Всех приветствую, сегодня пойдет речь о функциях filter и map, которые часто используются совместно с lambda, так что затронем и её. весь код размещен на GITHUB (все примеры пронумерованы в том же порядке, в котором они идут в посте)
Map
функция map принимает следующие аргументы map(func, *iterables) и возвращает итератор, чтобы его превратить в удобоваримый вид надо обернуть его в какую-либо структуру данных, далее в примерах мы будет превращать все итераторы в list. Что означает (*) перед iterables? Это указывает на то, что мы можем передавать сколь угодно большое число наших итерируемых объектов (списков, кортежей и т.д.), но из этого следует логичный вопрос, что если мы передали три списка, а количество элементов у них разное?
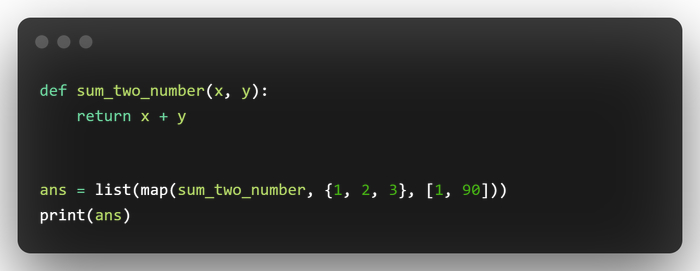
Давайте приведу пример функции, которая принимает два числа и возвращает их сумму:
В списке ans у нас будет храниться список, который будет равен [2, 92], почему так? Потому что мы пробегаем по первым min(len(*iterables)) аргументам и суммируем только их, остальные мы игнорируем, так например мы проигнорировали тройку в первом множестве {1, 2, 3}.
Map используют с основными функциями, такими как str, strip, split, int и другими.
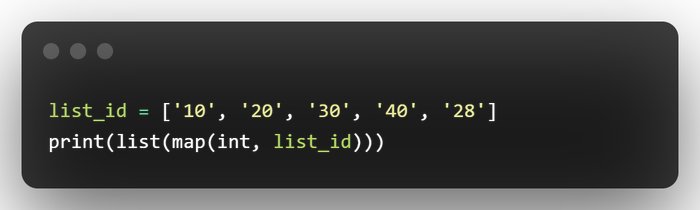
Давайте представим, что вы спарсили айдишники сотрудников (изначально они в str) и хотим превратить их в int => напишем следующую строчку:
Мы напечатаем список, в котором будет изменены все строчки на числа (ВНИМАНИЕ! ЕСЛИ МЫ НАПЕЧАТАЕМ list_id, ТО ОН ОСТАНЕТСЯ НЕИЗМЕННЫМ! map НЕ изменяет сам список)
Чтобы применить более сложные функции, например strip или split, то нужно написать чуть более сложную конструкцию. Например в txt файле данные хранятся так: 'apple 1$ mango 20$ orange 3$', мы уже превратили их в список и уже имеем ['apple 1$', 'mango 20$', 'orange 3$'], а хотим получить на выходе это [['apple', '1$'], ['mango', '20$'], ['orange', '3$']] чтобы получить нашу зарплату в 100000$ => нам нужно написать функцию map:
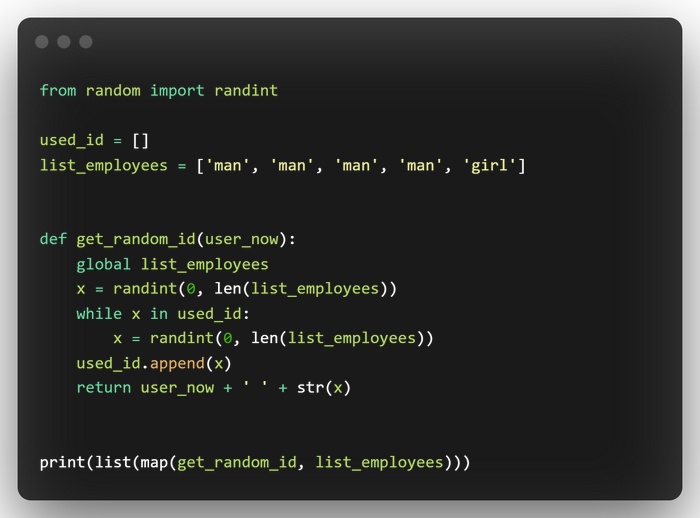
Приведу еще один пример с функцией map, допустим у нас есть n - ое количество сотрудников нашей компании, которые работают на удаленке и мы им должны выдать уникальные айдишники, по типу (пол сотрудника - {id}).
Это можно было решить простым перебором от 0 до len(list_employees), но так как мы хотим именно рандомные айди, то сделали чуть сложнее. Что мы делаем? мы создали функцию get_random_id, которая принимает текущего пользователя, затем получает рандомное число и сохраняет его в список used_id (чтобы id не повторялись).
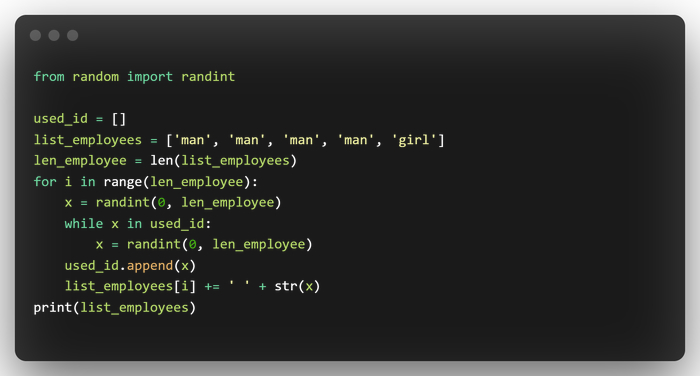
Также можно переписать данное решение без применение map:
Мы получим аналогичный результат, но в первом случае мы не только получили более читаемый и приятный глазу код, но можем использовать данную функцию много раз в коде => соблюдаем основной принцип разработки DRY (Don't repeat yourself)
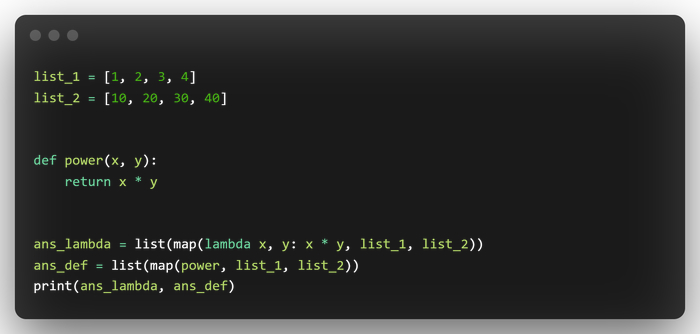
Разберемся теперь с lambda функцией и как её совмещать с map, вообще lambda функции - это отдельная тема для разговора и про неё можно много что сказать, так что углубляться в дебри не будем, а скажу, что это тоже самое, что и функция, только написана в одну строчку. Сравним lambda и def:
lambda функцию вы ВСЕГДА можете заменить аналогичной функцией def, lambda функции используют лишь для того, чтобы не было нагромождение бессмысленных функций и код был более понятен.
Filter
В функция filter принимает следующие параметры: filter (function, iterable), что означает, что он принимает только 2 аргумента - функция и структура данных к которой будет применена фильтрация, то есть выборка элементов, которые удовлетворяют функции. Возвращает итератор, с подходящими под условие (заданное function) элементами iterable
Приведу такой пример: У нас есть сайт, на котором зарегистрированы люди от 0 до 99 лет. Мы хотим узнать сколько людей у нас на сайте старше 50 лет, для этого напишем следующее:
В итоге получим такой результат: [['user1', 90], ['user2', 78]], то есть мы получили те элементы, которые подошли под условие current_user[-1] > 50