Изучаем Wolfram Language - 4. Синтаксис
В предыдущей статье мы рассмотрели интерфейс Wolfram Mathematica. В этой мы наконец-то приступим к изучению самого языка. Начнем с основного синтаксиса. Под синтаксисом я буду подразумевать только допустимые конструкции языка, но не сами функции.
По сравнению со многими популярными языками программирования, дизайн Wolfram Language довольно необычен. Современные популярные языки, например, Python, C# или JavaScript имеют синтаксис, состоящий из ключевых слов и определений в строгом порядке. Например, в Python для создания функции я должен написать вот такой код:
def my_func(x, y):
return x + y
В качестве элементов самого синтаксиса здесь выступают ключевые слова def и return, специальные знаки разделяющие или группирующие код "()", ", " и ":". А так же оператор сложения и свои собственные имена - их я могу придумать любые (только если они не заняты ключевыми словами). Я всего лишь использовал одну из многих существующих конструкций в Python, а элементов синтаксиса получилось не так уж и мало. Причем считается, что относительно других языков программирования, Python имеет довольно лаконичный синтаксис.
А теперь рассмотрим основные синтаксические конструкции WL.
Комментарии
Они пишутся в колючих скобочках (**) и могут быть в любом месте кода и занимать больше одной строки:
1 + 1 (* слева 2 *) + 3 + 4 (* еще комментарий *)
Создание переменной:
x = 1
Создать несколько переменных, как это работает в Python, нельзя:
x, y, z = 1, 2, 3
Но можно присвоить значения списку переменных:
{x, y, z} = {1, 2, 3}
Важно, чтобы количество элементов в списках слева и справа совпадало. WL - язык с динамической типизацией - это значит, что переменные могут хранить значения любых типов и изменять значения не обращая внимания на тип.
x = 1
x = "string"
Очистка значения переменной
Есть несколько способов:
x =.
Или
Clear[x]
Или
ClearAll[x]
Последний вариант более надежен, так как он очищает не только значение, но и атрибуты (с которыми мы познакомимся в следующих постах).
Арифметика
Поддерживаются все типичные арифметические операции:
Сложение
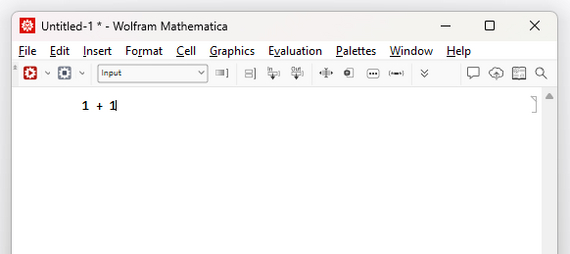
1 + 1 (* => 2 *)
Вычитание
1 - 2 (* => -1 *)
Умножение
3 * 5 (* => 15 *)
Деление
9 / 3 (* => 3 *)
Возведение в степень
3^2 (* => 9 *)
Сравнение
Сравнивать можно все что угодно. Например числа:
1 == 2 (* => False *)
Строки:
"string1" == "String1" (* => False *)
Списки:
{1, 2, 3} == {1, 2, 3} (* => True *)
Числа разных типов:
1.0 == 1 (* => True *)
На последнем примере остановимся подробнее. Мы сравнили целое и действительное число и вернулось True. Что нужно сделать чтобы убедиться, что типы не совпадают? Сравнить при помощи точного сравнения:
1.0 === 1 (* => False *)
Отличие точного сравнения от обычного еще в том, что при обычном сравнении, если WL не знает как сравнить два выражения - то возвращается ввод:
x+y == a+b (* => x+y == a+b *)
Точное сравнение всегда гарантирует результат True или False.
x+y === a+b (* => False *)
И еще несколько операций сравнения:
1 < 2 == True (*меньше*)
2 <= 2 == True (*меньше или равно*)
3 > 2 == True (*больше*)
3 >= 3 == True (*больше или равно*)
4 != 5 == True (*неравно*)
a != b == a != b (*неравно возвращает ввод если выражения несравнимы*)
a =!= b == False (*строгое неравно*)
Логические операции
Логическое "и" при помощи &&:
x = 5
x < 6 && x > 1 == True
Логическое "или" при помощи ||:
x = 10
x > 11 || x <= 10 == True
Логическое отрицание при помощи "!":
x = 15
!(x < 5 || x > 20) == True
Создание функций:
Самая важная часть синтаксиса - это создание собственных функций:
myFunc[x_, y_] := x + y
Обратите внимание, что для функции используется знак ":=" - это отложенное присваивание. Оно означает, что код справа не выполняется во время создания определения, но выполняется во время вызова функции.
Естественно определение функции можно очистить:
ClearAll[myFunc]
Но в WL функции можно очень легко перегружать на различных типах аргументов. То есть я могу создать дополнительное определение:
myFunc[x_] := myFunc[x, 1]
И очистить только одно из определений тоже можно:
myFunc[x_] =.
Clear или ClearAll такой способ не поддерживают, а очищают все определения.
На этом на сегодня все, в следующей части мы рассмотрим основные структуры данных и способы работы с ними, всем спасибо за внимание!