

Беспредел модера Raid
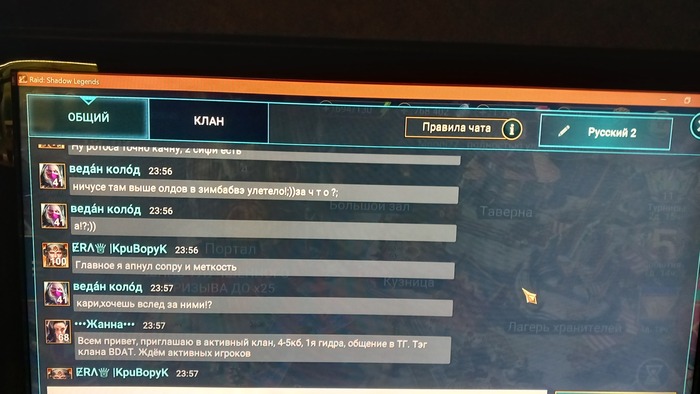
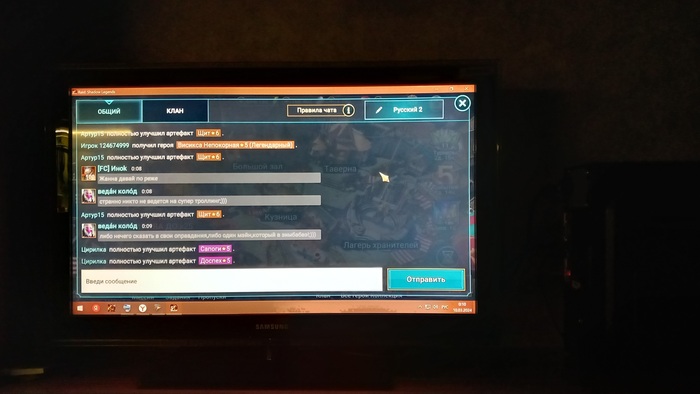
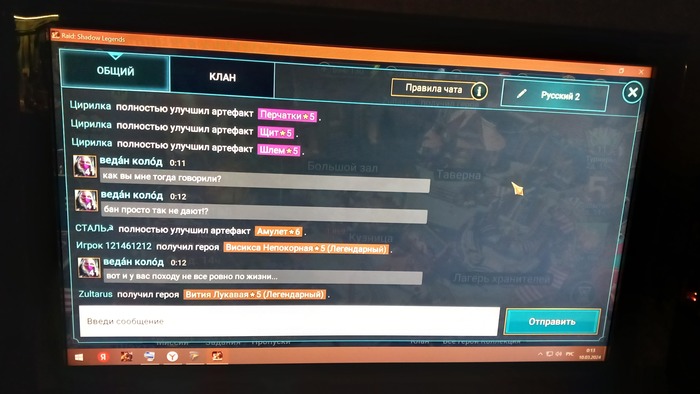
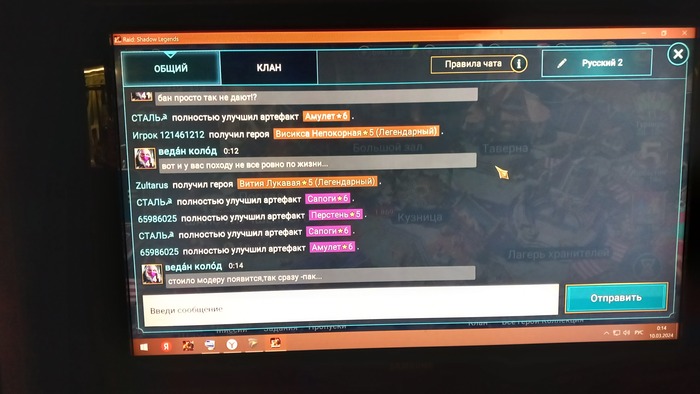
Здравствуйте, друзья. Пишу как есть,сам не писатель. Вот так выглядит "заход" синего модератора на канал игры
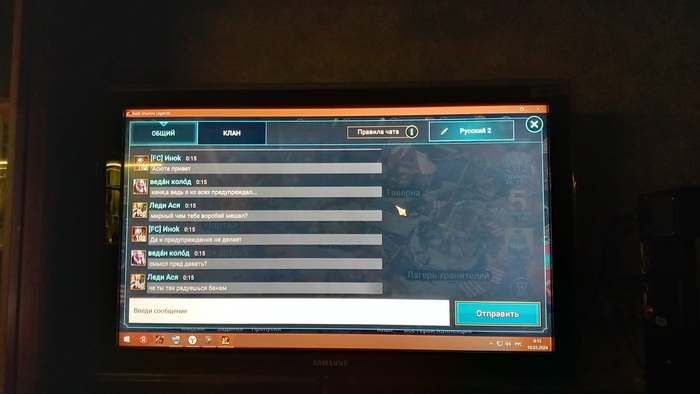
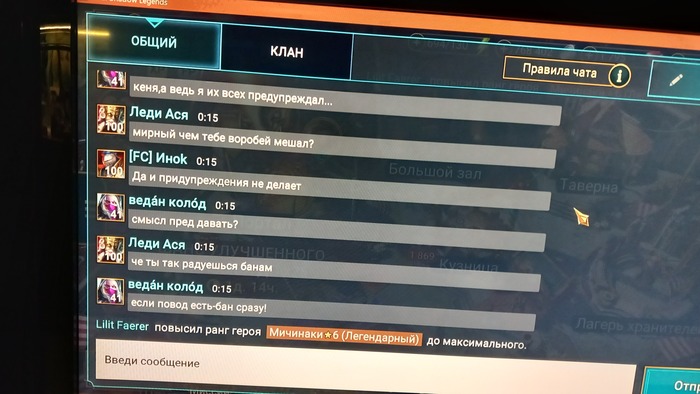
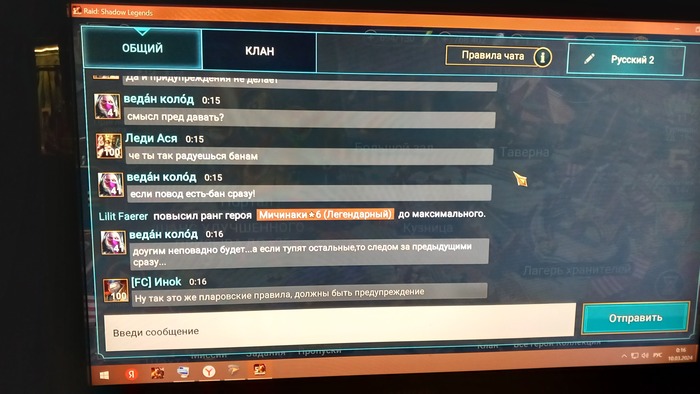
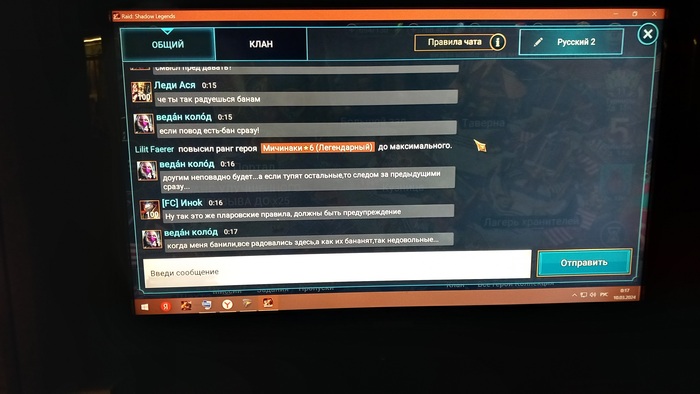
Показать полностью
7
Здравствуйте, друзья. Пишу как есть,сам не писатель. Вот так выглядит "заход" синего модератора на канал игры
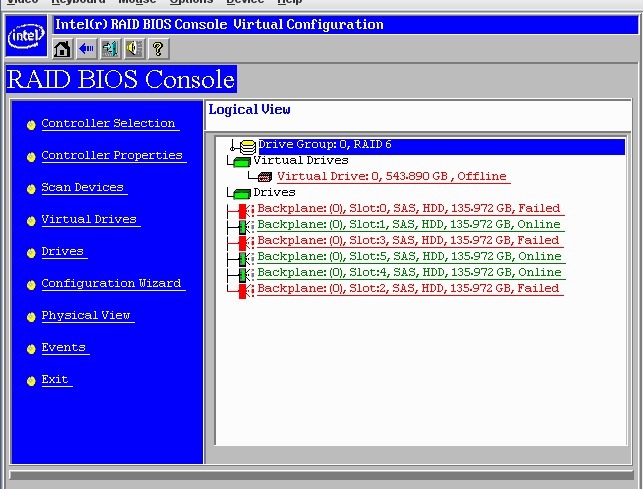
вот такая ситуёвина, подскажите порядок действий, который надо попытаться предпринять? Пока попытался поставить 1й диск в онлайн - Grub прогрузился, но выдал какую-то ошибку. Закинул в оффлайн обратно. =) Бекапы есть, но только ПО, а искать все версии древних RubyOnRails и прочих зависимостей очень не хочется. Поднять бы этот и перенести образ на новые hdd
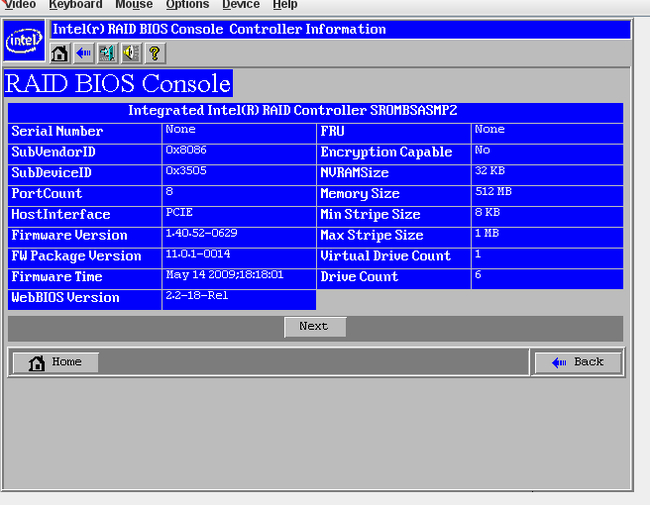
Вводная
Имеется сервер Supermicro (мать X9DRI-LN4+, два проца intel E5-2665, 80 гигов оперативки ECC)
По хардам на борту сервака
2 SSD -512GB -Rair-1 (Windows server 2019 Datacentr)
2 HDD- 2ТБ -Rair-1
2 HDD- 2ТБ -Rair-1
2 HDD- 6ТБ -Rair-1
2 HDD- 6ТБ -Rair-1
2 HDD- 6ТБ -Rair-1
Все дики подключены через Raid контроллер FUJITSU EPRAID EP400i
Суть проблемы
При копировании (перемещении) файлов больше 10-20 гигов сильно падает скорость копирования (практически до ноля) при этом оперативка загружается на 50% (в зависимости от объема перемещаемой информации)
(Так понимаю все данные загружаются в нее) и пока опреративка не освободится сервак ооооочень сильно тупит)
Не приложу ума в чем проблема..
Заранее сообщу все диски новые, ошибок нет, смарт в номе, дефрагментация проведена.
Если кто знает в чем проблема или знает как решить. поделитесь советом
Их есть у нас! Красивая карта, целых три уровня и много жителей, которых надо осчастливить быстрым интернетом. Для этого придется немножко подумать, но оно того стоит: ведь тем, кто дойдет до конца, выдадим красивую награду в профиль!
Как-то встала задача увеличить объем зеркального массива на сервере с Debian без потери данных и без простоев. Простых и кратких инструкций в интернете нашел на тот момент не особо много, в основном на английском. Составил для себя на будущее свою, чем с вами и поделюсь сегодня. Может кому пригодится, всякое случается в практике сисадмина.
0. Посмотреть, какие диски каким именам в каталоге /dev соответствуют, и определиться, что будем менять:
lsscsi //простой список (годится, если все диски разных моделей)
lshw -class disk //подробно и с серийниками
1. Пометить каждый раздел RAID на первом заменяемом диске как извлеченный:
mdadm --manage /dev/mdX --fail /dev/sdYZ
mdadm --manage /dev/mdX --remove /dev/sdYZ
где X - номер массива, соответствующего диску
Y - буква заменяемого диска
Z - номер раздела RAID на этом диске, соответствующий массиву X
2. Заменить первый диск на новый.
3. Создать на новом диске разделы RAID, используя все свободное пространство кроме нескольких последних МБ. Пример:
parted -a optimal /dev/sdY
(parted) mklabel gpt //схема разметки GPT
(parted) mkpart primary 2048s 5999GB //создать раздел размером 5999 ГБ (не ГиБ!), начиная с 2048 сектора
(parted) set 1 raid on //пометить его тип как RAID
(parted) print //вывести список разделов диска для проверки
где Y - буква нового диска (внимание, не спутайте с другим, а то потеряете на нем данные!)
4. Добавить разделы нового диска в соответствующие массивы:
mdadm --manage /dev/mdX --add /dev/sdYZ
где X - номер массива
Y - буква нового диска
Z - номер раздела RAID на этом диске, соответствующий массиву X
5. Подождать окончания синхронизации. Проверка статуса:
cat /proc/mdstat
6. Повторить шаги 0-5 для второго заменяемого и второго нового дисков.
7. Увеличить соответствующие замененным дискам массивы:
mdadm --grow /dev/mdX --bitmap none
mdadm --grow /dev/mdX --size=max
{Подождать окончания синхронизации}
mdadm --grow /dev/mdX --bitmap internal
где X - номер массива
8. Увеличить файловые системы соответствующих из шага 7 массивов:
{остановить зависимые от массива сервисы}
umount /dev/mdX
fsck.ext4 -f /dev/mdX //проверка целостности ФС, для примера указан формат ext4
resize2fs /dev/mdX
mount /dev/mdX
{запустить сервисы}
где X - номер массива
Собственно вопрос. Есть ли утилита, позволяющая контролировать встроенный интеловский RAID на windows server 2022?
Привет всем! Требуется помощь в решении проблемы, пока самому не получается победить.
Есть старенький сервер HP ProLiant ML310e Gen8 v2 на котором стоят два диска в Raid1, диски по 500 Gb HDD. Один из них начал сбоить, возраст 7 лет пора уже. На замену были приобретены 2 SSD на 1Tb. При попытке замены на горячую с последующем ребилдом контроллер выдает вот это: 274: 960 GB SATA SSD at Port 4: Bay 4 is bad or missing. To correct this problem, check the data and power connections to the physical drive.For more information, generate s diagnostics report. При это все характеристики диска видны вплоть до серийного номера на статус стоит Failed.
Ладно решил пойти другим путем, сделал клонирование HDD на SDD, но результат такой же сервер даже не стартует. Кто сталкивался с подобным как решали данную проблему?
P.S. Приобрести новые HDD никто не даст ибо деньги потрачены на SSD.

Доброго дня!
Попался мне в руки сервер, новый.
В нем рейд контроллер, за 80 тысяч.
4 SAS SSD диска.
Есть примерно неделя времени, хотелось бы настроить чтобы диски работали быстро.
Есть какие инструкции, как это сделать?
Можно тестировать как хочется... Если есть предложения как - выслушаю, и сделаю.
Что я узнал, по результатам тестирования в LINUX за вчера:
0) Я нифига не понимаю в этом.
1) Аппаратный рейд, и софтовый с JBOD дисками - разницы по скорости почти нет. Незначительно.
2) ZFS с дисками в режиме JBOD - скорость падает примерно в 30 раз.
3) Скорость чтения с файловой системы TMPFS(из памяти) раза в полтора выше, чем с SSD
4) есть еще тесты с обычными SAS дисками, скорость одного диска не сильно отличается от скорости рейда.
5) В винде скорость дисков вообще ниочем. Знаток винды их конфигурил, менял драйвера, оптимизация какая-то... В общем диски медленнеее чем в стандартном линуксе раза в два.
6) Есть другой raid контроллер, сильно дешевле. С ним скорость дисков раза в два меньше, чем с этим дорогим.
7) При работе с дисками грузится только одно ядро процессоров (процов два, всего 64 ядра с HT).
Ну и: скорость рейда по IOPS -ам выдается примерно 75% от того что по таблице характеристик должна быть.
Я так считал, что рейд должен быть быстрее одного диска, но по результатам моего тестирования это не совсем так.
Отсюда вопрос:
1) Как сделать быстрый дисковый массив?
2) Какие еще тесты проделать, чтобы понять во что я утыкаюсь?
Собственно сами тесты, что делал я:
time dd if=/dev/random bs=1G count=50 of=random.file
time dd if=/dev/random bs=1G count=250 of=random.file
fio /root/read.ini
на 32 и 64 потока. С файлом random.file меньше размера оперативки, и в два раза больше. (разница есть, но незаметная)
Могу обсчитать статистику по стьюденту или хи квадрату, при желании. Но хотелось бы, чтобы разница в скорости была заметна на глаз.
Ну что, потренировались? А теперь пора браться за дело всерьез.




