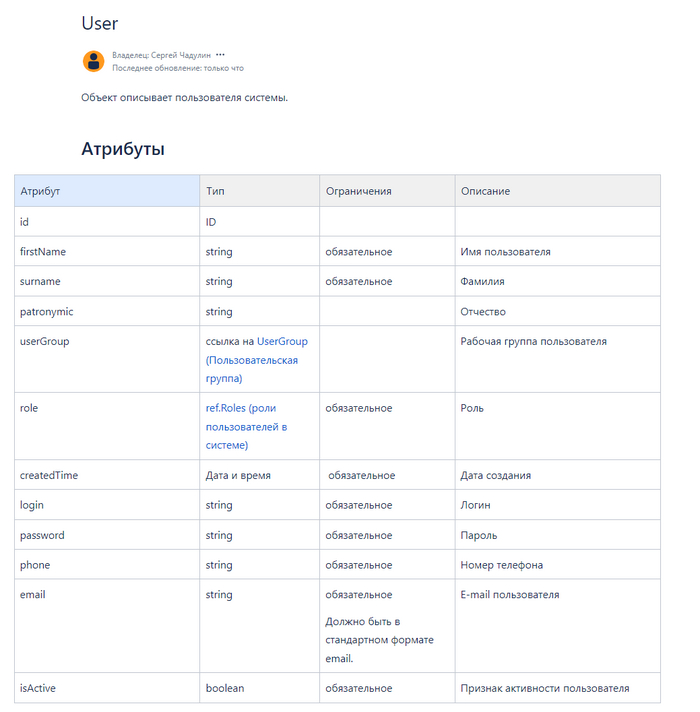
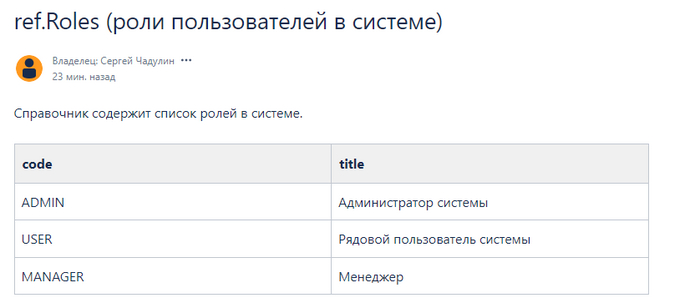
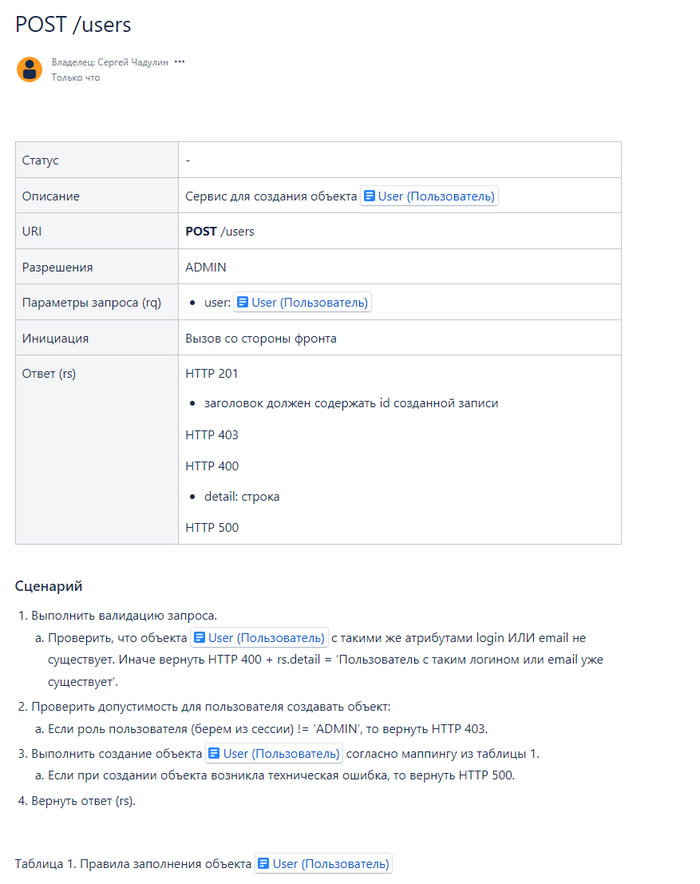
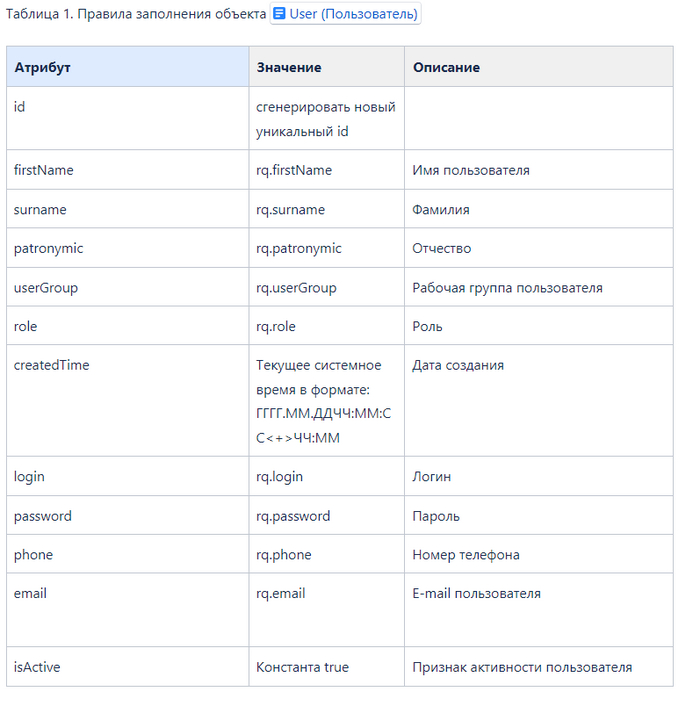
Завышение стажа в резюме в IT: работает или нет?
Я думаю многие из вас так или иначе сталкивались, либо слышали, про такой прием при поиске работы - как завышение своего стажа (либо накручивание его вообще, если его совсем нет). А одна из последних прочитанных мной новостей (реальных или нет - это уже другой вопрос), сподвигла меня написать свое мнение на этот счет.
Вообще, за 2023 год история с накруткой опыта набрала прям очень большую популярность, потому что было много успешных кейсов, о которых многие спешили поделиться в соц сетях.
Появились даже несколько каналов, в которые такие истории регулярно публикуются (рекламировать, конечно не буду). Некоторые из них правда заканчивались очень неудачно для решивших поделиться, потому что их работодатели наткнулись на эти посты и неприятно удивились. Поэтому если уж вы воспользовались таким способом, то хотя бы не распространяйтесь об этом =)
И подобные методики даже полу-официально предлагали некоторые известные и крупные курсы, которые обещали своим студентам гарантию трудоустройства, а тут, как известно, все способы хороши.
Как это работает?
На самом деле очень просто, т.к. основная проблема это не пройти техническое собеседование, а именно дойти до него. Прорваться сквозь труднопреодолимый барьер рекрутеров\HR, которые часто даже не смотрят резюме в котором нет хотя бы года релевантного опыта. Поэтому люди просто добавляют некий выдуманный опыт строчкой в резюме и это сразу же повышает конверсию просмотров, заинтересованность рекрутеров и соответственно количество "проходок" на собеседование. А всё потому, что у работодателя нет возможности убедиться в реальности того опыта, который указан в резюме. По крайней мере на уровне HR, а иногда и на уровне СБ, насколько я понимаю.
А уж спустя несколько собесов, научиться отвечать социально одобряемым образом на вопросы интервьюера (благо они очень часто одинаковые) - достаточно не сложно. Особенно если ты за энное количество собесов научился держаться уверенно, прокачал скилл их прохождения ив целом производишь благоприятное впечатление. Даже если у тебя слабенькая база. Если ты еще и действительно учился, понимаешь тему, готовился и так далее - то это еще сильнее облегчает собес.
Поэтому данный способ достаточно часто срабатывает в плюс и ты начинаешь получать офферы.
Не буду давать моральную оценку данному способу, потому что все хотят найти достойную работу, а конкуренция далеко не маленькая. Если есть лазейка чтобы попасть на работу и начать зарабатывать деньги - ну что ж, дело сугубо материальное, осуждать это я не в праве.
❕Однако, лично мое мнение в том, что не нужно перебарщивать. Я имею ввиду то, что если у вас совсем нет опыта - не нужно сразу устраиваться на миддла или сеньора, накручивая слишком большой опыт (такое, судя по некоторым историям, тоже реально).
Одно дело без опыта начать работать джуном - от тебя многого ждать не будут, вполне может прокатить и тебя не "раскроют". Но если ты пройдешь на того же миддла и даже не сможешь разговаривать с командой на одном языке - то в чем смысл? Не говоря уже о том, что ты не сможешь выполнять свои задачи самостоятельно, чего ждут от специалиста этого уровня, поэтому испытательный вы вряд ли пройдете, да еще и потом можете столкнуться с различного рода неприятностями
Поэтому единственный совет - подходите ко всему разумно.
P.S. своим студентам я такое не рекомендую и даже не упоминаю такой вариант. Я предпочитаю вариант с повышением конверсии и внимания со стороны рекрутеров через улучшения качества резюме. Добавление ключевых слов, переиспользование текущего опыта, казалось бы не релевантного, в рамках новой профессии и так далее. Все это вполне возможно и без обмана (хотя, конечно, возможно не так эффективно как докрутить себе год или два, ведь придется искать работу месяц, а может и не один).
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
За большим количеством постов с полезной информацией про системный анализ - заглядывайте на канал, в закрепленном дайджесте можете найти что-то интересное для себя.