаты).
Компания прифигела от такого контринтуитивного глюка копировальной техники и обратилась к специалисту по обработке данных Давиду Крайзелю.
Вы, возможно, спросите: «Аффтар, а почему они обратились к человеку такой специальности, а не к эксперту в копировальном деле?». Дело в том, что современные ксероксы используют не классический процесс ксерографии (это когда изображения передаются с оригинала на копию через прохождение лучей через специальный барабан — в общем, аналоговая классика), а цифровое сканирование.
А когда речь заходит о каких‑то манипуляциях с изображениями (да и файлами в целом) в цифровой среде, то мы почти наверняка столкнемся с процедурой сжатия объектов.
Процедура сжатия состоит из двух ключевых этапов. Первый — кодирование (encoding), в ходе которого изначальное изображение переводится в какой‑то более компактный формат. Второй — декодирование (decoding), т. е. обратное действие.
При этом сжатие бывает двух типов:
Сжатие без потерь (lossless) — это когда закодированные данные могут быть восстановлены с точностью до пикселя или бита. Если речь идет про изображения, то самый популярный формат сжатия без потерь — это PNG.
Сжатие с потерями (lossy) — здесь уже распакованные данные отличаются от исходных, но степень отличия столь незначительно и минорна, что их без проблем можно дальше использовать. Яркий пример — JPEG.
Чоткие пацаны не забивают карту памяти своего Сименса пээнгэшками!
Сжатие без потерь обычно используется, скажем, для компьютерных программ. Потому что если потерять хотя бы один символ кода, то все поломается. А вот для изображений, аудио или видеофайлов часто предпочитают использовать сжатие с потерями. Ведь даже если отдельные пиксели картинки поедут или мелодия будет звучать чуть менее чисто, то человечьи органы осязания все равно не заметят подлога, так что пофиг.
Здесь и была зарыта собака в истории со ксероксом. Агрегат использовал lossy‑сжатие формата JBIG2, которое работает примерно так:
В целях экономии места или вычислительных мощностей (а может и того и другого, пойди разберись в этой офисной технике) машина ищет очень похожие области изображения и сохраняет для всех них одну копию, которую потом воспроизводит обратно при декодинге.
Проще говоря, конкретно в этом случае ксерокс почему‑то решил, что комнаты на чертеже так похожи друг на друга, что можно смело забивать на различия и считывать только одну из них — ту, которая площадью 14,13 кв метров. А потом везде нарисовать именно её. То ли потому что формат JBIG2 создан для работы с черно‑белыми офисными бумажками, а не с мелкими объектами чертежей, то ли просто у аппарата был дурной характер — история умалчивает. Но суть в том, что ксерокс решил забить на небольшие различия именно в том случае, где эти различия оказались очень даже критичными.
Вообще, сам факт того, что ксерокс использует сжатие с потерями — это не проблема. Проблема в том, что изображение деградирует очень незначительно, «на тоненького». Настолько чуть‑чуть, что с ходу фиг заметишь. Одно дело, если бы он просто блюррил упрощенные области картинки, но он их может просто вероломно заменить. А строительному бюро потом объясняй заказчику, почему в итоге все комнаты получились одинаковыми.
Идем дальше. Проблема сжатой Википедии
Запомним историю со Xerox и проведем один мысленный эксперимент (он нам нужен, чтобы подойти еще ближе к пониманию проблемы этих наших GPT).
Представьте, что завтра во всем мире отключат интернет. Вообще. Совсем. Не будет его больше. В связи с этим мы решаем по максимуму выгрузить все содержимое интернета к себе на частный сервер. Ну окей, пусть будет не весь интернет (это совсем тяжко), но хотя бы всю Википедию. Чтобы оставить великие знания потомкам.
Разумеется, место на сервера ограничено — вся Википедия туда не влезет. Допустим, места хватит на 1% от оригинального размера, т. е. сжать изначальный объем нужно в 100 раз. Следовательно, нужно прибегнуть к сжатию с потерями.
Печатать всю Википедию мы, пожалуй, не будем. Это too much даже для гипотетического мысленного эксперимента. Обойдемся цифровым форматом.
Итак, мы применяем сжатие с потерями. Алгоритм у нас мощный — он легко находит чрезвычайно тонкие статистические закономерности на совершенно разных страницах (иногда одинаковыми оказываются длинные фразы или целые предложения). Таким образом нам удается сжать Википедию примерно в 100 раз, что и требовалось в нашем мысленном эксперименте.
Теперь нам не так страшно потерять доступ к интернету, ведь у нас как минимум выкачана база знаний в виде Википедии (а значит, потомкам будет чуть проще делать выводы о предназначении предметов, найденных при раскопках через тысячи лет). Но есть нюанс:
Мы не сможем найти любую цитату слово в слово. Потому что из‑за сжатия с потерями наша Википедия сохранена не буквально, а приблизительно. Алгоритм оставил только то, что кровь из носу требуется, чтобы сохранить смысл всех сущностей. Остальное же было объединено и апроксимировано (т. е. передано приблизительно). А значит, чтобы достать информацию, нам нужно создать интерфейс, который умеет в ответ за запрос выдавать основной смысл.
Чувствуете, на этом моменте комнату начинает наполнять знакомый аромат генеративного ИИ?
GPT выдает точные ответы, но есть нюанс...
Да‑да, только что мы мысленно создали большую языковую модель (LLM), обученную на Википедии (в нашем конкретном случае).
ChatGPT — это заблюренный JPEG не только Википедии, но вообще всего интернета. Когда модель дообучают, этот JPEG еще лучше детализируется в отдельных уголках. Но суть все та же — LLM аккумулирует именно бОльшую часть интернета, но далеку не всю.
Следовательно, когда GPT отвечает за ваш запрос, он не может выдать точную последовательность символов. Он сделает приближение. Другое дело, что GPT отлично умеет превращать это приближение в связный и опрятный текст, который человеческий мозг не может сходу отличить от оригинального.
А как LLM воссоздает пробелы, которые отсутствуют в его сжатой версии интернета? Ответ — интерполяция. Не будем вдаваться в математические дебри этой штуки. Простыми словами — это оценка отсутствующего элемента путем анализа того, что находится с двух сторон от этого разрыва. Когда программа обработки изображений декодирует ранее сжатую фотографию и должна восстановить пиксель, потерянный в процессе сжатия, она просматривает близлежащие пиксели и, по сути, вычисляет среднее (генерирует его).
То же самое делает ChatGPT, только со словами и прочими текстовыми смысловыми сущностями. Секрет в том, что ChatGPT научился делать эту интерполяцию настолько мастерски, что люди не могут этого раскусить (и думают, что имеют дело с настоящим интеллектом).
По сути, генеративный ИИ выдумывает отсутствующие элементы на основе смежных. Фантазер этот GPT, получается.
Если теперь вы хотя бы иногда будете вспоминать эту картинку во время написания очередного промпта, то это значит, что я написал эту статью не напрасно :)
Описанная выше логика отлично объясняет «галлюцинации». Просто‑напросто даже самый большой мастер интерполяции иногда допускает ошибки. И совсем периодически эти ошибки замечают. Однако сам факт вероятности ошибок сильно снижает надежность инструмента. Ведь это значит, что в любой момент может вылезти значимый косяк. А это уже означает, что все результаты нужно сверять с оригинальным текстом (= лишние затраты ресурсов).
Получается, генеративный ИИ - это совсем не интеллект?
И да, и нет. Тут, как говорится, смотря как посмотреть.
Действительно, не стоит очеловечивать генеративный ИИ. То есть не нужно отождествлять его с человеческим интеллектом.
ChatGPT впитывает информацию с большими потерями, восстанавливая ее через интерполяцию. В результате он как будто пересказывает суть своими словами. Вероятно, здесь и кроется разгадка, почему люди так восхищаются генеративным ИИ.
Дело в том, что еще со школьных и универских скамей у людей сидит на подкорке убеждение (весьма резонное), что точное воспроизведение информации — удел зубрилок, которые «выучили, но не поняли», а по‑настоящему толковые ребята пересказывают все своими словами, сохраняя суть. Поэтому и ChatGPT нам кажется толковым парнем, который реально все понимает. На самом же деле он просто передает основной смысл, воссоздавая пропуски за счет усреднения.
Именно поэтому, кстати, GPT3 не очень хорошо справлялся с точными вычислениями больших чисел (допустим, выражение «2345 х 57789» в интернете встретишь не так уж часто), но при этом как Боженька писал всякие студенческие эссе. По мере перехода к GPT4 модель стала более продвинутой, в нее завезли больше закономерностей, поэтому она стала сносно щелкать любую арифметику.
Однако, есть и другая сторона медали. Она касается тех самых закономерностей, которых в GPT4 завезли больше. Смотрите:
Есть такая премия под названием «Приз Хаттера». Ее в 2006 г. учредил старший научный сотрудник DeepMind (это ИИ‑стартап, уже давно купленный Гуглом) Маркус Хаттер. Суть конкурса такая:
Есть текстовый файл на английском языке размером 1 Гб. Его требуется сжать без потерь. Каждый, кто сожмет на 1% от предыдущего лучшего результат, получит 5000 евро. Сейчас лучший результат 115 Мб.
На самом деле, это не просто конкурс по сжатию текста без потерь. Это важное упражнение, приближающее понимание сути настоящего ("взрослого") искусственного интеллекта. И вот этого товарища уже можно отождествлять с человеческим сознанием как минимум по одному признаку:
Чтобы наиболее эффективно сжимать текст без потерь, он должен уметь по-настоящему понимать этот текст и сопоставлять его содержание с реальными знаниями о мире.
Маркус Хаттер вскоре после запуска своего конкурса. Кстати, Лекс Фридман записывал с ним интервью еще три года назад. Рекомендую глянуть, если пропустили.
Например, вот есть у нас какая‑то статья в Википедии на тему физики. Допустим, некий текст, где фигурирует Второй закон Ньютона (Сила = Масса x Ускорение). Вероятно, самый простой способ сжать без потерь такую статью — это заложить в алгоритм сжатия базовый постулат, что «Сила = Масса x Ускорение». Тогда алгоритм может выкинуть повторящиеся куски статьи, вытекающие из логики этого закона, а потом легко их восстановить при надобности (потому что знает сам базовый принцип).
Аналогично и со статьей на некую экономическую тему. Наверняка там будет дофига выводов, основанных на законе спроса и предложения. А значит, если в принцип сжатия заложен этот закон, то можно выкинуть кучу «вторичной» информации.
ИИ работает так же. Чем больше первичных правил и законов он знает, тем меньше может париться с запоминанием вторичных выводов (ведь он может их легко восстановить — если и не дословно, то достаточно точно по смыслу).
При таком раскладе ИИ действительно становится интеллектом — в том плане, что делает частные выводы на основе общих знаний. По сути, старая добрая дедукция из детективных романов про Шерлока Холмса.
Всегда догадывался, что этот парень - искусственный интеллект.
Получается, что хотя ChatGPT все еще очень далек от настоящего интеллекта, он все сильнее стремится к таковому по мере наполнения своей базы знаний и лучшей адаптации к устройству нашего мира. Вот такой интересный процесс.
Получается, из-за глюков LLM-кам нельзя доверять так же, как поисковикам (как минимум пока они не усвоят все законы бытия)?
В целом, получается, что да. Пока что нельзя. Ведь:
Во‑первых, мы не знаем наверняка, скушала ли LLM откровенную пропаганду или какие‑нибудь антинаучные теории заговора. Если скушала, то она могла выстроить очень специфические логические связи. И если она будет заполнять пробелы в соответствии с ними, то результат может получиться очень веселым.
Во‑вторых, также нет гарантии, что ИИшный «JPEG» не заблюррил полностью ту информацию, которая нужна для отработки конретно нашего запроса.
Держа в голове эти два обстоятельства, можем сделать вывод — результаты нынешнего генеративного ИИ можно использовать как отправную точку для анализа, но не финальную истину (не стоит сразу же нести выводы от ИИ своему начальнику, ну вы поняли).
Также стоит разобраться — а хорошая ли это идея создавать контент с помощью ИИ?
Ну, если вы работает на объем, то наверно да. А если на качество и уникальность, то не уверен. Ведь даже если вы используете ИИ для получения некой первичной версии, то держите в уме, что холстом вашего великого произведения будет вторичный (изначально переработанный) продукт, где часть смыслов вообще фантазировалась через интерполяцию (иначе говоря — отправной точки ваших смыслов станет совсем уж откровенный полуфабрикат).
Так что, если вы хотите создавать уникальный контент — то, пожалуй, ИИ стоит использовать только для поиска информации, не более. Однако, если ваша задача переупаковать уже готовый контент — то почему бы нет? Особенно если вам нужно избавиться от оков авторских прав и копирайтов (рубрика «вредные советы»).
Выводы
Глюки ИИ — это норма. Иногда они кажутся нам смешными и чересчур упоротыми. Но объяснение лежит на поверхности.
По мере обрастания моделей закономерностями и знаниями о мире, глюков будет все меньше. Если, конечно, мир не будет усложняться с той же скоростью или быстрее.
Полезно учитывать эту особенность при использовании ИИ. Так будет меньше шансов серьезно опростоволоситься в кругу уважаемых людей или испортить качество выдаваемых смыслов.
Когда генеративный ИИ сможет стать Скайнетом? Учитывая вышысказанное, рискну предположить, что еще очень‑очень нескоро. Если вообще сможет.
После осмысления информации выше я теперь представляю Скайнет примерно так ("ути-пути какой хорошенький"). Надеюсь, меня за такое не прикончат первым...
Большая часть этой статьи — художественный перевод вот этой статьи. Очень‑очень вольный перевод — считайте, что я интерполировал кое‑какие смыслы, чтобы воспринимать их было проще и веселее. Статья вышла в феврале 2023, т. е. еще до релиза GPT4, но логику передает верно. Рекомендую прочитать оригинал, там еще больше примеров и иллюстраций (но предупреждаю — понадобится неплохой английский и ясное сознание).
Также рекомендую заглянуть на мой тг‑канал Дизраптор. Там я простым человечьим языком и с максимальной наглядностью пишу про разные интересные штуки из мира технологий, инноваций и бизнеса. В том числе про этот наш ИИ, но не только про него.
🧠В Нижегородском государственном университете сделали шаг к разработке нейроинтерфейса для ускорения реакций мозга. Глубокое машинное обучение поможет предсказывать ошибки человека и, отправляя импульсы в мозг, предотвращать их.
🔝Опубликован рейтинг топ-10 городов БРИКС. Москва лидирует по индексу технологического и пространственного развития, обходя Пекин, Шанхай, Сан-Паулу и Гуанчжоу.
Китайские учёные сообщили о создании технологии массового производства подложек с атомарно тонкими полупроводниковыми слоями. Новая технология масштабируется до производства 12-дюймовых (300-мм) подложек — самых массовых, продуктивных и наибольших по диаметру пластин для производства чипов. С такими пластинами транзисторы с затвором размером 1 нм и меньше станут реальностью, что продлит действие закона Мура и выведет электронику на новый уровень.
Современные технологии наращивания слоёв на подложках работают по принципу осаждения материала из точки распыления на поверхность. Для нанесения плёнок толщиной в один атом или около того на крупные пластины эта технология не предназначена. С её помощью можно инициировать рост равномерной по толщине плёнки только на небольшие пластины — примерно до 2 дюймов в диаметре. Для пластин большего диаметра и, тем более, для 300-мм подложек этот метод не годится.
В интервью изданию South China Morning Post профессор Пекинского университета Лю Кайхуи (Liu Kaihui) сообщил, что его группа разработала технологию производства атомарно тонких слоёв на любых подложках вплоть до 300-мм. В основе технологии лежит контактный метод выращивания плёнки с поверхности на поверхность. Активный материал входит в контакт с подложкой сразу по всей её поверхности, давая старт для роста плёнки равномерно во всех её точках. В зависимости от типа активного материала могут быть выращены плёнки нужного состава и даже множество плёнок друг на друге, если это потребуется.
Кроме того, учёные разработали проект установки для выращивания атомарно тонких плёнок в массовых объёмах. Согласно расчётам, одна такая установка может выпускать до 10 тыс. 300-мм подложек в год. Эта же технология подходит для покрытия подложек графеном, что позволит, наконец, внедрить этот интересный материал в массовое производство чипов.
Следует сказать, что учёные заглянули далеко вперёд. Сегодня 2D-материалы (толщиной в 1 атом) только исследуются на предмет использования в структурах 2D-транзисторов и в других качествах. До массового производства подобных решений ещё очень далеко, и предстоит провести много научной работы, пока она не воплотится в серийной продукции. Но это важнейшее направление, которое позволит совершить прорыв в производстве электроники и китайские производители внимательно следят за успехами своих учёных.
Выспаться, провести генеральную уборку, посмотреть все новые сериалы и позаниматься спортом. Потом расстроиться, что время прошло зря. Есть альтернатива: сесть за руль и махнуть в путешествие. Как минимум, его вы всегда будете вспоминать с улыбкой. Собрали несколько нестандартных маршрутов.
Физики утверждают, что аккумуляторы на основе ионов алюминия намного эффективнее и безопаснее для экологии, чем популярные сегодня литиевые батареи.
Прогресс невозможно остановить, и сегодня все мы зависим от батареек, нравится нам это или нет. Все, от смартфонов до автомобилей, требует для работы аккумулятор. Однако современные литий-ионные обладают рядом очевидных недостатков, но модернизированный тип алюминиевого аккумулятора во многом превосходит современный стандарт.
Основное преимущество алюминиевых аккумуляторов — это сравнительно низкие производственные затраты и использование материалов, которые в изобилии встречаются на нашей планете и при этом легко доступны. Это значит, что человеку не придется разрушать целые экосистемы и тратить огромные ресурсы на то, чтобы добыть материалы для их изготовления. В первую очередь этот концепт подходит для крупномасштабных энергосистем — например для районов, где существует возможность добывать энергию из возобновляемых источников и ее нужно где-то хранить.
Помимо дефицита лития, производители классических литий-ионных аккумуляторов также сталкиваются с проблемой использования кобальта, потенциально опасного для человека металла. Если у промышленников получится перейти на алюминий, то мы станем заметно меньше зависеть от ископаемого топлива, да и сам процесс производства и переработки батареек заметно упростится.
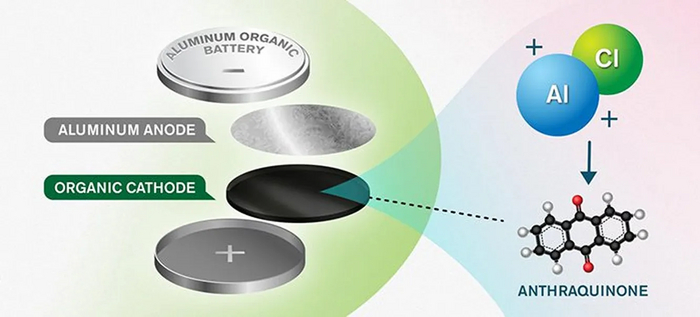
Схема алюминиевого аккумулятора Yen Strandqvist/Chalmers University of Technology
Физик Патрик Йоханссон из Технологического университета Чалмерса в Швеции также отметил, что аккумуляторы нового типа обладают удвоенной энергоемкостью в сравнении с теми видами алюминиевых батарей, что уже существуют на рынке. Сам по себе концепт не является новаторским, но если раньше в качестве катода использовался графит, то теперь его заменил антрахинон.
Впрочем, даже сами разработчики признают, что их изобретению есть куда развиваться. Особенно это касается электролита — химической смеси, которая и стимулирует движение ионов между катодом и анодом. По словам Йохансона, алюминий в принципе является лучшим носителем заряда, чем литий, поскольку он многовалентный и «каждый ион компенсирует несколько электронов».