Преобразование НКА в ДКА, один из алгоритмов
Предыдущая статья: Обещанная реализация КА и попытка создать таблицу переходов не детерминированному автомату. в vk.com
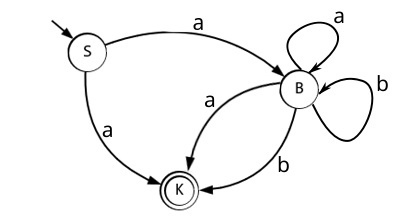
Что же давайте, ещё раз обратимся к нашему НКА и всё таки составим таблицу, в которую будем вписывать не к какому состоянию требуется перейти, а в какое состояние мы можем перейти, будем заполнять множеством состояний. Предоставляю граф и таблицу:
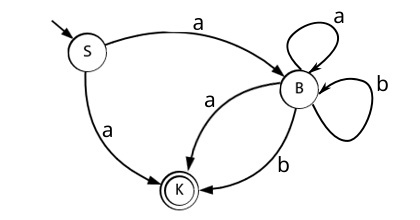
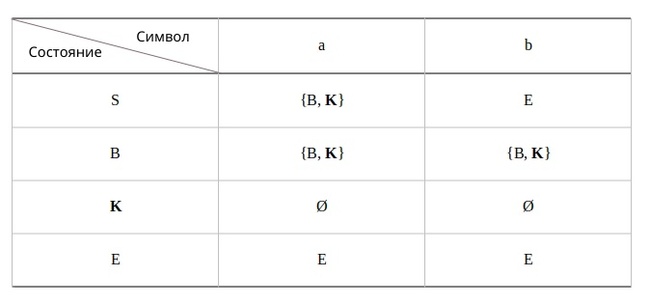
Символ Ø обозначает, что наш автомат завершил работу и более не принимает символов. Если мы продолжаем читать из потока, тогда нам следует перезапустить автомат для обработки уже следующей цепочки.
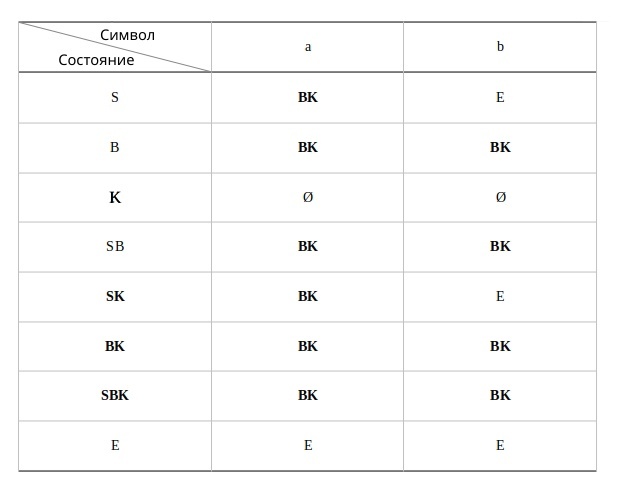
Приступим к алгоритму. Построим новый автомат на базе состояний нашего НКА. Состояния нового автомата будут иметь названия составляющие все возможные сочетания из множества состояний НКА по k, где k у нас будет меняться от 1 до максимального кол-ва. То есть в нашем случае до 3 из множество {S, B, K } это S, B, K, SB, SK, BK, SBK.
Состояния нового автомата в чьи имена попали, обозначения конечного состояния НКА, тоже становятся конечными: K, SK, BK, SBK. А начальное состояние не меняется S.
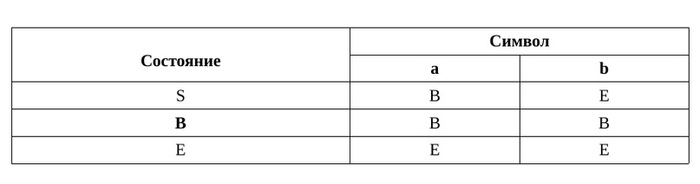
Теперь нам остаётся задать переходы по каждому символу, соблюдая следующее: Из каждого состояния N нового автомата направим не более чем один переход, помеченный данным символом, в такое состояние, которое соответствует множеству состояний НКА, в которые есть переходы по этому символу хотя бы из одного состояния НКА, образующего N.
Вот так:
Давайте построим для него граф:
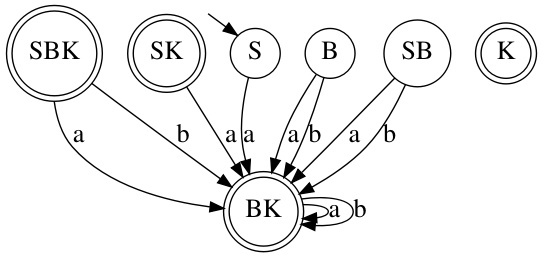
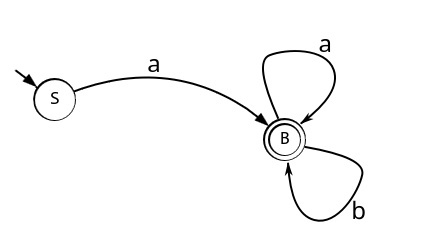
У нас получился ДКА, только в нём есть состояния в которые мы никогда не попадём. Поэтому данный ДКА следует минимизировать, алгоритма минимизации возможно коснусь в последующих статьях. Но можно выделить две вещи, когда следует минимизировать ДКА, когда у нас «мертвые» состояния и когда состояния повторяют одно и то же действие. Вот так будет выглядеть результат минимизация получившегося ДКА:
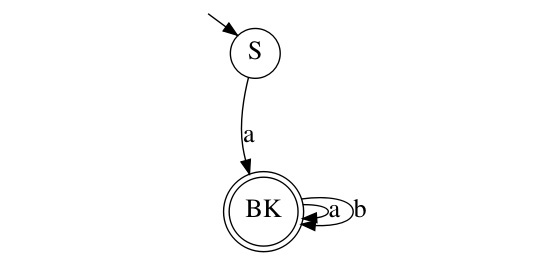
Переименуйте BK в B и узнаете уже рассмотренный нами ДКА.
З. Ы. Для построения графов в этот раз использовал эти инструменты https://www.graphviz.org/download/ и можно web-версию использовать http://www.webgraphviz.com/. Следующая статья будет посвящена синтаксическим диаграммам автоматного языка. Не забывайте подписываться, если вам это интересно.=)