


Потенциально вкусный сфероид в вакууме
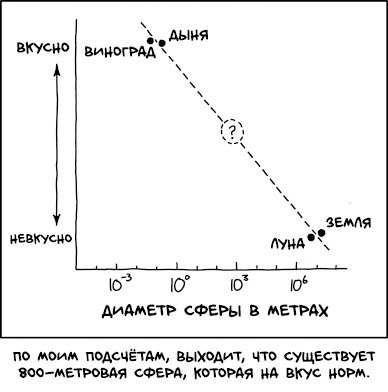
(не по моим подсчётам, конечно, но вы поняли)
Показать полностью
(не по моим подсчётам, конечно, но вы поняли)
Видео с подробным объяснением того, что происходит на видео:
Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
Реклама АО «Кордиант», ИНН 7601001509
Имеем
- 3 пары водителей( ездят по двое)
- 2 автомобиля
- маршрут с кругом 2 суток +/-
- 1 день для обслуживания авто( условно 1 числа поехала, 3 числа вернулась( прошла осмотр, где надо починилась), 4 снова поехала с другой парой водителей.
Как это все увязать и максимально эффективно использовать авто? Спасибо.
Сейчас выпускается крайне много разных устройств с экранами от разных брендов (в последние годы этим активно занимается Китай), а некоторые бренды резко теряют популярность (как например, американские санкции сделали рискованным покупку iPhone, что видно по резкому снижению доли рынка Apple в России). Каждый бренд имеет свои представления о стандартах, более того разные модели даже от одного бренда очень сильно отличаются друг от друга размером экрана и плотностью пикселей на дюйм. Если Вы по-прежнему думаете, что каноничное соотношение 16:9, пришедшее на смену 4:3 до сих пор является самым популярным, то Ваша информация, увы, устарела.
Итак, представляем анализ статистики по разрешениям экранов за последние 5 месяцев:
Вертикальное видео
Начнём со сравнительно нового формата вертикального видео, то статистика по соотношениям на смартфонах (планшеты не включены в эту статистику, так как по умолчанию они всё-таки широкоэкранные) выглядит следующим образом:
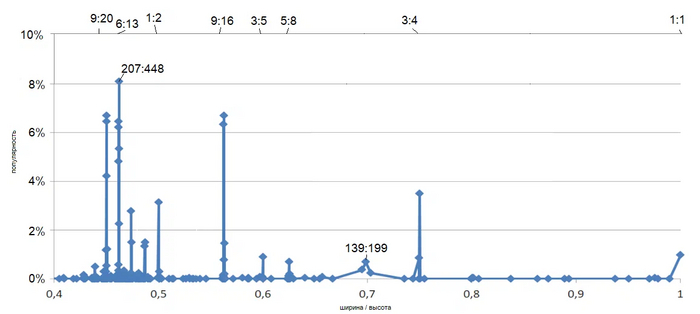
Самое популярное соотношение здесь 207:448 (например, 1792×828 у iPhone 11) - почти то же самое, что 6:13 - чуть выше 8% от всех пользователей, в то время как 9:16 (вертикальная ориентация) на целый процент меньше.
Так что, если Вы - перфекционист и хотите, чтобы контент тютелька в тютельку умещался на экране - возьмите за основу (нюансы позже) соотношение 207:448. Однако так Вы попадёте лишь в 2 из 25 из аудитории. В принципе, остальные тоже увидят Ваше видео, но не целиком - края обрежутся, чтобы заполнить весь экран. Это не так критично (если оставлять поля у важной информации - об этом далее будет подробней) и можно сравнить хотя бы близкие друг к другу соотношения. Разделим отношения ширины к высоте на 5 более-менее равных групп следующим образом:
(9:20 и 6:13) (1:2) (9:16) (3:4) (1:1) - как думаете какая группа пользуется большей популярностью? - (0 , 0.48) [0.48 , 0.53) [0.53 , 0.67) [0.67 , 0.86) [0.86 , 1]
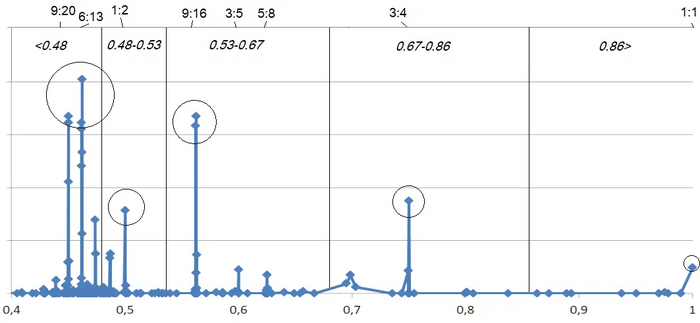
Итак, вот результаты:
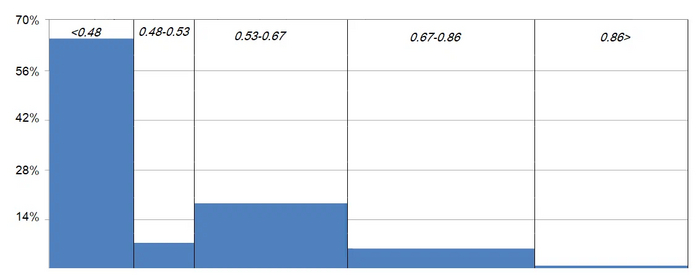
Очевидно, что выигрывают соотношения уже, чем 1:2
Хорошо, мы доказали, что 9:16 - это совсем мимо (ниже сможете сравнить насколько). Но если мы не слишком требовательны к точности (пусть чутка края обрежутся, зато у большинства, чем у большинства пол-видео обрежется, а лишь у некоторых всё будет чётко), какое всё-таки конкретное соотношение выбрать? Для ответа на этот вопрос проанализируем более детально первую группу, набравшую 66,6%:
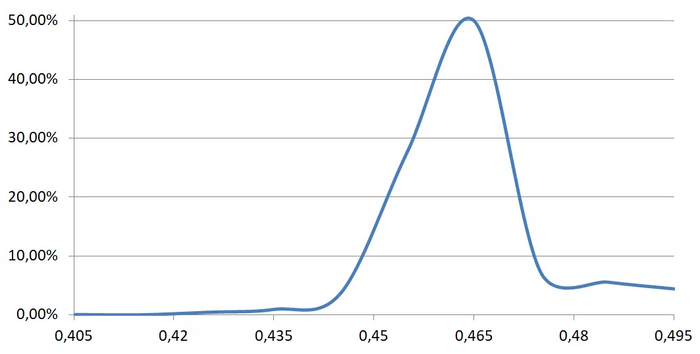
Более 50% здесь - где-то в промежутке 0,455 - 0,47 (погрешность ±0,005)
А теперь посмотрим на самый первый график более детально в этом интервале с максимумом:
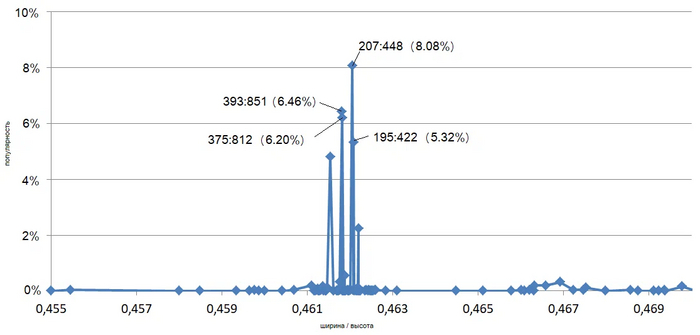
Видим знакомое нам 207:448 на первом месте, однако практически в этой же точке абсцисс есть и другое популярное соотношение, а чуть левее та же ситуация ещё с двумя популярными соотношениями.
Какое же выбрать? Ну что ж, если мы посчитаем какая из двух групп популярнее по сумме, то получится 12,66% слева против 13,4% справа. айфоновское 207:448 не без борьбы, но всё же выиграло.
Посмотрим насколько точно мы попали...
Читайте далее, а также про горизонтальный формат видео здесь
Я много работаю с данными. Часто при этом приходится строить графики. Иногда они получаются довольно забавными или просто красивыми. Вот подборка таких графиков:
1. Бурдж Халифа
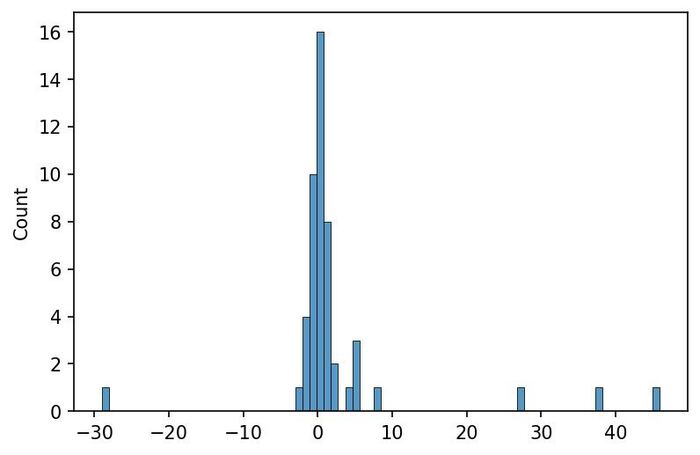
Это гистограмма по данным из домашнего задания по статистике. Здесь я исследовал нормальное распределение с выбросами. Нормальное распределение – это когда часто попадаются "средние" наблюдения и реже другие. Например, нормально распределён рост у людей одного пола: у большинства он промежуточный, но есть меньшее количество высоких и низких людей
В этих данных среднее равно нулю. Здесь к нормальному распределению примешано распределение Коши: оно ведёт себя непредсказуемым образом, выдавая то очень большие, то очень маленькие значения. Картина получилась похожей на ландшафт Дубаи с небоскрёбом Бурдж Халифа в центре

2. Мандаринки отбрасывают тень на стол, вид сверху

Снова данные из домашнего задания по статистике. Сами по себе они ничего не означают, я использовал их для отработки методов по поиску необычных значений – выбросов. Например, как точки снизу справа: они явно выбиваются из общей картины
Для того, чтобы применить статистический метод, мне нужно было "центрировать данные": переместить точки так, чтобы средние значения были равны нулю по обоим осям. После этого я решил удостовериться, что операция сработала правильно. Построил график, где исходные данные изображены синим, а центрированные – оранжевым цветом. Получилось похоже на мандаринки на столе
3. Распределение Бэтмена

Однажды мне нужно было изобразить моё любимое распределение. Тогда я в шутку нарисовал кривую, которую назвал распределением Бэтмена. Шутка зашла довольно далеко: теперь я часто применяю это распределение, когда нужно проверить что-то на необычных данных. А однажды по работе мне нужно было показать некоторые математические преобразования над кривыми. Я снова использовал кривую Бэтмена. Было довольно забавно презентовать серьёзным людям, как изменяется форма головы Бэтмена, и получать за это деньги
Вот пример картинки с презентации. Идея в том, чтобы применять к кривой операции, которые изменяют её, но в целом сохраняют форму. Голова Бэтмена подошла для демонстрации идеи идеально:
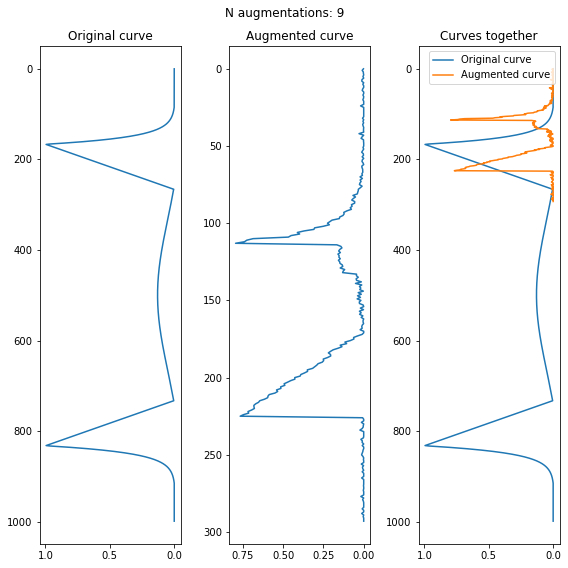
4. Скат

Здесь я проверял качество работы одной статистической процедуры. Правильный ответ, который она должна была выдавать – 395. По графику плотности видно, что в большинстве случаев так и есть. Но иногда попадались значительно меньшие значения, которые сформировали "хвост" распределения. Так получился график, похожий на ската
Моя группа ВК и телеграм-канал
Если хотите сразу быстро, прокрутите до части II.
Существуют разные математические операции.
► 1. Известны два слагаемых — нам требуется операция сложения.
Пример:
2+3 = a
a = 5
► 2. Известно одно слагаемое и результат — нам требуется операция вычитания.
Пример:
1+a = 2
a = 2-1
a = 1
► 3. Известны два множителя — нам требуется операция умножения.
Пример:
3*4 = a
a = 12
► 4. Известен один множитель и результат — нам требуется операция деления.
Пример:
2*a = 6
a = 6/2
a = 3
► 5. Известно число и степень, в которую оно возводится, — нам требуется операция возведения в степень.
Пример:
5^2 = a
a = 25
► 6. Известна степень, в которую возводится число, и результат — нам требуется операция извлечения корня (или возведение в дробную степень).
Пример:
a^3 = 27
a = ∛27 = 27^(1/3) = 3
► 7. Известно число и результат, который получается при возведении числа в некоторую степень, — нам требуется логарифм.
Пример:
4^a = 64
a = log_4(64)
a = 3
(если кто не знал, как связана возведение в степень, извлечение корня и нахождение логарифма)
► 8. Известна формула графика и значение аргумента. Если мы хотим узнать значения функции — нам требуется подставить значение в формулу.
Пример:
y = 2 * x + 4,
где x = 3, тогда
y = 2 * 3 + 4
y = 10
► 9. Известна формула графика и значение функции. Если мы хотим узнать значение аргумента — нам требуется подставить значения в формулу.
Пример:
y = 3 * x^2 + 2,
где y = 29, тогда
29 = 3 * x^2 + 2
27 = 3 * x^2
x^2 = 9
x = √9
x = 3
► 10. Известны два или несколько значений аргумента и принимаемых при этом значений функции. Хотим узнать формулу графика. Для этого нам требуется регрессионный анализ.
Так что то, что делалось в школе было своеобразной подготовкой, пусть и на более простых линейных уравнениях.
Впрочем, вот готовый инструмент.
Вставляйте в качестве X и Y показатели, и будет рассчитываться коэффициенты для графика.
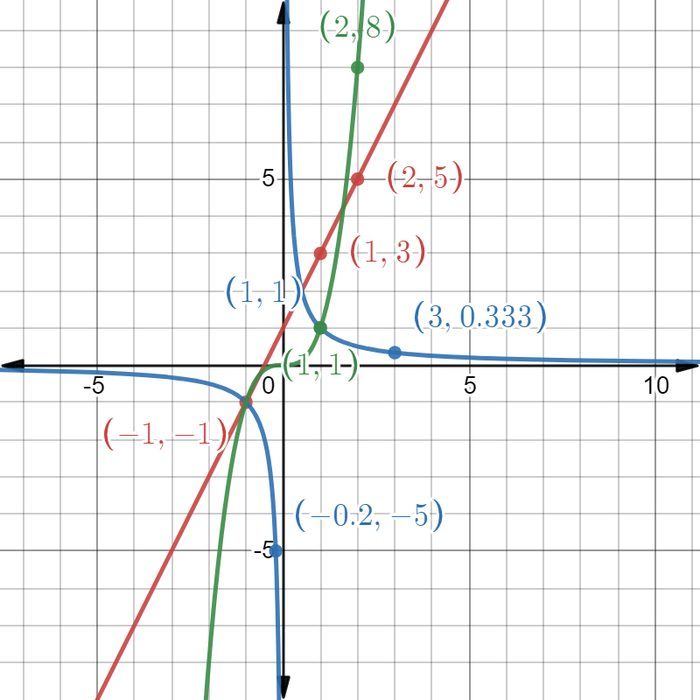
Если вы ещё не знакомы с Desmos, то это очень удобный сервис по построению графиков, решению задач и прочему.
Помимо построений по заданным точкам и формулам, если графиков несколько, то можно их нарисовать несколько, а потом определить их точки пересечения.
Есть и возможность "зарисовывать" области, что помогает при интегралах, там же можно добавлять граничные условия, многое другое.
Подробнее можно почитать и посмотреть тут (пройтись по всем интерактивным примерам):
ТЕОРИЯ РЕГРЕССИОННОГО АНАЛИЗА
А). В общем случае график функции выглядит так. Линейная зависимость.
y = k * x + bВ обычном случае подставляются значения первой и второй точки, решается система уравнений. Но можно использовать инструмент выше.
где k — часто угол наклона,
b — часто величина подъёма.
Б). Ещё в более общем виде график может выглядеть так. Нелинейная (часто квадратичная) зависимость.
y = k * x^n + b
где n — позволяет описать степенную функцию (аналог параболы при положительных значениях выше 1, гипербола при отрицательных). Часто n=2.
В). Иногда может быть логарифмическая зависимость:
y = k * ln(x) + b
В реальной жизни часто имеются "точки" (показатели X, Y) и бывает нужно найти хотя бы приблизительную "формулу графика", некоторые тенденции — такие данные суть статистики.
А статистика применяется в различных сферах знаний — медицина, социальные науки, финансы, эконометрика и др.
Например, ориентировочно знаем, на сколько увеличивается выпуск продукции при росте капиталовложений (X1, Y1; X2, Y2; X3, Y3). Вероятно, будет некоторая логарифмическая зависимость, получилась бы какая-то формула. А была бы формула, могло бы быть интересно, сколько будет Y4 при заданном X4.
Или, например, имеются показатели ВВП на душу населения (с поправкой на инфляцию) за 10 лет. И показатели продаж, ну, допустим, импортных автомобилей. Будет, скорее всего, некоторая линейная зависимость. И если точный график мог бы не так помочь, то как минимум приблизительно можно было судить о некоторой взаимозависимости факторов (или, так называемой, "корреляции"), которая может быть как положительной (растёт X, растёт Y), так и отрицательной (растёт X, падает Y). Аналитиками также мог бы добавиться дополнительный показатель, так называемый коэффициент "автокорреляции" (поправка на время), поскольку в этом примере идёт некоторый анализ "временных рядов".
А то, насколько приблизительно "правильной" получится модель, мог бы сказать, так называемый, показатель R^2, его ещё называют "коэффициентом детерминации". Который характеризует "плотность выборки" (чем ближе к 1, тем точнее), или точность между имеющимися точками и проходящим через них графиком.
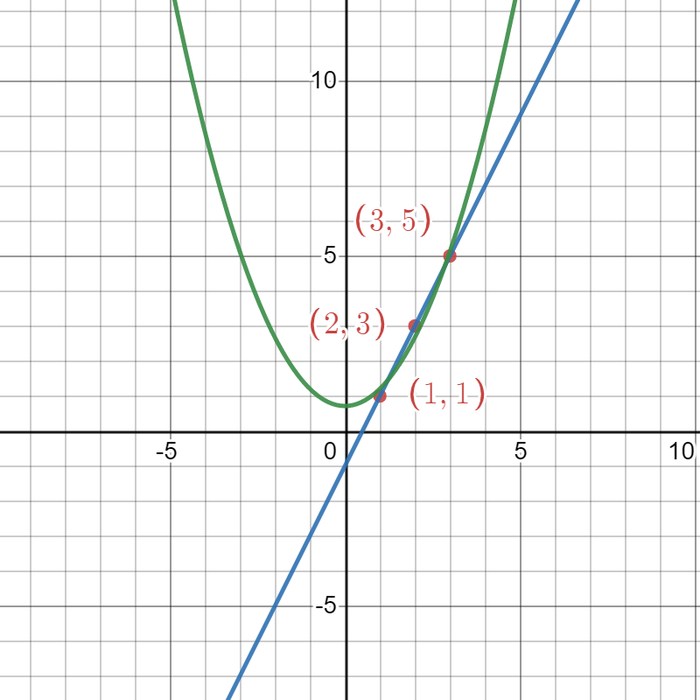
Например,
y = k * x + b
x = [1, 2, 3]
y = [1, 3, 5]
даст
R^2 = 1
k = 2
b = -1
Потому что это та самая формула.
А предположи мы, что формула
y = k * x^2 + b,
тогда
R^2 = 0,9796
и менее красивые коэффициенты k и b.
Что очень близко, согласитесь, положительная часть графика параболы ведь почти проходит через нужные точки, поэтому он и не равен 1 (иногда в реальных задачах по анализу тенденций показатель R^2 до 0,9 — считается вполне терпимым, хотя лучше 0,99+).
В заключение.
Сначала идёт "сложение", потом "умножение", затем базирующееся на этом "возведение в степень". Увеличивается уровень абстракции, пусть и можно было бы обойтись одним сложением и вычитанием (например, как при японском способе умножения требуются только эти две простые операции).
Так что изучение базы в целом полезно, а также важен подход к обучению. Тогда можно во многом разобраться, в том числе и с регрессией и всяким таким.
Надеюсь, было немного интересно.
Два графика с Desmos. Остальное собственное — CC0.
Формула Таппера- впервые формула была опубликована в 2001 году в докладе Джеффа Таппера, это самореферентная (при определённых условиях) формула, будучи отображённой на плоскости, создаёт собственное изображение.
Формула является вот таким неравенством:
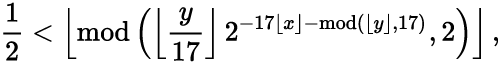
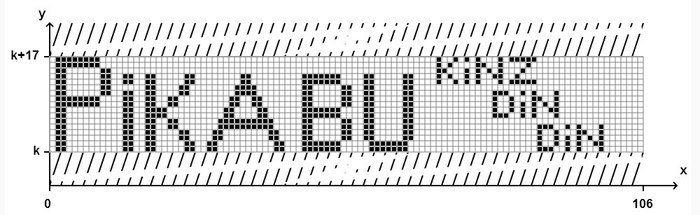
Что значит "будучи отображённой на плоскости, создаёт собственное изображение"? Ну, собственно это и значит. Если отобразить это неравенство на плоскости OXY, то по оси OX оно займёт 106 пикселей (от 0 до 105), а по оси OY- 17 пикселей и будет выглядеть так:

А почему это формула всего? А дело в оси OY. Видите там слева k, k+5, k+10, k+15? Ну это значения на оси OX, просто в данном случае k= 960 939 379 918 958 884 971 672 962 127 852 754 715 004 339 660 129 306 651 505 519 271 702 802 395 266 424 689 642 842 174 350 718 121 267 153 782 770 623 355 993 237 280 874 144 307 891 325 963 941 337 723 487 857 735 749 823 926 629 715 517 173 716 995 165 232 890 538 221 612 403 238 855 866 184 013 235 585 136 048 828 693 337 902 491 454 229 288 667 081 096 184 496 091 705 183 454 067 827 731 551 705 405 381 627 380 967 602 565 625 016 981 482 083 418 783 163 849 115 590 225 610 003 652 351 370 343 874 461 848 378 737 238 198 224 849 863 465 033 159 410 054 974 700 593 138 339 226 497 249 461 751 545 728 366 702 369 745 461 014 655 997 933 798 537 483 143 786 841 806 593 422 227 898 388 722 980 000 748 404 719.

Где-то там в далёкой-далёкой галактике на оси OY среди бесконечного количество значений есть бесконечное количество изображений, заданных этой формулой. Т.е. там есть ВСЕ ВОЗМОЖНЫЕ изображения размером 106 на 17 пикселей.
Например, при k= 172 895 466 264 656 362 238 775 198 618 400 053 006 722 417 830 074 875 710 077 840 558 718 522 933 856 481 624 057 883 539 289 927 382 958 168 812 116 931 135 487 324 743 680 349 552 434 460 222 923 986 273 388 093 735 529 486 165 346 092 911 369 252 390 353 778 634 279 896 583 455 425 859 634 440 043 584 268 093 410 716 443 082 284 154 873 275 541 781 431 502 156 517 367 941 053 074 097 258 022 615 110 586 256 528 662 395 677 501 188 461 923 095 483 961 995 173 180 815 230 411 356 269 083 712 579 786 823 770 925 493 943 423 964 558 741 203 303 534 803 553 728 066 326 116 959 373 467 996 584 250 693 892 202 679 445 143 468 361 413 129 347 669 354 301 413 221 990 4
Изображено вот такое:
:)
Про эту формулу есть ролик у Numberphile (у Numberphile вообще много интересного есть, рекомендую)
Для поиска таких изображений можно ползать по оси OY, выискивая ответ в изображении на главный вопрос жизни вселенной и всего такого, а можно пойти от обратного,- зная, какой рисунок вам нужен, вычислить где он находится (найти нужную k):
1) Представить изображение в растровом виде на поле 106*17;
2) Заменить, двигаясь снизу-вверх и слева-направо, закрашенные клетки на "1", а пустые на "0";
3) Перевести полученное число в десятичную систему счисления;
4) Умножить число на 17;
Ну и сидеть ручками всё это считать-рисовать... :)
Ну или для серьёзных научных исследований баловства с этой формулой можно воспользоваться сайтом https://tuppers-formula.ovh/ на котором можно посмотреть изображение, задавая k, а можно получить это k, нарисовав своё изображение.
243 360 568 621 479 808 105 821 007 995 688 471 150 942 429 613 551 037 724 303 784 100 951 604 415 418 362 731 453 888 556 191 052 249 118 336 352 931 496 936 789 788 748 055 842 135 892 069 309 262 686 645 776 836 840 029 688 597 908 795 428 731 279 581 471 306 887 721 134 752 807 558 021 371 476 276 526 900 631 500 172 334 929 427 133 749 231 787 654 103 952 493 711 156 866 417 493 097 770 595 847 457 153 138 755 788 944 574 235 342 895 266 789 470 996 967 566 958 605 153 957 095 619 541 720 088 274 714 109 846 036 624 630 340 843 465 635 216 695 610 204 667 835 082 328 084 140 882 231 783 456 237 802 742 506 700 8
Конкурс мемов объявляется открытым!
Выкручивайте остроумие на максимум и придумайте надпись для стикера из шаблонов ниже. Лучшие идеи войдут в стикерпак, а их авторы получат полугодовую подписку на сервис «Пакет».
Кто сделал и отправил мемас на конкурс — молодец! Результаты конкурса мы объявим уже 3 мая, поделимся лучшими шутками по мнению жюри и ссылкой на стикерпак в телеграме. Полные правила конкурса.
А пока предлагаем посмотреть видео, из которых мы сделали шаблоны для мемов. В главной роли Валентин Выгодный и «Пакет» от Х5 — сервис для выгодных покупок в «Пятёрочке» и «Перекрёстке».
Реклама ООО «Корпоративный центр ИКС 5», ИНН: 7728632689





