


9 лучших практик разработки микросервисов
источник https://t.me/itmozg/9693
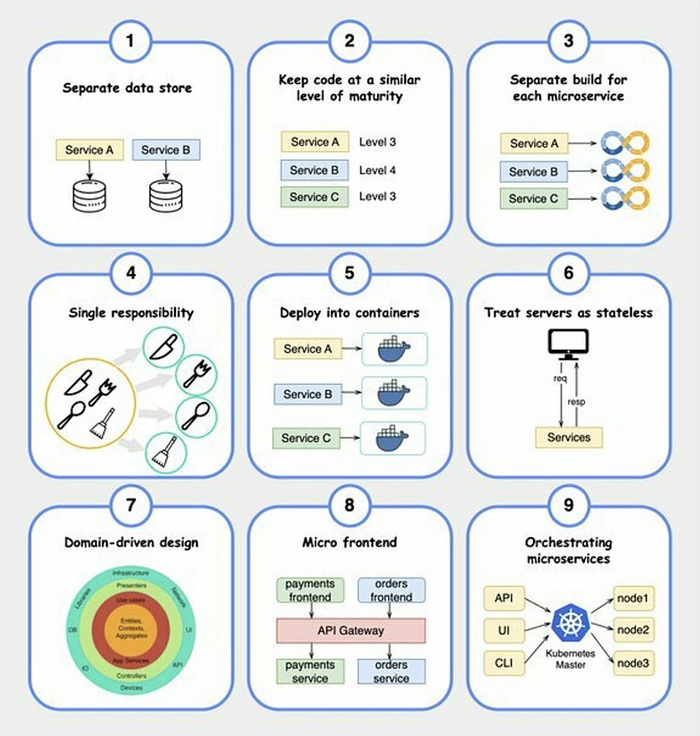
Показать полностью
1
источник https://t.me/itmozg/9693
Данный пост не претендует на полноту предоставленной информации.
Все действия выполняете на свой страх и риск.
Для понимания поста требуются минимальные знания в администрировании Linux.
Сегодня мы рассмотрим наполнение локального Docker Registry, установку кластера Kubernetes и установку Rancher для K8s. Установка Kubernetes будет производится с помощью утилиты Rancher Kubernetes Engine (RKE).
Погнали!
Данная инструкция написана для такой схемы:
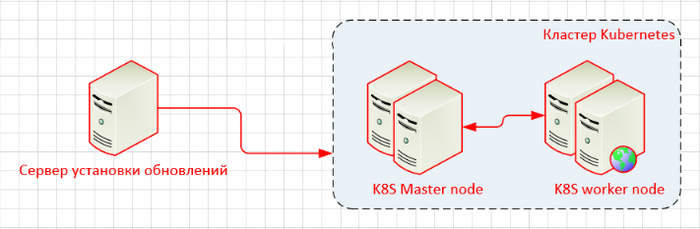
Состав компонентов: Сервер установки обновлений (далее СУО) – 1 шт., Мастер нода – 3 шт., Воркер нода – 3 шт.
Начнём настройку хостов, тут все просто. На все хосты установим Docker и отключим swap:
apt install docker docker.io
# или
yum install docker docker.io
swapoff -a
nano /etc/fstab
#/swap.img none swap sw 0 0
Затем добавляем вашего текущего пользователя в группу Docker:
sudo usermod -aG docker <Имя_Вашего_пользователя>
В моём примере Docker не будет использовать авторизацию, поэтому на всех хостах создаем файл daemon.json:
nano /etc/docker/daemon.json
Со следующим содержимым:
{
"data-root": "/opt/docker-data", # В моем случае /opt это примонтированный диск
"insecure-registries" : ["<FQDN_СЕРВЕРА_УСТАНОВКИ_ОБНОВЛЕНИЙ>:5000"]
}
Включаем автозагрузку Docker и запускаем его:
systemctl enable docker
systemctl start docker
Теперь необходимо на хостах кубера создать учетную запись rke (для удобства), добавить её в группу docker и настроить доступ с СУО до хостов кубера по SSH ключу.
Теперь загружаем в локальный Docker Registry необходимые образы. Для пакетной загрузки образов можно использовать скрипт из статьи Сохранение и загрузка нескольких Docker образов.
Список образов (так же они будут использоваться в будущих статьях):
rancher/mirrored-coreos-etcd:v3.5.3
rancher/rke-tools:v0.1.80
rancher/mirrored-k8s-dns-node-cache:1.21.1
rancher/mirrored-k8s-dns-dnsmasq-nanny:1.21.1
rancher/mirrored-k8s-dns-sidecar:1.21.1
rancher/mirrored-cluster-proportional-autoscaler:1.8.5
rancher/mirrored-coredns-coredns:1.9.0
rancher/hyperkube:v1.23.6-rancher1
rancher/mirrored-coreos-flannel:v0.15.1
rancher/flannel-cni:v0.3.0-rancher6
rancher/mirrored-calico-node:v3.22.0
rancher/mirrored-calico-cni:v3.22.0
rancher/mirrored-calico-kube-controllers:v3.22.0
rancher/mirrored-calico-ctl:v3.22.0
rancher/mirrored-calico-pod2daemon-flexvol:v3.22.0
rancher/mirrored-flannelcni-flannel:v0.17.0
weaveworks/weave-kube:2.8.1
weaveworks/weave-npc:2.8.1
rancher/mirrored-pause:3.6
rancher/nginx-ingress-controller:nginx-1.2.0-rancher1
rancher/mirrored-nginx-ingress-controller-defaultbackend:1.5-rancher1
rancher/mirrored-ingress-nginx-kube-webhook-certgen:v1.1.1
rancher/mirrored-metrics-server:v0.6.1
noiro/cnideploy:5.1.1.0.1ae238a
noiro/aci-containers-host:5.1.1.0.1ae238a
noiro/opflex:5.1.1.0.1ae238a
noiro/openvswitch:5.1.1.0.1ae238a
noiro/aci-containers-controller:5.1.1.0.1ae238a
noiro/gbp-server:5.1.1.0.1ae238a
noiro/opflex-server:5.1.1.0.1ae238a
rancher/rancher-agent:v2.6.5
rancher/rancher-runtime:v2.6.5
rancher/rancher-webhook:v0.2.5
rancher/rancher:v2.6.5
rancher/webhook-receiver:v0.2.5
rancher/shell:v0.1.16
rancher/fleet:v0.3.9
rancher/gitjob:v0.1.26
rancher/fleet-agent:v0.3.9
Продолжаем настройку СУО. Установим необходимые утилиты, а именно: kubectl, rke и helm. Версии из статьи этих утилит можно взять в репозитории GitHub, папка bin.
Копируем файлы в папку /tmp на СУО и выполняем следующие команды:
cd /tmp
# Установка RKE
cp /tmp/rke_linux-amd64 /usr/local/bin/rke
chmod +x /usr/local/bin/rke
# HELM
tar -zxvf helm-v3.8.2-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin/helm
# KUBECTL
cp /tmp/kubectl /usr/local/bin/
chmod +x /usr/local/bin/kubectl
На СУО создаем папку /opt/rke и в ней создаем файл cluster.yml со следующим содержимым:
nodes:
- address: <FQDN_кубер_мастер_1>
user: rke
role: ['controlplane', 'etcd']
- address: <FQDN_кубер_мастер_2>
user: rke
role: ['controlplane', 'etcd']
- address: <FQDN_кубер_мастер_3>
user: rke
role: ['controlplane', 'etcd']
- address: <FQDN_кубер_воркер_1>
user: rke
role: ['worker']
- address: <FQDN_кубер_воркер_2>
user: rke
role: ['worker']
- address: <FQDN_кубер_воркер_3>
user: rke
role: ['worker']
private_registries:
- url: <АДРЕС_ЛОКАЛЬНОГО_REGISTRY:ПОРТ>
is_default: true
Теперь все готово для установки k8s кластера. Выполняем следующие команды:
cd /opt/rke
rke up
После выполнения rke up в папке /opt/rke появятся два файла (cluster.rkestate и kube_config_cluster.yml). Эти файлы важны и они потребуются для дальнейшей работы с кластером. Теперь давайте проверим статус кластера:
export KUBECONFIG=/opt/rke/kube_config_cluster.yml
# получения статуса нод
kubectl get nodes
На этом установка кластера Kubernetes закончена. Теперь давайте установим Rancher.
Для установки Rancher необходимо доменное имя и SSL сертификат для данного доменного имени. Сертификат должен быть в виде двух файлов .crt и .key. Они понадобятся позже.
На СУО создаем временную папку /tmp/rancher. В эту папку копируем файл rancher-2.6.5.tgz (доступен в папке bin в GitHub). Далее выполняем следующие команды:
cd /tmp/rancher/
helm template rancher ./rancher-2.6.5.tgz --output-dir . \
--no-hooks \
--namespace cattle-system \
--set hostname=<ДОМЕННОЕ_ИМЯ_RANCHER> \
--set rancherImage=<АДРЕС_ЛОКАЛЬНОГО_REGISTRY:ПОРТ>/rancher/rancher \
--set ingress.tls.source=secret \
--set systemDefaultRegistry=<АДРЕС_ЛОКАЛЬНОГО_REGISTRY:ПОРТ> \
--set useBundledSystemChart=true
export KUBECONFIG=/opt/rke/kube_config_cluster.yml
kubectl create namespace cattle-system
kubectl -n cattle-system create secret tls tls-rancher-ingress \
--cert=tls.crt \
--key=tls.key
kubectl -n cattle-system apply -R -f ./rancher
Терминал не закрываем.
Теперь через браузер заходим по адресу https://<ДОМЕННОЕ_ИМЯ_RANCHER>
При первом входе будет выведено сообщение, что нужно ввести пароль для дальнейшей настройки. Там же будет команда которую надо выполнить на СУО (для этого мы и не закрывали терминал). Результатом выполнения команды будет временный пароль. Этот пароль и нужно ввести в веб интерфейсе.
Теперь можно задать свой пароль для учётной записи admin.
На этом настройка Rancher закончена.
Обсудить эту заметку можно в нашем Телеграм канале: https://t.me/devops_spb_ru (@devops_spb_ru)
Сегодня предлагаю разобрать следующий по списку объект Kubernetes, а именно Deployment.
Команда для создания deployment выглядит так:
kubectl create deployment DEPLOYMENT_NAME --image IMAGE_NAME
Чтобы посмотреть список созданных deployment:
kubectl get deployments
Как и у Pods, у deployments есть команда для отображения подробной информации:
kubectl describe deployments DEPLOYMENT_NAME
Для скейлинга деплоймента можно использовать такую команду:
kubectl scale deployment DEPLOYMENT_NAME --replicas NUM_OF_REPLICAS
Для проверки, что команда сработала вводим:
kubectl get pods
После скейлинга можно посмотреть параметр replica set:
kubectl get rs
Эта команда выводит информация о количестве подов, которые должны быть запущены в деплойменте.
И теперь, если вы удалите Pod, то он автоматически перезапустится. Таким образом Deployment всегда будет поддерживать количество работающих подов, которое было указано при скейлинге.
Так же можно сделать автоскейлинг:
kubectl autoscale deployment DEPLOYMENT_NAME --min=MIN_NUM_REPLICS --max=MAX_NUM_REPLICAS --cpu-percent=CPU_PERCENT_NUM
Команда для проверки:
kubectl get hpa
Deployment также можно создать с помощью YAML файла. С минимально необходимым YAML файлом вы можете ознакомиться в моем GitHub`е.
И для запуска deployment через yaml файл используется вот такая команда:
kubectl apply -f FILE_NAME.yaml
Для удаления deployment есть команда delete:
kubectl delete deployments DEPLOYMENT_NAME
Посмотреть историю обновлений:
kubectl rollout history deployment/DEPLOYMENT_NAME
Команда для обновления вот такая:
kubectl set image deployment/DEPLOYMENT_NAME CONTAINER_NAME=UPDATED_CONTAINER_NAME --record
Для просмотра статуса обновления:
kubectl rollout status deployment/DEPLOYMENT_NAME
А как откатить последнее выполненное обновление? Легко:
kubectl rollout undo deployment/DEPLOYMENT_NAME
Можно откатиться на любую ревизию:
kubectl rollout undo deployment/DEPLOYMENT_NAME --to-revision=REVISION_NUM
Как обновиться, если вместо версии вы ранее указали latest? Вот так:
kubectl rollout restart deployment/DEPLOYMENT_NAME
Обсудить эту заметку можно в нашем Телеграм канале: https://t.me/devops_spb_ru (@devops_spb_ru)
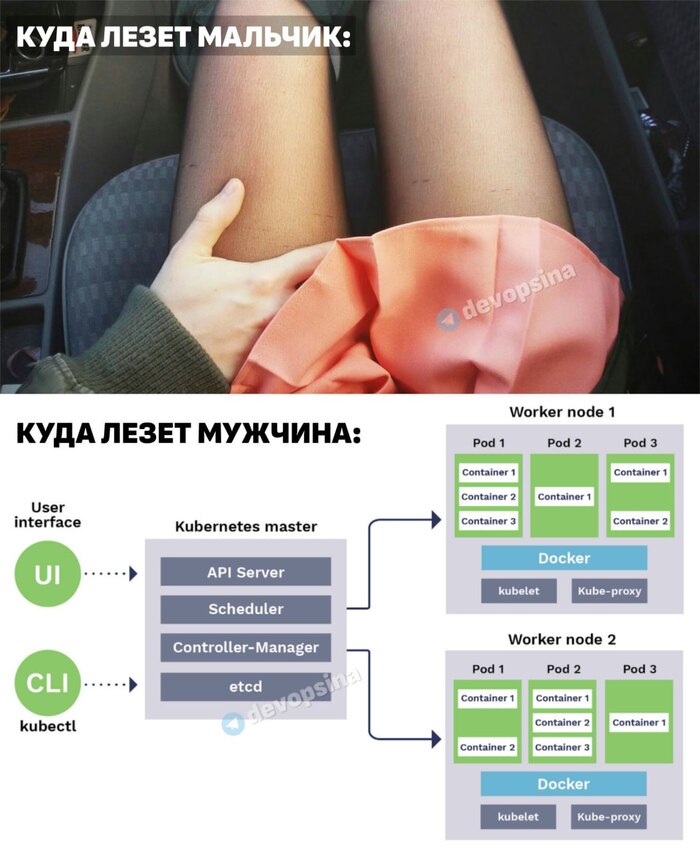
K8s – это opensource проект разработанный Google на языке Go, изначально разрабатывался для своих же приложений. Первая версия вышла в 2014 году. Kubernetes предназначен для контейнеризированных приложений.
Прежде чем изучать Kubernetes я рекомендую ознакомиться с темой про Docker!
Основные «фишки» Kubernetes:
Автоматизация развертывания приложений
Автоматизация масштабирования приложений
Автоматизация управления приложениями
Основной компонент Kubernetes это Cluster.
Вы создаете Kubernetes Cluster состоящий из Nodes.
Nodes существуют двух типов:
Worker Node – сервер на котором запускаются и работают контейнеры.
Master Node – сервер который управляет Worker Nodes.
Когда вы запускаете команды управления, они всегда посылаются на Master Node. Напрямую с Worker Node вы не взаимодействуете.
На Kubernetes Master Node работают три главных процесса k8s:
kube-apiserver
kube-controller-manager
kube-scheduler
На Kubernetes Worker Node работают два главных процесса k8s:
kubelet
kube-proxy
Обычно в Kubernetes кластере запущена одна Master нода (две и более нод используют для высокодоступных вариантов кластера) и одна Worker нода. Это самый минимальный набор для кластера.
Service discovery and load balancing. Вы запустили один Docker контейнер в k8s кластере. K8s дает вам доступ к этому Docker контейнеру через ip адрес, через определенный порт на любой Worker через определенный порт на любой Worker ноде или через DNS имя, также если вы запустили несколько копий вашего Docker контейнера, то k8s сделает load balancing между этими контейнерами.
Storage orchestration. Вы можете присоединить любой локальный диск или диск из AWS, GCP или Azure к одному или нескольким Docker контейнерам.
Automated rollouts and rollbacks. Автоматическое обновление на новую версию Docker Image или возврат на предыдущую версию.
Automatic bin packing. Вы создаете k8s кластер, где Kubernetes может запускать Docker контейнеры. Вы указываете сколько процессоров и оперативной памяти нужно каждой копии этих контейнеров, а k8s уже сам решит на каких Worker Node их лучше запускать.
Self-healing. Вы указываете сколько копий Docker контейнеров вам нужно и если с контейнером что-то произошло (завис, просто не отвечает и т.д.), то k8s это исправляет.
Secret and configuration management. K8s позволяет вам хранить «секреты», например пароли или любую секретную информацию все ваших приложений в Docker контейнере.
На этом тезисное знакомство с кубером можно считать законченным. В следующих заметках мы будем поднимать локальный k8s кластер, создавать Docker Images и еще раз пройдемся по основным понятиям k8s.
Обсудить эту заметку можно в нашем Телеграм канале: https://t.me/devops_spb_ru (@devops_spb_ru)
Эта статья навеяна комментарием к предыдущей.

В предыдущей статье мы уже разбирали как работает обратный прокси, но повторение будет не лишним.
Обратный прокси можно в какой-то мере ассоциировать с старой телефонной станцией. Когда кто-то хочет воспользоваться телефоном, он сначала соединяется с коммутационным узлом, и общается с живым оператором, называя тому имя и адрес человека, которому нужно позвонить. После чего оператор соединяет звонящего с абонентом (при условии доступности второго).
Обратный прокси делает похожую работу, получая пользовательские запросы, и затем пересылая эти запросы на соответствующие сервера (как показано на картинке ниже).
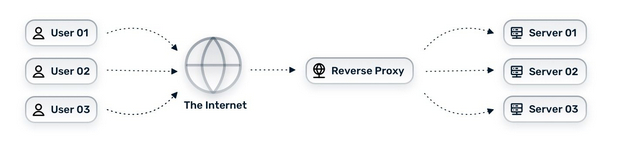
У обратного прокси очень простая функция - он ставится перед приложением (или группой приложений), и служит посредником между пользователем и сервисом.
Как упомянуто выше, обратный прокси маршрутизирует пользовательские запросы на соответствующий сервер (при условии, конечно, что вы используете несколько серверов). На этом месте те, кто использует один сервер с одним экземпляром приложения, вполне справедливо зададутся вопросом, имеет ли вообще смысл внедрять обратный прокси-сервер. Ответ: да, смысл есть.
Обратный прокси будет полезен и в инсталляциях с одним сервером, за счёт предоставления таких своих преимуществ как: ограничение скорости, IP-фильтрация и контроль доступа, аутентификация, проверка запросов и кэширование.
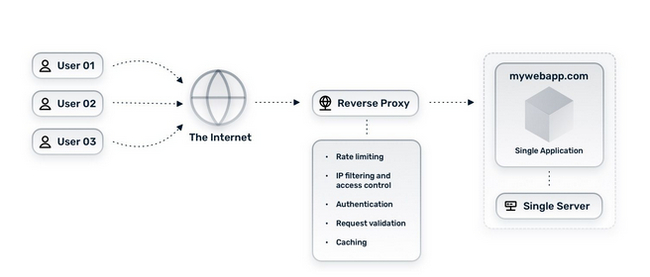
Если в двух словах, то в мире Kubernetes ingress контроллер является обратным прокси (кстати именно поэтому тот же Istio в прошлой статье был упомянут в контексте перечисления вариантов обратных прокси).
Он действует по принципу обратного прокси, маршрутизируя трафик из внешней сети к целевому сервису в пределах кластера Kubernetes, и позволяя вам настроить балансировщик нагрузки HTTP и HTTPS для кластера.
Чтобы лучше понять принцип работы, давайте сделаем шаг назад и попробуем разобраться, что такое Ingress.
Kubernetes Ingress - это объект API, задача которого определять как приходящий трафик из интернета будет направляться на внутренние сервисы кластера, которые затем в свою очередь будут отправлять запросы Pod'ам. Сам по себе Ingress не имеет влияния на систему, представляя собой просто набор правил для Ingress контроллера. Для проведения аналогии можно сравнить Ingress с автомобилем, у которого снят двигатель, а Ingress контроллер с самим двигателем, то есть при наличие Ingress ресурса, без установленного контроллера, работать ничего не будет.
Ingress контроллер принимает трафик снаружи Kubernetes платформы, и распределяет его по Pod'ам внутри платформы, таким образом накладывая еще один уровень абстракции на маршрутизацию трафика. Контроллеры Ingress преобразуют конфигурации из ресурсов Ingress в правила маршрутизации, распознаваемые и реализуемые обратными прокси-серверами.
Обычно Ingress контроллеры используются для предоставления доступа к множеству сервисов через единую точку входа (DNS-имя или IP-адрес).
В частности, входные контроллеры используются для:
предоставления нескольких служб под одним DNS-именем
реализации маршрутизации на основе пути, при которой разные URL-адреса сопоставляются с разными службами
реализации маршрутизации на основе хоста, при которой разные имена хостов сопоставляются с разными службами
реализации базовой аутентификации, или других методы контроля доступа для ваших приложений.
включения ограничения скорости для ваших приложения
Если ingress контроллер делает практически ту же самую работу, что и обратный прокси (обрабатывает входящий трафик и перенаправляет на соответствующий сервер/сервис), то чем они отличаются?
Ingress контроллер - это частный случай прокси-сервера, предназначенный для работы в кластерах Kubernetes. Он находится не на границе инфраструктуры, а на границе кластера.
Доброго дня! Может кто уже сталкивался и как то решил. Зависает запуск minikube

Авторские IT мемы здесь: @devopsina
Перевод очень интересной статьи "How to Build Software like an SRE", в которой разбираются подходы к созданию приложений с точки зрения SRE.
Принципы надежности и компромиссы, усвоенные на собственном горьком опыте
Я занимаюсь этой “надежностью” уже некоторое время (около 5 лет), в компаниях, насчитывающих от 20 до более чем 2000 человек. Меня всегда в первую очередь всегда интересовали те элементы ПО, которые я описываю как живущие “вне” приложения — например, как приложение получает свою конфигурацию? На каких типах серверов оно запускается и являются ли эти типы наиболее подходящими? Что с ним происходит на пути от “кода в репозитории” до “запуска на проде”? И я всегда следил за тем, что мне нравится — какие механизмы позволяют быструю итерацию, а какие вызывают разочарование, какие приводят к сбоям, а какие предотвращают их.
Я думаю, что будет полезно, если я все это запишу, даже если это будет просто для меня в качестве справочника.
Обратите внимание, что этот список немного странный с точки зрения SRE. Моя цель не заключается в том, чтобы “построить все так, чтобы надежность была 100%”; это больше похоже на “как достичь 80% надежности, затратив 20% усилий, при этом позволяя разработчикам работать быстро”, что в конечном итоге дает нам систему, которая выглядит совсем по-другому. Но это стоит попробовать — если делать это хорошо, работа с продом становится интересной, а не уныло безопасной или ужасающе опасной.
Также, пожалуйста, сделайте мне одолжение и мысленно дополните каждый из следующих пунктов словом “обычно”. Каждая ситуация уникальна, и то, что я не сталкивался с тем, что (например) использование Git является плохой идеей, не означает, что такого случая не существует. “Только Ситхи всё возводят в абсолют”, и т.д.
Итак! Пройдя через всё это — вот как я бы начал все сначала, если бы мог.
Никаких конфигов, зашитых в код. Если ваш сервис по какой-либо причине не может загрузить конфигурацию при запуске, он должен просто аварийно завершиться — этот случай гораздо проще диагностировать, чем результат того, что инстанс выполнил старый код, потому что никто не вспомнил о том, что нужно удалить строку config.get(enable_cool_new_thing, false).
Чрезвычайно строгие настройки RPC. Я говорю о нуле (или МОЖЕТ БЫТЬ одной) повторных попыток и таймауте, в 3 раза превышающем p⁹⁹. Здесь мы стремимся к предсказуемости, и многократные повторные попытки или длительные таймауты в качестве быстрого решения проблемы в работе сервиса превратятся в недельное расследование и головную боль через год. Исправьте неисправный сервис!
Никогда не отказывайтесь от локального тестирования. Это значительно сокращает время цикла разработки, чем необходимость полагаться (и возиться с этим) на CI или удаленные рабочие среды. Контейнеризация локальной тестовой среды может упростить управление зависимостями и обеспечить их переносимость между машинами.
Избегайте использования состояния как чумы. Управление сервисом с сохранением состояния (stateful) значительно сложнее, чем без сохранения состояния. Существует много хороших управляемых баз данных и кэшей, просто используйте один из них!
Используйте Git. Используйте его для всего — инфраструктуры, конфигов, кода, дашбордов, графиков дежурств. Ваш репозиторий Git — это источник истины, который можно восстановить на определенный момент времени.
Не тратьте время на полное покрытие кода тестами. И вообще, не занимайтесь “расстановкой галочек” — это только для красивых графиков и диаграмм, которые имеют очень мало общего с тем, какую фактическую ценность дает ваше изменение (см. ниже).
Уделяйте приоритетное внимание тестам в реальных условиях. Самый ценный тест, который занимает меньше всего времени, — это просто применение вашего изменения на стейджинге (или, еще лучше, на проде!) и демонстрация того, что оно делает то, что вы хотели, и не ломает всё. На втором месте по эффективности находятся интеграционные тесты, а юнит-тесты идут последними — то есть, “только если у вас есть на них время”.
При изменениях в инфраструктуре делайте планы максимально ясными и очевидными. Это может означать “положить Terraform Plan как коммент к пуллреквесту”, так же сделайте с diff helm. Существуют отличные инструменты, позволяющие убедиться, что изменения, которые, по вашему мнению, вы вносите, являются теми изменениями, которые вы вносите на самом деле, поэтому убедитесь, что они находятся в центре внимания.
При внесении изменений в код делайте регрессии максимально очевидными. Журналы ошибок, использование ЦП и частота ошибочных запросов являются отличными сигналами, позволяющими выявить около 90% плохих версий и работают для практически любого сервиса (полностью универсальны). Так что не отбрасывайте их!
Используйте Docker. Это отраслевой стандарт не просто так — разбор зависимостей в средах с такими инструментами, как Chef или Ansible, всегда проигрывает этой приятной автономности.
Развертывайте всё и всегда. Каждый день, который проходит без вашего деплоя, увеличивает вероятность того, что он на самом деле был незаметно сломан (в результате чьего-то изменения, обновления зависимостей, удаления стороннего API), и через две недели будет очень трудно выяснить, что и где пошло не так.
Проверяйте развертывания по мере их выполнения. Можете ли вы создать полностью поврежденный образ и успешно разлить его на все машины? Почему? Это можно исправить несколькими способами, включая canary/shadow развертывания или даже просто хорошими readiness проверками.
Включите ограничение на “мгновенное” развертывание конфигов. Это может показаться нелогичным (“мгновенное” часто означает “сломать все сразу и быстро”), но возможность отключить проблемную функцию или заблокировать IP менее чем за 5 минут с лихвой компенсирует повышенный риск. Это позволяет всё делать быстро, но управлять этим нужно осторожно!
Используйте Kubernetes. Предполагая, что у вас есть более одного сервиса и более одного инстанса, вам либо нужны, либо будут нужны такие вещи, как обнаружение сервисов, автоматическое масштабирование и управление версиями развертывания, и вы не хотите управлять всем этим самостоятельно. Kubernetes дает командам инфраструктуры сверхспособности масштабирования.
Используйте Helm. Или какой-то другой инструмент для управления манифестами Kubernetes, я не привередлив — главное, чтобы вы никогда не использовали прямые команды kubectl apply, edit или delete. Жизненный цикл ресурсов должен быть доступен в системе контроля версий.
Избегайте операторов и CRD (Custom Resource Definition). Как уже упоминалось выше, я люблю Kubernetes, но для очень многих разработчиков он очень сложен, и пользовательские операторы резко уходят в область “Что это за херня?”, что создает ему сложную репутацию. Пусть все будет просто.
Запускайте по 3 экземпляра всего. Как и с резервными копиями, два экземпляра — это один, а один — не существует :) Кроме того, убедитесь (действительно проверьте на проде), что 2 из 3 “штук” могут справиться с полной нагрузкой самостоятельно — в противном случае у вас на самом деле нет такой устойчивости к сбоям, как вы думаете.
Структурированные логи — это неотъемлемая часть. Вместе с идентификаторами трассировки они позволяют вам пройти 90% пути к APM (application performance monitoring), но при гораздо меньших затратах и усилиях со стороны разработчиков.
Итак, это текущий список! Думаю, что буду периодически возвращаться сюда и добавлять что-то еще. Пожалуйста, не стесняйтесь обращаться ко мне, если что-то из этого особенно вас раздражает или если у вас есть ещё что-то, о чем бы вы хотели бы поговорить 😜






