Как стать компьютерным донором
Как стать компьютерным донором
Ученые из Института проблем передачи информации РАН внедряют в общество новую технологию: использование ресурсов персональных компьютеров обычных граждан для сложнейших вычислений научных проектов. При этом пользователи самостоятельно выбирают проекты, которым они хотят помочь, опираясь исключительно на презентацию проекта в сети и репутацию их авторов. Время, когда ученые должны убедить людей в важности их работы, рассказывая о ней понятным человеческим языком, наконец-то настало!
О новой технологии и о том, как принять участие в проекте ученым и интернет-пользователям, нам рассказал ведущий научный сотрудник Института проблем передачи информации РАН, председатель российского отделения «International Desktop Grid Federation» Михаил Посыпкин.
Михаил, в чем состоит идея добровольной помощи науке через персональные компьютеры?
http://desktopgridfederation.org/
Идея состоит вот в чем. Когда вы работаете на своем компьютере ― с документами или в интернете ― ваш компьютер, как правило, загружен только на некоторую часть своей мощности, обычно не больше 5-10 процентов. В этом легко убедиться, открыв монитор производительности при помощи комбинации клавиш «ctrl-alt-del» и активации соответствующего пункта списка. Я уже не говорю про те ситуации, когда компьютеры включены, но за ними никто не работает ― например, обеденные перерывы. Также нередко компьютеры оставляют включенными на ночь, и они «работают вхолостую». А любой свободный ресурс, будь то центральный процессор, оперативная или дисковая память, может быть предоставлен ученым для выполнения полезных и нужных науке и обществу расчетов. Так как понятие «износ ресурса» в данном случае практически отсутствует, то предоставляя свободную мощность своего ПК для расчетов, пользователь практически ничего не тратит.
Как интернет-пользователи могут принять участие в таком проекте?
Предоставить ресурс своего компьютера кому-либо можно при помощи сети интернет и технологии «Грид-систем из персональных компьютеров» (ГСПК). Существует несколько систем для добровольных вычислений. Это BOINC, XtremeWeb-HEP, OurGrid, Condor и другие. Наиболее популярная и занимающая сейчас практически весь сегмент добровольных вычислений ― система BOINC.
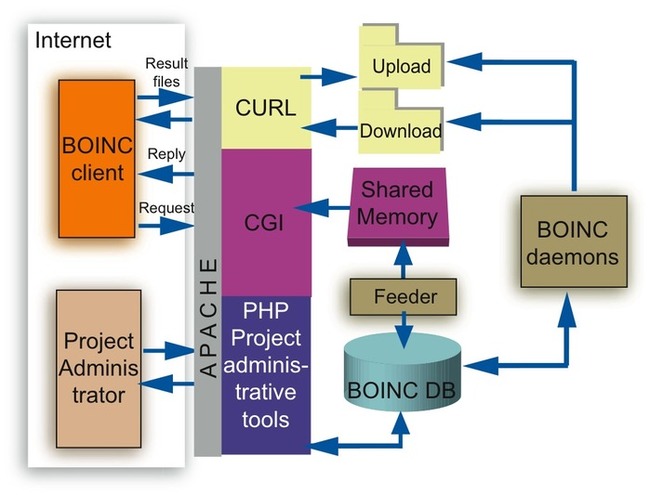
Пользователь, который желает помочь развитию науки, просто подсоединяется к заинтересовавшему его научному проекту, список которых есть на сайте системы. Для этого на своем компьютере необходимо установить специальную программу ― клиентскую часть системы BOINC, это очень легко. После чего пользователь может указать адрес одного или нескольких проектов, в которых он решил принимать участие. Далее клиент подключается к серверу проекта, и на компьютер пользователя по сети начинают поступать и выполняться задания. Другими словами, с сайта проекта на ПК пользователя скачивается исполняемый файл приложения, затем скачиваются исходные файлы с данными, которые нужно обработать. После этого, как правило, запускается несколько экземпляров приложения с соответствующими входными данными. Каждый файл входных данных называется «Work unit» ― расчетный блок. Задача, решаемая в проекте, содержит обычно достаточно большое число таких блоков. После обработки расчетного блока формируется файл результата, который отсылается обратно на центральный сервер проекта. Далее задача сервера ― обработать результаты, полученные от пользователей. Он должен свести их воедино и предоставить информацию конечному потребителю ― автору проекта.
Схема работы программного обеспечения BOINC
Кстати об авторах проектов. Что нужно ученому, чтобы организовать свой проект добровольных вычислений?
Ну, во-первых, иметь компьютер и постоянное подключение к интернету. Это не обязательно должен быть мощный сервер, достаточно недорогого сервера самой простой конфигурации. Причем этот компьютер должен иметь внешний IP –адрес, что делает доступным подключение клиентов из любого конца планеты. Как правило, с получением сервера и внешнего IP-адреса в научных учреждениях проблем не возникает.
Затем автор проекта должен установить на этом сервере программное обеспечение BOINC. Необходимое обеспечение и документация разработчика имеется на сайте BOINC. Это несколько программ, которые будут периодически запускаться на данном сервере. Серверное обеспечение BOINC будет эти программы вызывать и запускать. Их задача как раз - сформировать работу, раздаваемую клиентам – донорам ресурсов, а затем обработать полученные результаты.
Затем ученому необходимо собственно разработать и запрограммировать BOINC-проект. Ведь поскольку речь идет о конкретной задаче, известной только автору проекта, естественно, что никто за него проект не напишет.
Сам процесс разработки проекта для BOINC ― достаточно трудоемкое мероприятие, требующее определенной программисткой квалификации. В этой связи российское отделение Международной федерации Грид-систем из персональных компьютеров (готово оказывать помощь. В нашу задачу входит поддержка отечественных разработчиков распределенных приложений. Если у кого-то из них возникает желание создать такой проект, то мы помогаем советами, оказываем консультации по технологии, а в некоторых случаях предоставляем свои мощности для размещения проектов. У нас такой опыт уже есть с Иркутском, а как раз сейчас мы сотрудничаем с механико-математическим факультетом МГУ ― создаем проект для решения совместными усилиями одной важной математической задачи.
А зачем разбивать вычисления на множество маленьких подзадач? Не проще ли большую задачу сразу посчитать на суперкомпьютере? И как определить ученому, с помощью какого ресурса эффективнее посчитать ту или иную задачу ― с помощью ГСПК или используя суперкомпьютер?
Добровольные вычисления применимы к классу очень тяжелых задач, которые требуют огромного процессорного времени на расчеты, и которые можно разделить на много маленьких подзадач. То есть это те задачи, с которыми в одиночку справился бы только суперкомпьютер. Но тут надо учитывать, что любой суперкомпьютер, даже такой мощный, как, например, недавно установленный в МГУ «Ломоносов», вынужден делить эту мощность между большим числом потребителей. И естественно, нет возможности предоставить его в монопольное использование какой-то исследовательской группе. Поэтому пользователь все равно получает только часть ресурса, так называемую квоту. И вот эта квота, конечно же, заметно скромнее декларируемой мощности суперкомпьютера. Поэтому если сравнивать добровольные вычисления и суперкомпьютеры, то вычислительный ресурс, который можно получить с помощью добровольных вычислений, не уступает типичной квоте, а нередко и превосходит ее.
Но есть важный момент, который необходимо понимать. Помимо процессорной мощности и оперативной памяти важную роль играет скорость передачи данных между вычислительными узлами. Как правило, суперкомпьютеры обладают высокоскоростной сетью для передачи данных. То есть процессоры могут обмениваться друг с другом информацией, причем делают это на очень высоких скоростях. У добровольных вычислений такой возможности нет. Клиенты взаимодействуют через центральный сервер проекта. Это единственный способ взаимодействия, непосредственно между собой они не могут взаимодействовать. Также есть различия и в гарантии предоставления ресурса. Добровольные вычисления опираются на ресурсы компьютеров частных лиц и организаций, которые не подписывают договоров и гарантий услуг, и естественно, эти люди могут в любой момент, например, выключить компьютер, иногда на несколько дней. И получается такая ситуация: компьютер получил задачу, его выключили, через три дня включили, и он продолжил расчеты. Но три дня эта подзадача была неактивна! И в этой ситуации происходит дублирование ― задачу пересылают еще кому-то. Конечно, это неэффективно. Конечно, на суперкомпьютерах так не делается, потому что есть гарантия того, что на протяжении определенного времени выделенный ресурс будет полностью в вашем распоряжении. То есть если ваша задача чувствительна к высокоскоростной передаче данных, если вам требуется полная доступность процессоров на каком-то интервале времени, то, безусловно, такие задачи необходимо решать на суперкомпьютерах. Но есть очень много задач, которым это не нужно. Они распадаются на абсолютно независимые подзадачи, которые можно рассчитывать на разных машинах, и им совершенно необязательно взаимодействовать. Вот тогда можно задействовать гораздо более дешевый ресурс – ресурс простаивающих мощностей интернет-пользователей. Это позволит разгрузить ресурсы суперкомпьютеров для выполнения целевых вычислений.
Суперкомпьютер "Ломоносов"
А сами научные группы оплачивают участие своих проектов в распределенных вычислениях? Скажем, есть ли какая-та плата за размещение проекта на сайте BOINC? А за пользование ресурсом суперкомпьютера?
Нет, исследователи практически никогда напрямую не оплачивают те компьютерные ресурсы, которые им предоставляют на суперкомпьютерах. Но надо понимать, тем не менее, что эти ресурсы стоят очень дорого. Это большие затраты на разработку, сборку, администрирование суперкомпьютера и поддержание его работоспособности, которые ложатся тяжелым бременем на бюджет любого учреждения. Что же касается ГСПК ― то фактически все затраты сводятся к поддержанию одного сервера. Причем совсем не обязательно, чтобы этот сервер был целиком выделен для расчетов этого проекта. В нашей практике мы используем виртуальные машины. То есть на одном сервере размещается несколько проектов. Естественно затраты на содержание здесь минимальны. Это может позволить себе практически любой коллектив, и затраты бюджета учреждения здесь примерно равны затратам на поддержание одного персонального компьютера.
Есть ли уже примеры подобных успешных российских проектов?
Российских проектов пока что очень мало, потому что их создание началось совсем недавно. Самые известные ― это SAT@home, Gerasim@home и Optima@home. Из международных проектов хотелось бы отметить проект Climateprediction.net, посвященный численному моделированию климатических процессов. Интересные результаты получены в рамках проекта Einstein@Home: в результате анализа сигналов из космоса были обнаружены новые звезды ― радио-пульсары. Много проектов в области биоинформатики. Например, в рамках проекта Rosetta@home производится расчет конформаций белковых соединений, имеющих важное значение при разработке лекарств.
В нашем совместном проекте с Иркутском SAT@home математическая часть сделана учеными из Иркутска из группы Семенова Александра Анатольевича, мы же помогли консультациями по разработке и развертыванию BOINC-проекта ПО и предоставили сервер для размещения проекта.
А пользователь может выбрать, в каком проекте принимать участие?
Да, он имеет такую возможность. Когда вы устанавливаете программное обеспечение BOINC, вам предоставляется список проектов, из которых можно выбрать. Кроме того, информация о BOINC-проектах может быть получена со специальных статистических сайтов.
Пользователь может выбрать не один проект, а несколько. Обычно такой выбор осуществляется на основе анализа описания. Если пользователю кажется, что решаемая в рамках проекта задача научно значима, то он его предоставляет вычислительный ресурс своего ПК. К тому же, когда пользователь подключается к проекту, он доверяет разработчику. То есть он принимает, что, если автор проекта декларирует, что идет расчет генома или, допустим, вакцины от рака, значит, в действительности идет расчет именно этих данных. Это исключительно вопрос доверия к научной репутации автора проекта.
И это также очень хороший пример взаимодействия между учеными и обществом. Пользователь сам определяет, какой коллектив поддерживать, а какой нет, опираясь на экспертные оценки других исследователей, на серьезность публикаций. То есть он оценивает сам, как эксперт, но без вмешательства государства. И для ученых это совсем нетривиальная задача – убедить людей в том, что проект нужный, рассказать о нем простым и понятным языком.
А как пользователю определить, сколько компьютерных ресурсов ему лучше предоставить, чтобы и пользу принести, и компьютер не завис в расчетах, а исправно работал?
Вообще загрузка определяется опытным путем в зависимости от того, насколько люди заинтересованы в предоставлении ресурсов. Причем вы не даете весь ресурс вашего компьютера, вы даете только ту часть, которую вы хотите дать. Когда вы работаете, целесообразно предоставлять не более 50%, тогда это не отразится на вашей работе. Если же вы хотите поиграть в какую-то компьютерную игру, тогда лучше вообще выключить проект, потому что компьютерная игра – это ресурсоемкое приложение, и оно будет конфликтовать с расчетами. В ночное время или в перерыв можно предоставить для расчета даже 100% ресурса. Но вообще, добровольцы загораются идеей считать больше. Я знаю, многие даже специально покупают компьютеры, которые отдают именно для добровольных вычислений. Люди таким образом даже соревнуются между собой.
За «карточку почетного донора»?
Именно! Есть статистические сайты, которые учитывают, кто, сколько ресурсов предоставил. При расчете проекта пользователю начисляются определенные очки. Они накапливаются, и если у какого-то пользователя их много, он сразу выделяется из общей массы. То есть присутствует элемент соревновательности. Это и мотивирует людей вкладывать собственные средства в покупку техники, чтобы предоставить ее для расчета проектов. Сейчас есть проекты, в которых хорошим тоном считается упоминание в публикациях имен или «ников» пользователей, которые предоставили свои мощности для расчетов. Иногда пользователям-лидерам выдают сертификаты в рамочках.
Как вы считаете, какой технологии принадлежит будущее при расчете ресурсоемких задач: суперкомпьютерам, облакам, обычными гридам или ГСПК?
ГСПК демонстрируют реальную производительность, измеряемую сотнями терафлопсов и сводят к минимуму затраты на создание распределенной среды. Но плюсы есть, конечно, у всех вышеназванных систем. Видимо правильно говорить о том, для каких задач целесообразно применять те или иные системы. А также об их интеграции между собой. В этом направлении плодотворно работает коллектив из Венгерской академии наук под руководством Питера Качука. Немало сделано и в нашем отделе в ИППИ РАН, руководимым профессором А.П. Афанасьевым. То есть сейчас ведутся исследования именно в направлении того, чтобы различные высокопроизводительные системы не существовали отдельно, не конкурировали, а взаимодействовали и взаимодополняли друг друга. Именно за такими разработками будущее.