И снова Пикабу образовательный
Сначала был мем:
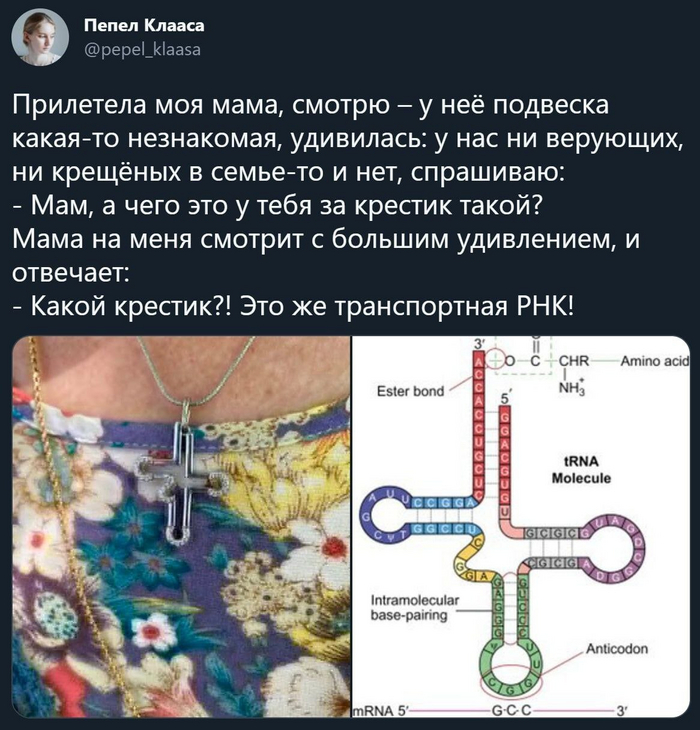
В комментариях всё разъяснили:

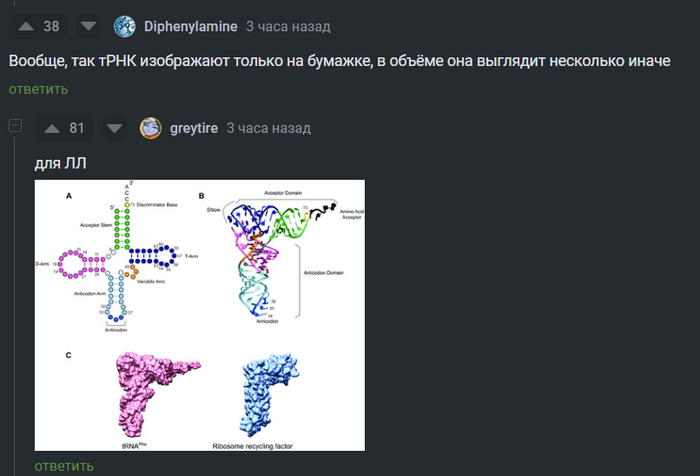
@Svinopot, @SingleGenome, @kostushka, @Diphenylamine, @greytire, @merhanum, вы в телевизоре :)
Показать полностью
5
Сначала был мем:
В комментариях всё разъяснили:
@Svinopot, @SingleGenome, @kostushka, @Diphenylamine, @greytire, @merhanum, вы в телевизоре :)
Синтез белка начинается с этапа Транскрипции, когда идёт считывание информации ДНК и построение комплеменнарной ей цепочки матричной или как её называют информационной РНК. Ну а дальше идёт Трансляция- когда рибосома считывает эту информацию с цепочки матричной РНК и преообразует в цепочку аминокислот: пептидов или белков.. . Это вкратце..
Представим если организм даёт сбои, какие то процессы нарушены, синтез нужного белка идет плохо, или в недостаточном количестве, или же речь идёт в нарушении цепочки ДНК. В этом случае возможно будет внедрять в клетки созданные, нужные цепочки матричного РНК, с которых и будут считывать рибосомы информацию для синтеза нужного белка.
Белковую природу имеют многие структуры организма, ферменты, гормоны, транспортные, структурные, сигнальный... Большинство процессов в организме осуществляются белками. Поэтому нельзя переоценить пользу данного метода.
Скорее это проще чем вырезать и встраивать новые гены в ДНК. Как бы действуя в обход ДНК и стадии Транскрипции.
Возможно таким образом можно будет и усовершенствовать организм, например отправляя в клетку мРНК которая улучшит состояние тканей, придаст им нужную фическую функцию ( прочность, эластичность, устойчивость к каким либо неблагоприятных условиям). Или например применить этот метод для улучшения иммунитета когда это нужно.
Возможно таким образом можно будет омолаживать клетки организма когда, с возрастом, функции синтеза нужныхбелков, каких-либо групп клеток будут нарушены....
Количество времени и денег, которые потребовались для секвенирования первого человеческого генома, проект которого был завершен в 2001 году. Сегодня секвенирование можно выполнить за считанные часы и менее чем за 1000 долларов.

Ну что, потренировались? А теперь пора браться за дело всерьез.
Фильм о принципах белковых взаимодействий. Показан опыт, доказывающий, что наследственную информацию несет ДНК. Знакомит со структурой РНК, сравниваются ДНК и РНК, отмечается роль информационной РНК.
Фильм очень старый, но очень полезный для общего представления о белковых структурах. Рассказано очень простым языком, будет понятен всем.
Фильм Учебный.
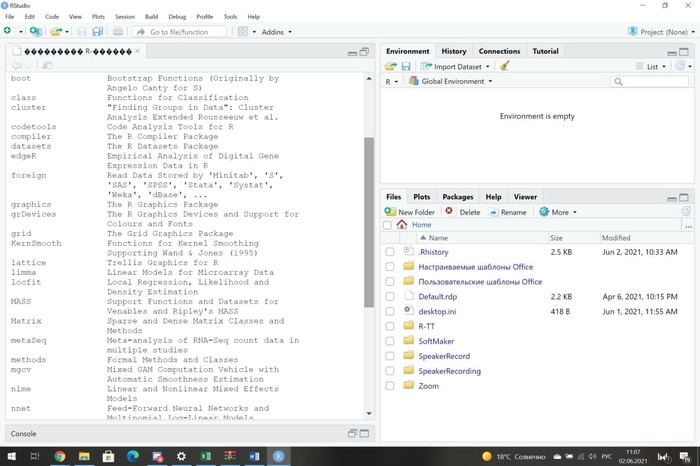
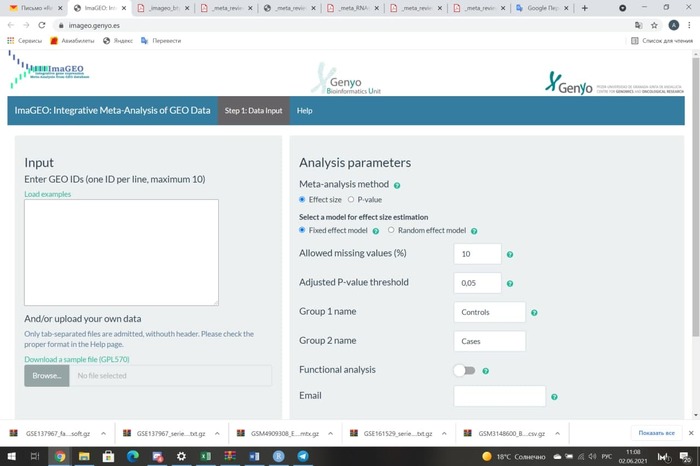
Всем привет. Достаточно серьезный вопрос. Потребуется вся мощь биоинформатиков. С программированием пока сложно, только учусь, поэтому нужна ваша помощь.
Суть задачи: дифференциальный анализ РНК-сек.
Знаю, что это можно провести либо через онлайн сервис, либо через пакеты в R Studio.
Но вот вопрос, как это правильно сделать?
В онлайн сервисе не до конца понимаю какие данные надо брать для их анализа и как использовать. В R Studio уже скачены библиотеки, но как правильно ими пользоваться? Какие нужны команды/коды, чтобы загрузить данные для анализа?
Очень надеюсь, что тут найдутся те, кто сможет помочь разобраться с этим вопросом! (вдруг найдутся те, кто знаком с этим)
Старение. Одно это слово вызывает в нас беспокойство. Почти всё время своего существования человечество бьётся над проблемой старения, стараясь продлить молодость и отсрочить неизбежный конец. Но что такое старение? Почему мы стареем? И можно ли замедлить этот процесс, или все наши попытки борьбы со временем тщетны? Давайте попробуем разобраться в этом вопросе.
Старение сейчас означает, что мы испытываем боль большую часть своей жизни.
Поэтому, ученые пытаются перевести внимание медицинского сообщества от увеличения продолжительности жизни к увеличению продолжительности времени, когда мы здоровы. Той части нашей жизни, в течение которой мы свободны от болезней. Поэтому, прежде чем искать источник вечной молодости, давайте сначала разберемся, почему мы вообще стареем.
С годами биологические функции тела снижаются, а вместе с ними – и способность адаптироваться к происходящим в нём трансформациям.
Существует множество внутренних и внешних факторов, таких как диета, стресс и окружающая среда, которые способствуют повреждению и восстановлению клеток.
Наши тела имеют множество механизмов для ремонта этого ущерба, но со временем они становятся менее эффективными.
Но удивительная истина заключается в том, что помимо внешних факторов, у нас есть биологические часы которые вшиты в наши гены. И время, отмеренное этими часами имеет свой предел. Другими словами, мы запрограммированы на смерть.
Давайте обратимся к тому, с чего всё начинается – к клеткам. Ваше тело состоит из триллионов клеток у которых есть "срок годности". Они постоянно делятся и при каждом делении создается копия ДНК. ДНК плотно упакована в структуры под называнием хромосомы, которых у человека, в норме, двадцать три пары.
Проблема в том, что репликация ДНК далека от совершенства. При каждом копировании теряется кончик хромосомы. Для защиты от удаления важной информации ДНК, на концах хромосомы расположены теломеры. Это повторяющиеся участки ДНК, которыми не страшно пожертвовать.
Но при каждом делении клетки, теломеры становятся всё короче и короче, пока от них ничего не остается.
Когда теломеры заканчиваются, клетка становится зомби - стареющей клеткой. Такие клетки остаются в теле и не умирают. Чем старше вы становитесь, тем у вас их больше. Они повреждают ткани вокруг них, а также они связаны со многими заболеваниями, такие как диабет и почечная недостаточность, которые зачастую сопровождают старость.
Отходы жизнедеятельности клеток накапливаются в соединительных тканях тела, что делает их менее эластичными. Из-за этого ухудшается работа кровеносных сосудов и органов дыхания. Но что, если бы мы смогли избавиться от мертвых клеток? Помогло бы это продлить нашу молодость? И если бы мы могли, должны ли мы прекратить старение?
Конец старения или продление жизни доставит многим людям неудобства. Мы рождаемся, становимся подростками, стареем, а потом умираем.
Это был естественный процесс на протяжении всей истории человечества, следовательно, стареть, это хорошо, ведь так? Нам нравится идея жить достаточно долго, чтобы дожить до старости. Мы даже называем это "золотые годы". Но реальность такова, что каждый хочет стать старым, но никто не хочет быть старым. Поэтому многие учёные прямо сейчас пытаются найти способ отсрочить старение.
Они генетически модифицировали мышей, чтобы они сами могли уничтожить свои стареющие клетки. Старые мыши без старых клеток были более активными. Их сердца и почки работали лучше, и они были менее склонны к раку. В целом, они жили на 30 процентов дольше и имели лучшее здоровье, чем обычные мыши.
Поскольку мы не можем генетически изменить все клетки в организме человека, нам нужно найти другой способ избавиться от наших старых клеток. Но как мы можем убить их, не нанося вреда здоровым клеткам? Большинство клеток в организме совершают запрограммированное самоубийство когда они повреждены, но стареющие клетки этого не делают.
Оказывается, они не производят белок, который говорит им, когда пришло время умереть. В конце 2016 года мышам была произведена инъекция этого белка. Он убил 80% старых клеток мышей, при этом практически не повредив здоровые клетки.
Подопытные мыши стали в целом более здоровыми и у них даже начали заново отрастать потерянные волосы. В результате появился целых ряд новых компаний, пробующих лечить стареющие клетки, и первые опыты на людях должны начаться в ближайшее время.
Другой способ отсрочить старение связан с использованием стволовых клеток. Это клетки, из которых формируются все органы и ткани нашего организма, чтобы обеспечить постоянный приток свежих молодых клеток, но их становится меньше, когда мы стареем.
Ученые заметили, что у мышей по мере исчезновения стволовых клеток в мозгу начали развиваться заболевания. Поэтому они взяли стволовые клетки из мозга мышей-младенцев и ввели их прямо в мозг мышей среднего возраста, конкретнее - в гипоталамус, часть мозга, которая участвует в регулировании множества физических функций.
Свежие стволовые клетки оживляли более старые клетки головного мозга, выделяя микро РНК, которые регулировали их метаболизм. Через 4 месяца мозг и мышцы работали лучше, чем у мышей без лечения, и в среднем они жили на десять процентов дольше. В другом исследовании были взяты стволовые клетки из эмбрионов мышей и введены непосредственно в сердца более взрослых мышей.
Как следствие, у них улучшилась сердечная функция, они могли тренироваться на 20% дольше, и как это ни странно у них быстрее отрастали новые волосы.
Все это говорит нам о том, что нет никакой волшебной пилюли, с помощью которой можно было бы обратить старение. Большинство людей думают, что они захотят умереть по достижении определенного возраста, и это все еще может быть правдой. Идея окончательной отмены смерти многих отпугивает. В любом случае, конец биологического старения не является концом смерти.
Это больше похоже на летний вечер, когда вы были ребенком, и ваша мама позвала вас домой. Вы просто хотели продолжить играть, повеселиться ещё немного во время заката перед сном. Разговор не о том, чтобы играть на улице вечно, просто чуть дольше, пока мы не почувствуем усталость.
Исследования структуры белка в проекте CAS@home
Область исследований: структура белка
Институт: Институт вычислительных технологий, CAS
Применение: TreeThreader
Введение
Понимание структур и взаимодействий белков необходимо для понимания их механизмов и, следовательно, необходимо для полного понимания жизненных процессов на молекулярном уровне. В настоящее время более семи миллионов случаев белка достигают точности ЯМР среднего разрешения, или последовательности помещаются в базу данных UniProtKB / TrEMBL, но только 50000 из них имеют экспериментально решенные структуры. Высокий спрос сообщества на белковые структуры поставил компьютерное прогнозирование белковой структуры, на беспрецедентно важную позицию.
Однако для предсказания структуры белка требуется огромное вычислительное время. Например, многопоточность, ведущий метод прогнозирования структуры белка, занимает очень много времени, поскольку последовательность запросов должна быть выровнена по всему шаблону в базе данных. Работа на добровольных началах - это просто отличный шанс для предсказания структуры белка.
Наша цель - разработать новую практическую программу потоков, которая может учитывать парное взаимодействие. Доказано, что общий случай (рассматриваются все парные контакты) задачи NP-труден. Итак, мы обратимся к использованию вложенного графа для описания частей контактов шаблона (так же, как ковариационная модель для анализа вторичной структуры РНК), что может быть выведено с точки зрения вычислительной эффективности.
Учитывая шаблон T и последовательность запросов S, структура программы выглядит следующим образом:
Представлять шаблон несколькими вложенными графиками.
Здесь мы используем итеративный алгоритм для решения этой проблемы, в каждом раунде используем динамическое программирование для построения оптимального вложенного графа и удаляем все содержащиеся в нем контакты из исходного графа контактов.
Выровняйте каждый вложенный граф с последовательностью запросов.
Мы используем CRF (условные случайные поля) для моделирования этой проблемы. CRF - это вероятностная модель, и ее можно легко добавить.
Объединить выравнивания вместе.
Каждый вложенный граф даст выравнивание между шаблоном и запросом. Мы можем объединить их в одно выравнивание на уровне апостериорной матрицы вероятностей, используя технику вероятностной согласованности, или построить окончательную модель независимо, используя MODELLER, и затем выбрать лучшую.
Прогресс
Спасибо всем вам! Мы завершили первую версию TreeThreader. Хотя контактная информация о дальнем расстоянии еще не рассматривается, эта версия имеет сопоставимые характеристики по сравнению с современными методами, такими как HHpred.
Мы рассмотрим дальнейшие контакты и учтем эту информацию в нашей следующей версии TreeThreader. Кроме того, наш TreeThreader принял участие в CASP10 (Эксперимент в сообществе, по критической оценке, методов прогнозирования структуры белка), одном из конкурсов прогнозирования структуры, в котором тестируется большинство современных методов. Мы сообщим о нашей работе в CASP10, как только будут опубликованы официальные результаты CASP10.
Моделирование молекулярной динамики
Введение
LAMMPS - это пакет моделирования молекулярной динамики с открытым исходным кодом, распространяемый SandiaNationalLaboratories.
Благодаря CAS @ Home, исследовательская группа в CNMM, Университет Цинхуа, использует универсальный интерфейс передачи заданий LAMMPS для запуска нескольких различных проектов, которые требуют крупномасштабного моделирования молекулярной динамики.
Первый проект LAMMPS, который будет запущен подобным образом CNMM, направлен на выполнение атомистического моделирования для изучения диффузии и транспорта молекулярного газа через наноразмерные каналы. Исследователи этого проекта - Ю Ван и Йозеф Эллингсен, главный исследователь - ЧжипинСюй.
Мотивация этого исследования заключается в разработке высокоэффективной и недорогой фильтрации для удаления летучих органических соединений (ЛОС) из азота и кислорода. Другими словами, это фундаментальное исследование новых способов фильтрации потенциально опасных химических веществ из воздуха, которым мы дышим.
Исследуемые фильтры основаны на иерархических сетях с участием наноструктурированных материалов. Расчеты, выполненные добровольцами, при статистическом анализе могут обеспечить профили свободной энергии для молекулярной диффузии.
Интерфейс передачи заданий LAMMPS / BOINC, используемый в этих исследованиях, разработан в сотрудничестве между Институтом физики высоких энергий, CAS, Лабораторией космических наук, Калифорнийский университет в Беркли, и CNMM, Университет Цинхуа. Интерфейс LAMMPS / BOINC доступен для других ученых для использования и адаптации для собственных исследований. Для получения дополнительной информации, пожалуйста, свяжитесь с CAS@home.
Пекинский электронный позитронный коллайдер
Введение
BES является детектором общего назначения, работающим на BEPC (Пекинский электронный позитронный коллайдер), и был запущен в строй в 1984 году, а производство - в 1989 году. Основные обновления были применены как на BEPC, так и на BES в период с 1995 по 1998 год, следовательно, BEPC обновлен до BEPCII, и BES является BESII и BESIII. BESIII - текущий детектор, работающий на BEPCII. BES - это первая экспериментальная установка для физики элементарных частиц, разработанная и реализованная в самом Китае и включающая несколько субдетекторов. Как детектор, BES составляет около 6 м в длину, 7 м по высоте и ширине и весит около 500 тонн. BESIII применяет множество передовых технологий детекторов из разных стран мира и подобен «глазу» BEPCII для захвата и измерения субчастиц, образующихся при столкновениях e + и e-, для изучения основной единицы и взаимодействия между частицами вещества на уровень микроструктуры. BESIII является единственным в мире детектором, который работает в области энергий от 2 до 5Gev, и около 200 физиков из 27 мировых исследовательских институтов присоединились к сотрудничеству BESIII для проведения исследований по физическим теориям, таким как сильные взаимодействия и слабые взаимодействия в области энергии Тау-Шарм.
Как и в других расчетах HEP-эксперимента, для BESIII обычно существует 3 вида вычислений:
Имитационные вычисления (также называемые вычислениями Монте-Карло): для имитации столкновений, происходящих внутри детектора.
Реконструкция вычислений: передача необработанных данных, полученных с детектора или сгенерированных с помощью моделирования, в данные с физическим значением.
Анализ Вычисления: Тест против физических теорий, основанных на восстановленных данных.
Среди всех этих 3-х вычислений BESIII SimulationComputing является наиболее подходящим для волонтерских вычислений, потому что для этого требуются очень ограниченные входные данные. Однако программное обеспечение, которое используется для запуска BESIII-моделирования (BOSS, BES OfflineSoftware), очень зависит от платформы, поэтому для выполнения заданий BESIII-вычислений в BOINC необходимо использовать технологии виртуальных машин.
Хотите принять участие в распределенных вычислениях, тогда, Вам сюда:


Догадались, о ком шутит юмористическая команда «Сборная России»? У нас есть еще девять таких шифровок. Давайте проверим, раскроете ли вы их все!
Исследование картирования маркеров рака, анализирующие данные рака легких.
Исследовательская группа по картированию онкологических маркеров
31 января 2020 г.
В этом всеобъемлющем обновлении команда «Картографирование маркеров рака» обсуждает прошлое (рак легких), настоящее (рак яичников) и будущее (саркома) проекта.
Фон https://www.worldcommunitygrid.org/research/mcm1/overview.do
Проект «Картирование маркеров рака» (MCM) был разработан для выявления маркеров, связанных с различными типами рака, и путем уточнения процесса идентификации этих маркеров, для более эффективной идентификации таких биомаркеров для других заболеваний. Мы стремились проанализировать несколько наборов данных о раке, чтобы выявить потенциальные биомаркеры для этих раковых заболеваний, которые могли бы в конечном итоге помочь ученым и врачам раньше выявлять раковые заболевания и создавать персонализированные методы лечения. Первые три набора данных в плане MCM - это легкие, яичники и саркома, представляющие прошлое, настоящее и будущее MCM. Обработка легких завершена. Идет обработка маркера яичников, но он близок к завершению. Сейчас мы готовимся к переходу на саркому.
Обработка набора данных в Grid World Community за месяцы и годы приводит к огромному количеству данных, и эти данные не могут использоваться напрямую, но затем их необходимо сопоставлять, фильтровать и анализировать различными способами. Мы сосредоточились на этом шаге постобработки в нашей лаборатории.
В этом обновлении мы в основном обсудим некоторые работы, выполненные с обработанным набором данных легких, но сначала мы взглянем на будущее.
Последние приготовления к саркоме
Предстоящий набор данных по саркоме будет самым сложным на сегодняшний день. Он содержит потенциальные биомаркеры, взятые из нескольких источников: измерения активности РНК, ДНК и белка, мутации и другие биологические условия.
С такой подробной информацией о каждом образце в наборе данных потребовалось некоторое усилие, чтобы уменьшить набор данных и размеры результатов до практических уровней. В настоящее время мы тестируем рабочие единицы нашего чернового набора данных и планируем работу.
В следующем обновлении будет объявлено о запуске новой фазы проекта MCM, сосредоточенной на саркоме, и будет предоставлено больше подробностей.
Результаты из набора данных легких
Биомаркеры в наборе данных легких МСМ измеряют активность тысяч генов. В совокупности эти биомаркеры охватывают большую часть человеческого генома. Большая часть работы с легкими MCM обрабатывается с помощью опросных подписей World Community Grid, случайным образом взятых из всего набора биомаркеров. Более короткая вторая фаза легкого MCM привлекала подписи от оптимизированных подмножеств этих биомаркеров.
Вклад вычислительных циклов в проект был экстраординарным. Члены World Community Grid обработали 4,5 триллиона кандидатов на рак легкого в основной фазе легкого MCM, 220 миллиардов в начальной экспериментальной фазе и 1,6 триллиона сигнатур в фазе оптимизации.
Мы обсудим некоторые выводы из основной фазы легкого MCM в этом обновлении.
Вопрос о размере подписи
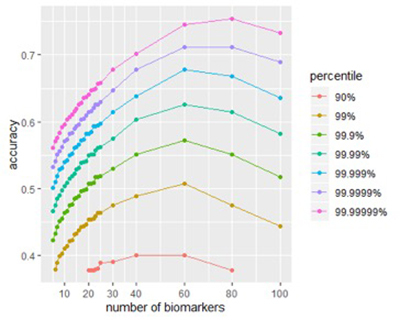
MCM рака легких обследовал подписи нескольких размеров. Размеры варьировались от 5 биомаркеров до 100, при этом наибольшее внимание уделялось сигнатурам в диапазоне от 10 до 20 биомаркеров. Чтобы сигнатура рака успешно применялась в клинической практике, размер сигнатуры является компромиссом между диагностической силой, сложностью и стоимостью. Каждый биомаркер потенциально может добавлять диагностическую информацию к сигнатуре, повышая точность, но слишком большое количество биомаркеров также может добавлять шум и излишне увеличивать стоимость и сложность для практического использования в клинике.
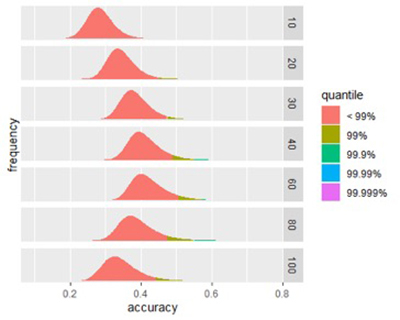
На рисунке ниже показано влияние размера подписи на пиковую точность. Почти для любого размера сигнатура, построенная из случайно выбранных биомаркеров, будет иметь низкую точность, но, протестировав достаточное количество таких сигнатур, а затем посмотрев на точность верхней фракции (скажем, верхней 0,01%), мы увидим эффект, производимый размер подписи. Тщательно разработанные подписи должны достигать той же точности, используя меньше биомаркеров.
Рисунок 1А
Рисунки 1A и 1B: Размер влияет на потенциальную точность подписи. (A) Распределение баллов по успешным сигнатурам разных размеров. (B) Присмотритесь к влиянию размера точности оценки. Пиковая точность находится в сигнатурах между 40-80 биомаркерами.
Какие биомаркеры наиболее успешны?
В основной фазе легкого MCM сигнатуры были построены из биомаркеров, выбранных случайным образом из набора данных. Таким образом, у каждого биомаркера была одинаковая вероятность появления в каждой новой подписи. Это, однако, не означает, что все биомаркеры одинаково полезны - как мы уже говорили выше, случайная сигнатура, скорее всего, будет иметь низкую точность. Однако, если мы берем только самую точную часть подписей и видим, какие биомаркеры они содержат, мы видим, что несколько биомаркеров появляются часто, а остальные относительно редко. (Мы можем даже заметить закономерности в том, что определенные группы биомаркеров появляются вместе, как мы обсуждали в предыдущем обновлении.) Затем мы можем определить, насколько эффективен или полезен каждый биомаркер из того, как часто он появляется в этих главных сигнатурах.
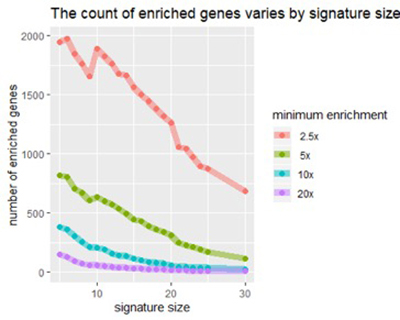
Рисунок 2: По мере увеличения размера подписи мы видим уменьшение количества генов, обогащенных любым фактором (например, в 5 раз выше нормы).
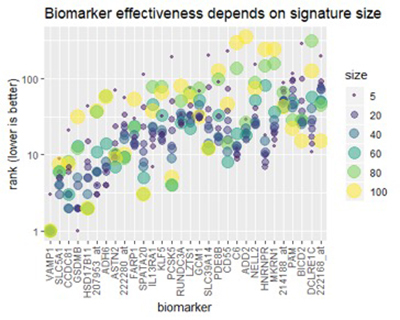
Проанализировав полный набор результатов MCM в легких, мы можем подтвердить эффект, который мы заметили в предыдущих предварительных исследованиях: эффективность каждого биомаркера зависит от размера сигнатуры, по-разному влияя на каждый биомаркер. На рисунке ниже показан эффект для некоторых самых популярных биомаркеров.
Рисунок 3
Рисунок 3: Размер сигнатуры рака легких определяет, насколько полезным может быть биомаркер. По мере роста размера подписи отдельные биомаркеры могут стать более или менее эффективными.
Обогащение пути среди лучших биомаркеров
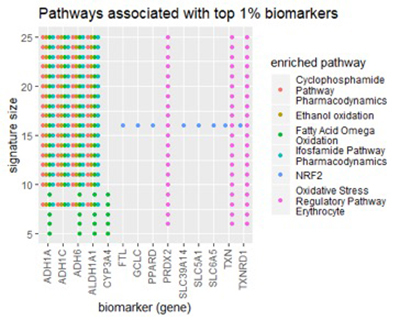
Чтобы получить более высокое представление о биомаркерах, обнаруженных в наборе данных легких, мы исследовали их с точки зрения пути. Путь - это группа генов, которые взаимодействуют для выполнения одной и той же биологической функции. Мы поместили списки лучших биомаркеров в базу данных pathDIP нашей лаборатории [1], [2]. pathDIP представляет собой комплексную интегрированную базу данных известных путей (сигнальных каскадов), и, учитывая список генов, он найдет все пути, связанные с любым геном в списке. Наиболее полезно, он будет измерять обогащение каждого пути в вашем списке генов - степень, в которой путь имеет соединение выше среднего с вашим списком. Используя такой анализ, мы стремимся найти биологически значимую интерпретацию наших идентифицированных биомаркеров.
На рисунке ниже показаны результаты работы pathDIP.
Рисунок 4 http://ophid.utoronto.ca/pathDIP/
При большом количестве размеров подписи pathDIP постоянно находил пять путей, обогащенных в наших списках генов:
Циклофосфамидный путь, фармакодинамика
Путь ифосфамида, фармакодинамика
Окисление этанола
Омега окисление жирных кислот
Регуляторный путь окислительного стресса (эритроцит)
Все пять обогащенных путей связаны с обменом веществ, что означает распад химических веществ в организме. Любопытно, что первые два пути связаны конкретно с метаболизмом химиотерапевтических препаратов, циклофосфамида и ифосфамида. Последние три относятся либо к окислению, либо к предотвращению окислительного стресса (свободных радикалов) в эритроцитах.
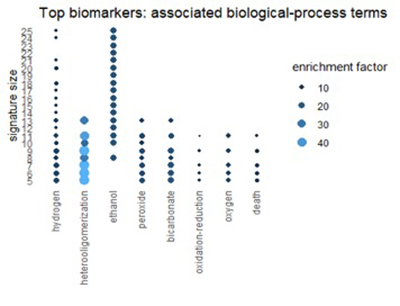
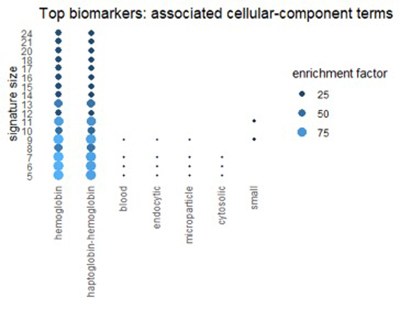
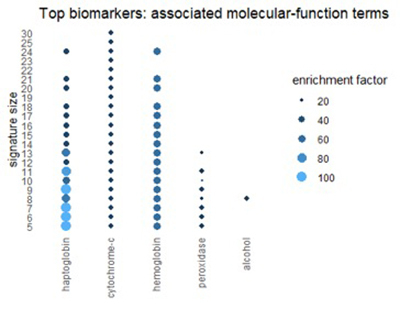
Использование ресурса генной онтологии для описания лучших биомаркеров
Мы можем получить соответствующее представление из Ресурса генной онтологии (GO). GO классифицирует каждый ген с трех разных точек зрения: биологический процесс, молекулярная функция и клеточный компонент. На рисунках ниже показаны термины в категориях GO, которые часто встречаются в топ-1% биомаркеров.
Рисунок 5
Рисунок 6
Рисунок 7
Многие термины отражают темы, обнаруженные в путях: окисление, алкоголь и химию эритроцитов.
Заглядывая вперед
Мы находимся в процессе расширения и объединения нескольких дополнительных анализов данных легких основной фазы и существенных анализов результатов легких второй фазы. После этого данные яичников ждут. Для яичников, некоторые из тех же методов будут применяться, но некоторые должны быть адаптированы, а некоторые нам нужно будет разработать.
Короче говоря, проект MCM будет долгое время занимать нас. Тем временем, мы хотели бы поблагодарить вас за ваш интерес и за щедрое пожертвование вычислительной мощности в этот и другие проекты World Community Grid. Мы будем предоставлять обновления чаще сейчас.