Перед вступлением - пост очень длинный, если не втянет - листать придётся долго
Вступление
Стояли у меня некоторые рабочие задачи, и я не задавался вопросом сортировки
Но в рабочем процессе я увидел, что изобретённый мною велосипед - ещё и сортировать умеет
При ближайшем рассмотрении я увидел, что велосипед ещё и едет быстрее, чем Quick Sort
Забегая наперёд, асимптотика алгоритма сортировки по времени - O(log(n^k)), и такого я не смог найти в интернетах
Участники тестирования
- сортировка выборкой, написанная на коленке
- быстрая сортировка (рекурсивная), взятая отсюда https://russianblogs.com/article/6814675765/
- встроенная в PHP функция сортировки, asort
- моя сортировка, так как я пока что не знаю как она называется - имею моральное право, дать ей проектное название - рельсовая сортировка
Ещё есть варианты - индексная сортировка, матричная сортировка, линейная сортировка, разреженная сортировка
Типовая реализация - ссылка https://pastebin.com/ZCEZ5fR6
На гитхабах я не сижу, потому что у меня банально нет на это времени, поэтому пусть будет pastebin
И да, любителям гайдлайнов и "красивого кода" - передаю свой пламенный привет
Предварительно
Победитель по скорости работы - asort, но она только что и делает - сортирует, а значит оптимизирована только на выполнение этой задачи, к тому же встроенная - что для меня не удивительно
В моей работе часто нужно делать что-то ещё помимо сортировки, что показательно - в данном конкретном случае, сортировка мне в принципе была не нужна
Примечание: для реализации моего алгоритма - нужны отрицательные индексы массива, так как значения превращаются в ключи
Знаю что реализовать можно на JavaScript и C# без дополнительных осложнений
А вот для Pascal/Delphi и C/C++ - нужно дополнительно сдвигать все значения на +min если оно отрицательное, и хранить объекты, которым можно назначить состояние отсутствия элементов; да и для таких языков - мой алгоритм под вопросом, так как вычислительная сложность скорее всего будет другой
За другие языки программирования - сказать не могу
Методика тестирования
В цикле генерируется массив случайных чисел в диапазоне [-1000;1000], длинной от 1 до N, где N - исследуемая величина
На каждой итерации - копия массива сортируется каждым алгоритмом, 1 000 раз
N в разных случаях был либо 10 000, либо 3 500
Лимит на единичное выполнение теста алгоритмом - 3 секунды, за это время алгоритм должен отсортировать массив, 1 000 раз
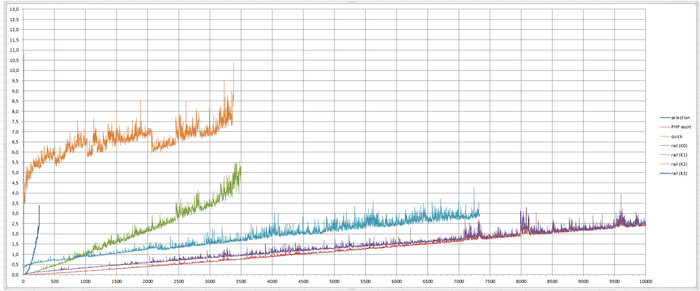
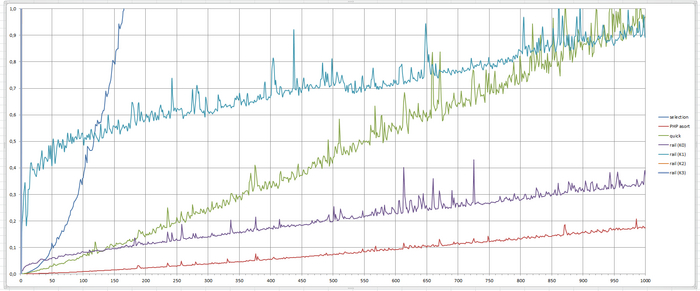
Ниже график, построенный по собранным данным, в Excel
По оси X - количество элементов массива
По оси Y - время выполнения в секундах
Мой алгоритм продолжал тестироваться и после трёх секунд
Потому что дело в отсеивании пиков времени выполнения теста, первопричина - особенность асимптотики логарифма на старте
На старте все тесты несколько раз выбивало от трёх секунд, в первую очередь потому что, иногда происходили эти самые пики
Это можно увидеть, если детально рассмотреть сырые данные тестов
Чтобы данные были более-менее полные, и тесты не отваливались от "ложных" пиков - я настроил чувствительность к пикам
Если текущее время выполнения, минус предыдущее - больше чем 0.1 секунды, то текущее время не проверяется на превышение трёх секунд
В таком виде я настроил это для быстрой сортировки, сортировки PHP asort, и моего алгоритма
Но для моего алгоритма - я настроил ещё и отслеживание верхнего предела пика
Если скачок больше 10 секунд - то тест для моего алгоритма дальше выполняться не будет
Дополнительно: быстрая сортировка, смогла пробиться через 3 секунды, из-за какой-то длительной просадки на сервере, и реальное время перевалило за 3 секунды, поэтому тест продолжился
C одной стороны - можно было бы остановить тест, но с другой стороны показательна тенденция на сокращение разрыва, времени выполнения быстрой сортировки и моей при K=2 - поэтому я не прекращал тест, чтобы это было лучше видно
При K=2 и N=3380 - произошёл очередной пик, переваливший за 10 секунд для моего алгоритма (среднее было 8.5 секунд), и я сократил N до 3 500
Потому что дальше соревновались быстрая и asort - мне вместо этого нужно было хоть что-то вразумительное по длительности проведения всех тестов
Подошёл ко второму параметру K
Цикл от 1 до N - слишком просто, в силу особенностей моего алгоритма, поэтому есть ещё один цикл тестирования, который уже цикл самого верхнего уровня, от 0 до K
Где K - ещё одна исследуемая метрика
Изначально это было количество знаков после запятой (сортировка дробных) - как для генерации массива, так и для моего алгоритма сортировки
Но дальше я понял, что эта метрика по сути означает максимальную величину разброса, между минимальным и максимальным значением элементов массива, другими словами - длина пробега второго цикла у моего алгоритма
И длина этого пробега считается по формуле 10^K*abs(max-min)
Формула немного неправильная, потому что K в данном случае определяет эти самые min и max
Но, точнее - непосредственно перед сортировкой, min и max будут изменены, потому что "так надо", по сути - для сортировки дробных чисел
Для массива с диапазоном генерации [-1000;1000] при K=0, максимальная длина пробега составляет 2 000 раз
При K=1 - 20 000 раз
При K=2 - 200 000 раз
При K=3 - 2 000 000 раз
То есть, величина K - означает порядок пробега второго цикла
В принципе эту величину можно подавать дробным числом, и это даже правильней, но у меня уже нет ни желания ни времени на проведение таких тестов
По имеющимся данным и так примерно ясно что к чему
При K=3 и N=2 - время сортировки уже вывалилось за 10 секунд, так как выполнить даже линейный обход двух миллионов позиций - достаточно накладная задача, хоть и 2 миллиона - это теоретический максимум, что там было на практике - я не знаю
Например для [-500,500] это пол миллиона
Данные для K=2 и K=3 из сырых данных - сразу 10+ секунд, на графике видно хоть и плохо
Встроенная сортировка PHP работает быстрее всех, и так же как быстрая сортировка - зависит только от количества элементов
Но по моему графику - видно, что на большом количестве элементов, разрыв с моим алгоритмом сокращается, и возможно что на какой-то дистанции - asort уйдёт в отрыв по времени выполнения
Теперь вернусь к тому, с чего начал, а начал я с того что это вовсе и не сортировка, изначально
Вот список свойств, перечень преимуществ моего алгоритма
1 - свободные элементы последовательности
2 - информация по уникальным/повторяющимся элементам
3 - собственно сортировка, да - тут она как бы бонусом, и на каких-то диапазонах - работает лучше других рассматриваемых алгоритмов
4 - при сортировке именно в таком виде, повторяющиеся элементы сохраняют изначальный порядок следования для случаев, когда сортировать нужно не просто числа, а такие данные, которые должны сохранить уникальность, и это в работе довольно частое явление
5 - для повторяющихся элементов, можно выполнять вложенную сортировку по другим параметрам, без влияния на другие элементы
Первое свойство - точка отсчёта, когда я реализовал этот алгоритм
Второе свойство - возможно где-то нужны подобные данные
Последние два свойства - мне были нужны как раньше, так и в последствии, в моих рабочих задачах
По тех. части
0 - алгоритм ни в коем случае не "универсальный", особенно если говорить о сортировке; слишком много "но"
1 - сами элементы массива опрашиваются только двумя циклами верхнего уровня
2 - вложенный цикл как вспомогательный для компоновки дубликатов, перебора вложениями и рекурсии тут нет
3 - перемещения элементов внутри массива не происходит
4 - скорость как алгоритма сортировки, зависит не только от размера массива, но и от его содержимого
5 - для обработки дробных, необходимо знать предельную точность чисел, и на выходе все дробные будут урезаны до указанной
6 - вычислительная сложность сортировки, по памяти O(2n), по времени O(log(n^k)) в лучшем среднем и худшем случаях
Отдельно про сложность по памяти - тесты на этот счёт я не проводил, поэтому сложность указал умозрительную
O(2n) это для случая, когда нужно сохранить уникальность элементов
Иначе - картина немного другая
O(n+1) в лучшем случае - все элементы повторяются и хранятся в одной ячейке буфера
O(2n) в худшем случае - все элементы уникальны и полностью переносятся в буфер
Плавно подбираюсь к финишу
Я нигде не нашёл ничего похожего с такой же асимптотикой по времени, а она сохраняет свою логарифмичность, по крайней мере это видно на графиках
Для более правильного представления, нужно рисовать трёхмерный график
И этого я уже не умею, а на онлайн сервисах нет возможности этот график повертеть
В экселе тоже можно строить 3D графики, проблема та же самая - нельзя позиционировать "камеру"
Я хотел было показать хоть что-то по этому поводу, но во первых это сложно, во вторых кому "надо" - тот поймёт, или спросит, а я попытаюсь объяснить по другому
Мне же на данном этапе, достаточно того что при наличии степенной зависимости - алгоритм сохраняет логарифмическую составляющую, а значит что на каких-то дистанциях - оставляет за собой право на существование
А учитывая наличие "бонусов" - так и вообще, алгоритм как минимум интересный
Вот вам график для "типовухи", до 1 000 элементов массива и до 1 секунды
Если пойти дальше, и модифицировать этот алгоритм - можно получить некую вариацию Timsort
Суть идеи в том, что сортировать нужно уже только ключи, любым доступным способом, и даже можно работать с вещественными числами
Но в таком случае - не получится узнать свободные элементы последовательности, а на вещественных числах это может быть даже бессмысленно
Заключение
По описанию - мне что-то напомнило про сортировку Хэна, но при ближайшем рассмотрении - это рокет-сайнс (деревья, хэши, матан)
По сути - чем то похоже на Counting Sort (сортировка количеством), но на практике - количество тут как следствие, а не метод сортировки, само по себе количество нужно очень не всегда, да и чистая Counting Sort в принципе не способна сохранить уникальность и порядок следования, а значит - тоже не то
Оба претендента на сравнение - имеют другие вычислительные сложности
Я не претендую на уникальность, и если такое уже есть - ткните носом
Ещё
Прогуглил пятый вариант названия, как "sparse sort" - нашёл вот что
https://stackoverflow.com/questions/10007463/sorting-in-spar...
Но там по смыслу - не то что у меня, да и тоже что-то сложное
Если всё же такого как у меня, ещё нигде нет - то ну ок, ладно, пользуйтесь
Хоть и не факт что пост вообще стрельнет - уж очень длиннопост получится, плюс специфика вопроса
А я пойду дальше заниматься своими рабочими задачами
P. S. Время проведения тестов - примерно 60 часов процессорного времени, общее время работы - 3 дня с перерывами на другие задачи, и ожидание результатов
Спасибо за внимание