
Эпический фрилансер Илья Бергер
Преамбула: не было так смешно, если бы не было так грустно.
История о 2-х фрилансерах.
Все лица выдуманы и любое совпадение чистая случайность.
Мне необходимо было доработать сайт "Ступени Жизни" на битриксе (мелкие поправки) и создать новую посадочную страницу. К сожалению текущая вообще не формирует воронку продаж.
Для начала я стал искать копирайтера. На всем известном ресурсе нашёл специалиста, назовём его к примеру Вячеслав Савицкий. Его работа была образцово показательная, он просто умница! Каждый раз, поле моей отправки сообщения, тут же он ставил реакцию о прочтении (очень удобно)!
Я рабочий человек, и своим сайтом занимаюсь по утрам (до работы) и по вечерам. Грешным делом написал ему в девятом часу в надежде, что его телефон выключен...
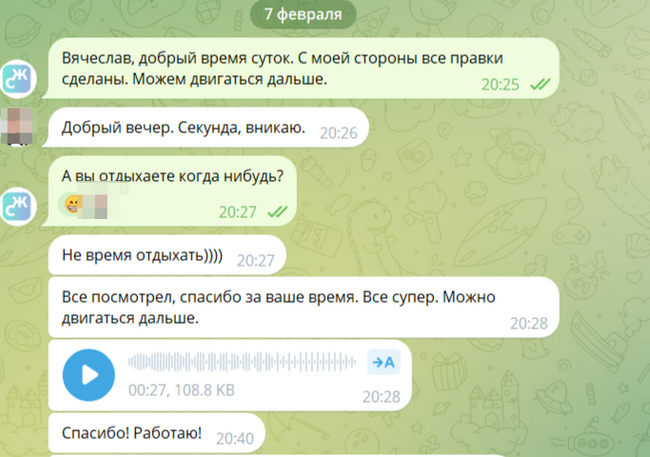
Я не ожидал ответа...
Я восхищаюсь такими специалистами! Работа была выполнена точно в срок!
Дизайнер (тоже умница) доделывает свою часть работы, можно переходить к программной части.
Теперь переходим к юмору.
На этом же ресурсе нашел программиста по Битриксу, назовём его к примеру Алексей Цыганов или Илья Бергер. 1С Битрикс, Программист, рейтинг. В общем "профессионал"!
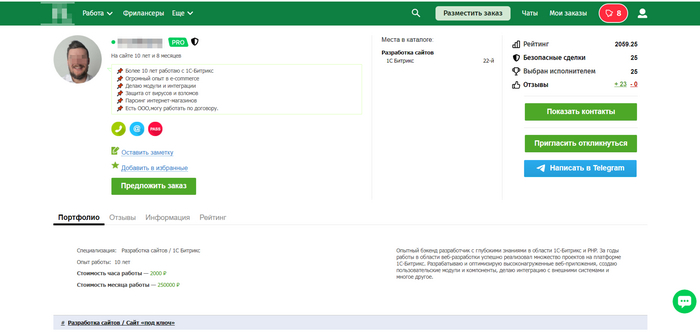
"профессионал"
21 Февраля заключили сделку.

4-5 дней на всё!
Прошло 11 дней!!! На меня уже косо посматривают мои коллеги по созданию сайта. Я, а точнее Илья, уже дважды нарушил сроки сдачи работ.
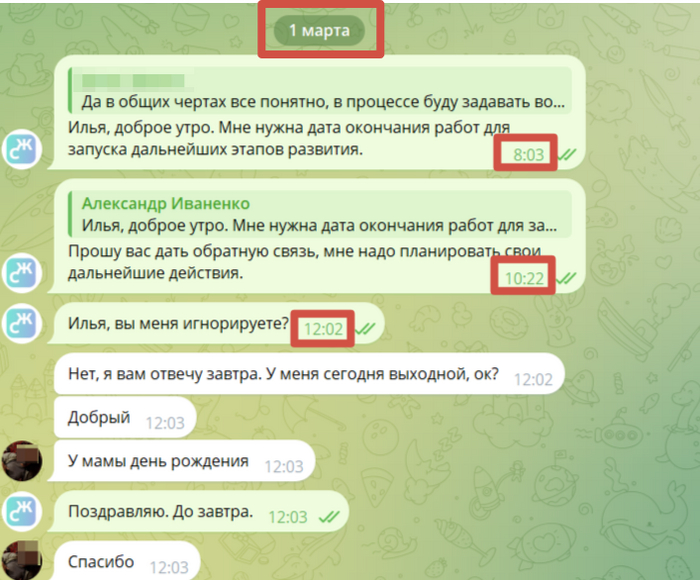
Без комментариев.
У мамы... День Рождение... в 8 утар!!! =))))))) Ок. Оправдываюсь перед коллегами, мол у мамы программиста ДР. Завтра всё будет.
На следующий день. После ожидания половины дня, решил написать ему сам.
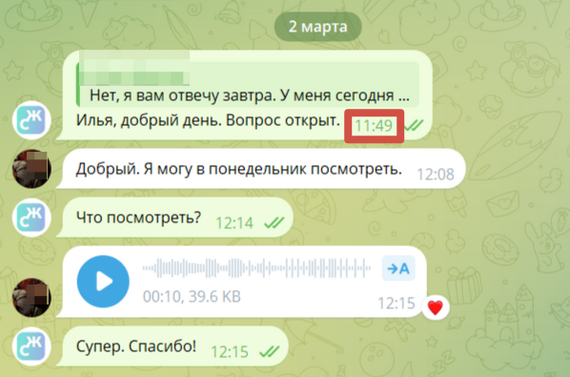
На вопрос: "Когда будет выполнена работа?" получил ответ: "В понедельник посмотрю".
Правда потом спохватился и голосовым сообщением сказал, что в среду, 6-го будет всё готово. 3 раза нарушил сроки сдачи. Я подозреваю, что к работе он не приступал. Говорю про это коллегам, они начинают улыбаться.
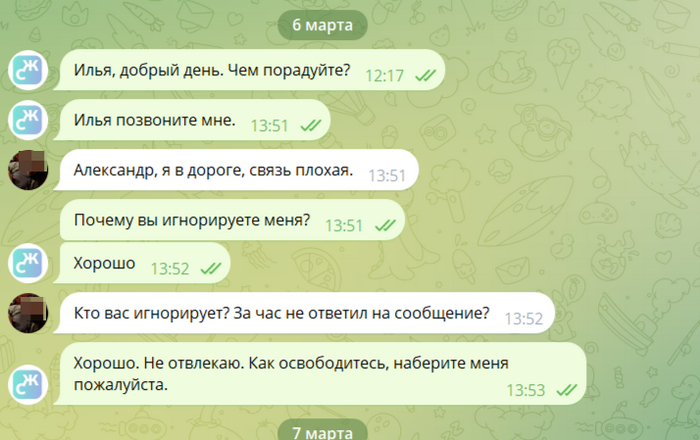
Он в дороге.
6-го марта, выждал пол дня и я опять сам написал ему... ,вместо того, чтобы выполнить своё обещание Илья Бергер катается на машине. 4-й раз нарушил срок сдачи работы. Коллеги начинают ржать в открытую.
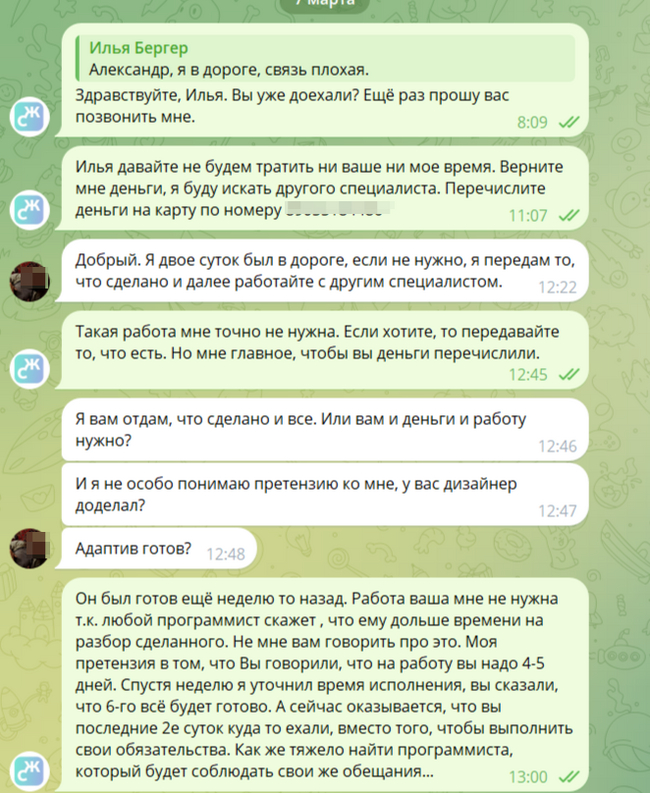
7-го марта я начал нервничать, как всегда написал первым т.к. посчитал, что вряд ли он сидит за рулём больше 20 часов. Он как всегда забил на меня. Вопрос про адаптив меня поверг в шок. Всё это время он ни разу не заходил по ссылке в Фигму и не принимался за десктоп... Очередной обман.
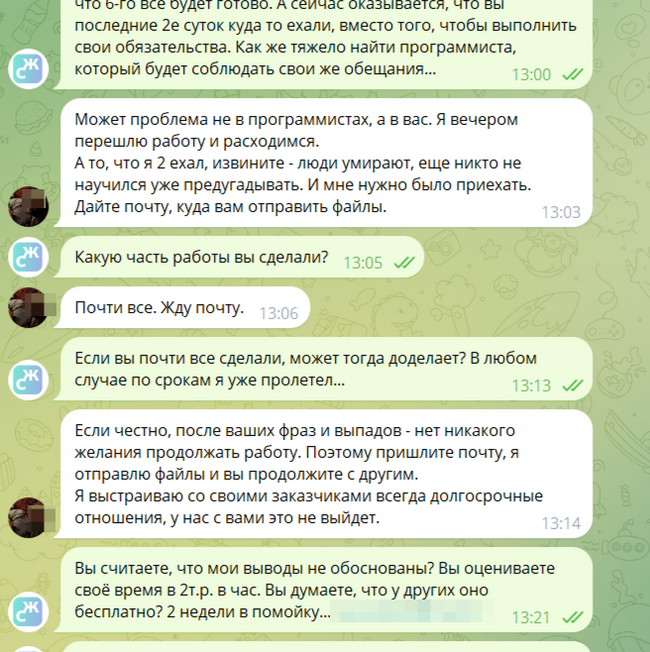
Обычный срачь... Оказывается вся проблема была во мне =) Еще смешно то, что он "почти всё сделал", даже не заглядывая в Фигму. =) Коллеги хватаются за животы, подкалывают и фантазируют дальнейшие действия моего горе программиста.
Полез смотреть, какие же он выстраивает отношения...
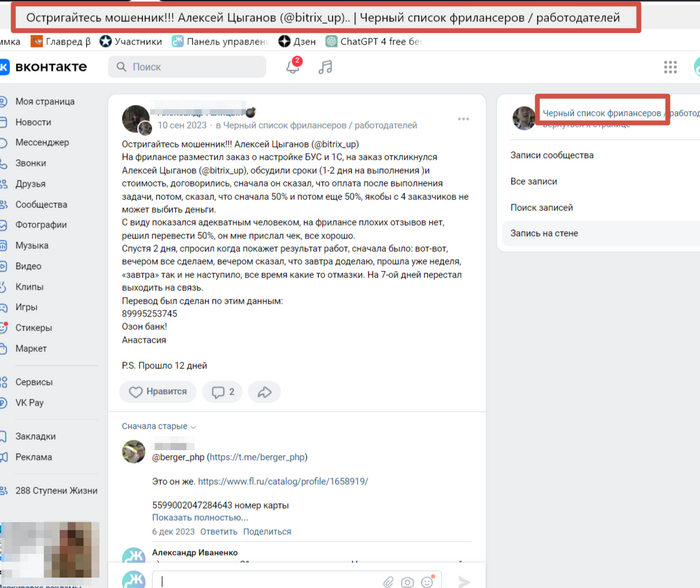
Вечером, конечно же ничего не прислал, (уже запутался) по моему 6 раз обманул.
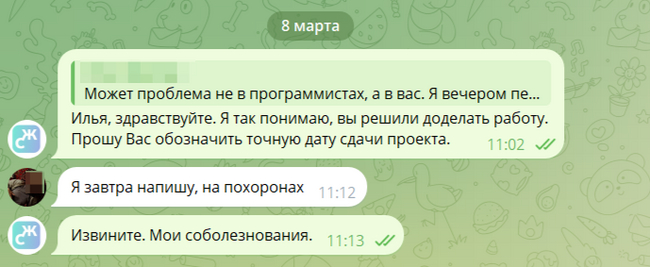
На следующий день, традиционно выждав пол дня, пишу. Оказывается он уже на похоронах. Ждём завтра...
В 7-й раз обман! Завтра Илья Бергер ничего не написал (как и после завтра тоже). Из чувства такта выжидаю 3 дня (вроде так положено по ТК) (хотя если считать 8-е число, то 4 дня).
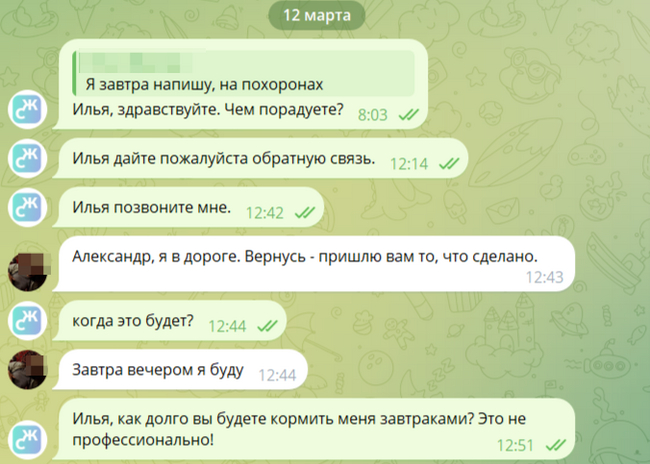
8-й раз обман.
Пытаюсь уладить дела со своими контрагентами, рассказывая им, что мой программист то на ДР, но 48 часов за рулём, то на похоронах. Надомной откровенно начинают ржать. Теперь я оправдываюсь, что мой программист в самолёте!
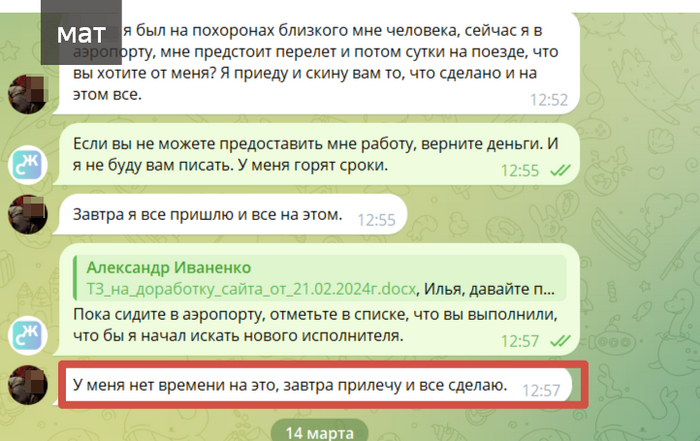
И он настолько занятой, что нет времени на отправку того, что сделано. В самолёте (я так предполагаю) не было услуги предоставления интернета (хотя, я на всех самолетах, что летал за последние 5 лет мог без проблем воспользоваться им и не раз видел в самолёте работающих программистов). Слова "завтра прилечу и всё сделаю были произнесены" 12 марта. 9-й раз обман, вы думаете на этом всё? Товарищи "по цеху" от смеха лежат под столами. Один утверждает, что завтра Илья Бергер будет сплавляться на байдарке, второй, что завтра будет рожать, третий утверждает, что жениться. Мне не до смеха вообще.
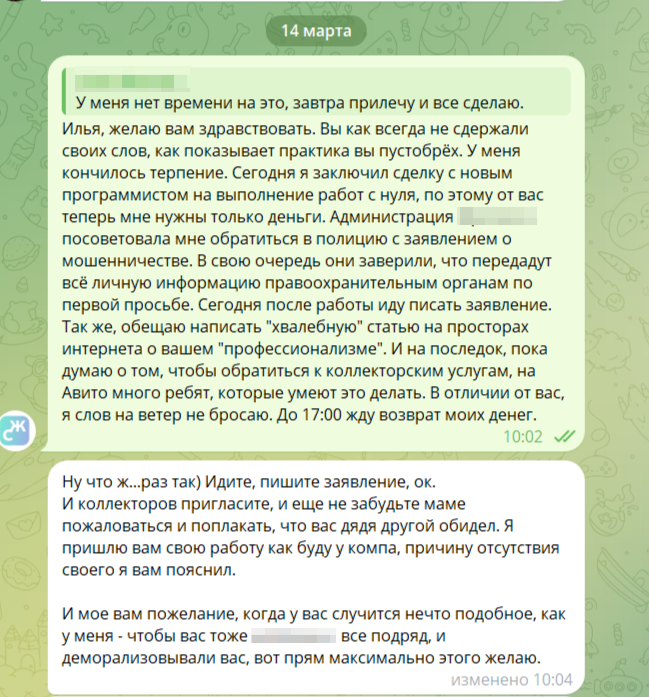
Одним словом, "профессионал".
Я позвонил Анастасии (Илья Бергер предоставил этот номер для перевода предоплаты, фрилансеры часто так делают, что бы не платить налоги) и попросил ее вернуть деньги. Она попыталась сойти за дурочку, "мол я не я корова не моя". Якобы у нее нет доступа к своему счёту. Илью не знает и вообще все претензии предъявлять этому Илье. Я предположил, что враньё - это у них семейное и сказал, что буду писать заявление о мошенничестве. И тут...

Видно эта Анастасия повлияла на незнакомого ей Илью Бергера.

После того, как написал заявление в полицию, Илья зашевелился. Анастасия деньги перечислила почти сразу же после прочтения.
Вы думаете на это всё =)))))
На следующий день, опять динамо. Хотя я перечитал переписку, подтверждения его слов не нашёл. Можете меня поздравить с юбилеем, 10 обман.
И сейчас не всё!

И сейчас опять не всё.
17 марта - это прощёное воскресенье. По этому я простил этого "Илюшу" (у нас это имя стало нарицательным).
IT сфера не такая уж большая как кажется, тем более среди фрилансеров. Пишу, чтобы заказчики не попадались на ту же удочку. Может этот Илья и неплохой исполнитель, просто надо с ним работать только при помощи безопасной сделки, вот и всё.
Мораль: не доверять на слово, не доверять рейтингам и платформам, проверять людей, работать только с безопасными сделками, быть решительнее и принимать кардинальные меры не дожидаясь полной ж..пы. И самое главное - ничего не обещать от своего имени, если что то от меня не зависит!
Кто нибудь меня переплюнул по количество завтраков?
Как в мультике: "теперь полдня будешь бегать чтобы фотографию отдать".
Показать полностью
19


Алгоритмы поиска
В программировании одной из наиболее часто встречающихся задач является поиск. При решении таких задач мы исходим из предположения, что группа данных, в которой необходимо найти заданный элемент, является фиксированной.
Пример: Пусть задан массив из n элементов array[0...n-1]. Обычно items описывает запись с некоторым полем, выполняющим роль ключа. Задача заключается в поиске элемента, ключ которого равен заданному аргументу поиска x (a[i], key = x). Полученный в результате i, удовлетворяющий условию a[i] = key = x, обеспечивает доступ к другим полям обнаруженного элемента. Так как нас интересует в первую очередь сам процесс поиска, а не обнаруженные данные, то мы будем считать, что тип item включает только ключ (item = key).
1. Линейный поиск
Линейный поиск заключается в простом, последовательном просмотре массива с увеличением шаг за шагом той его части, где желаемого элемента не обнаружено. Условием окончания поиска является либо нахождение элемента, либо просмотр всего массива без обнаружения совпадений. Этот метод просто проверяет каждый элемент массива по очереди, пока не найдет искомый элемент или не просмотрит весь массив.
Линейный поиск
int i = 0;
const int n = 100;
int arr[n] = {...};
int x;
cin >> x;
while((i < n) && (arr[i] != x)) {
i += 1;
}
2. Линейный поиск с барьером
При линейном поиске на каждом шаге требуется вычислять логические выражения и увеличивать индекс. Чтобы увеличить скорость поиска, можно упростить само логическое выражение. Это можно сделать, если мы гарантируем, что совпадение всегда произойдет. Для этого в конец массива достаточно поместить дополнительный элемент x. Такой вспомогательный элемент называется барьером. Он охраняет нас от перехода за пределы массива. Этот метод упрощает линейный поиск, добавляя искомый элемент в конец массива. Это гарантирует, что поиск всегда будет успешным, и упрощает условие окончания поиска.
const int n = 100;
int arr[n] = {0...n};
int x;
cin >> x;
arr[n] = x;
int i = 0;
while (arr[i] != x) i += 1;
3. Бинарный поиск
Для рассмотрения алгоритма мы будем считать, что массив будет заранее упорядочен, то есть удовлетворяет условию 1 <= k < N; a[k-1] <= a[k]. Основная идея алгоритма выбрать случайно некоторый элемент, предположим a[m] и сравнить его с аргументом поиска x. Если он равен x, то поиск заканчивается. Если меньше x, то мы заключаем, что все элементы с индексами <= m можно исключить из дальнейшего поиска. Это соображение приводит нас к алгоритму, который называется поиск делением пополам. Этот метод использует преимущество отсортированного массива, чтобы ускорить поиск. Он выбирает элемент в середине массива и сравнивает его с искомым. Если элемент в середине меньше искомого, то поиск продолжается в правой половине массива. Если элемент в середине больше искомого, то поиск продолжается в левой половине массива. Этот процесс повторяется, пока не будет найден искомый элемент или пока не останется непроверенных элементов.
int n = 100, left = 0, right = n - 1;
int arr[n] = {0...n};
int x;
bool found = false;
cout << "Введите число для поиска: ";
cin >> x;
while(left <= right && !found) {
int m = (left+right)/2;
if(arr[m] == x) {
found = true;
cout << "Число найдено на позиции: " << m << endl;
}
else if(arr[m] < x) left = m + 1;
else right = m - 1;
}
if(!found) {
cout << "Число не найдено." << endl;
}
Бинарный поиск
Эффективность алгоритма можно несколько улучшить, если поменять местами заголовки условных операторов. Проверку на равенство можно выполнить во вторую очередь, так как она встречается лишь единожды и приводит к окончанию работы.
Поиск в таблице
Поиск в массиве = поиск в таблице. Особенно если ключ сам является составным объектом, таким как массив чисел или массив символов. Часто встречается поиск символов, когда массив символов называют строками или словами. Строковый тип определяется так, string = char arr[0...n-1]. Для установки факта совпадения, мы должны убедиться, что все символы сравниваемых строк соответственно равны один к другому, поэтому сравнение составных операндов сводится к поиску их на неравенство. Если нет не равных частей, то это равенство. Чаще всего используется 2 представления о размерах строк. 1) Размер указывается неявно, благодаря добавлению кольцевого символа, который больше нигде не употребляется. Обычно используется непечатаемый символ со значением 0C ('/0') (минимальный символ из всех символов). 2) Размер явно хранится в качестве первого элемента массива, то есть строка s имеет вид s = s0, s1, ..., s(n-1). Эти символы являются фактическими в строке, а s0 = char(n) (определяет размер строки). Этот метод аналогичен поиску в массиве, но применяется к строкам. Здесь мы ищем подстроку в строке, сравнивая каждый символ подстроки с соответствующим символом строки.
Задача: упорядоченная таблица T (в алфавитном порядке); Аргумент поиска = x (string); T = string arr[0...n-1]. N достаточно велико.
int n = ...; // Замените на конкретное значение
string arr[n] = {...}; // Замените на конкретные значения
string x;
int l = 0, r = n;
cout << "Введите строку для поиска: ";
cin >> x;
while(l < r) {
int m = (l + r) / 2;
if(arr[m] == x) {
cout << "Строка найдена на позиции: " << m << endl;
break;
}
else if(arr[m] < x) l = m + 1;
else r = m;
}
if(l == r) {
cout << "Строка не найдена." << endl;
}
Прямой поиск строки
Пусть задан массив s из n элементов. И задан массив p из m элементов. 0 < m <= n. s: array[0...n-1] of item, p: array[0...n-1] of item. Поиск строки обнаруживает первое вхождение p в s. Обычно item это символы, то есть их можно считать некоторым текстом, а p является образом или словом. Мы хотим найти первое вхождение в слово. Рассмотрим прямолинейный поиск алгоритма. Поиск можно представить, как повторяющие сравнения. Этот метод ищет первое вхождение подстроки в строке, сравнивая каждый символ подстроки с соответствующим символом строки.
string P = "..."; // Замените на искомую строку
string T = "..."; // Замените на текст, в котором ищем
int M = P.size();
int N = T.size();
bool found = false;
for(int i = 0; i <= N - M && !found; i++) {
int j = 0;
while(j < M && T[i + j] == P[j]) {
j++;
}
if(j == M) {
found = true;
cout << "Строка найдена на позиции: " << i << endl;
}
}
if(!found) {
cout << "Строка не найдена." << endl;
}


Показать полностью
2

Продолжаем решать деревья. Инвертирование дерева - одна из самых популярных задач
Эта часть является продолжением цикла лекций про деревья. В этой части мы снова воспользуемся рекурсией чтобы инвертировать дерево. Задача довольно популярна и по сложности является довольно простой.
Допустим у нас есть дерево
Допустим у нас есть дерево ниже:
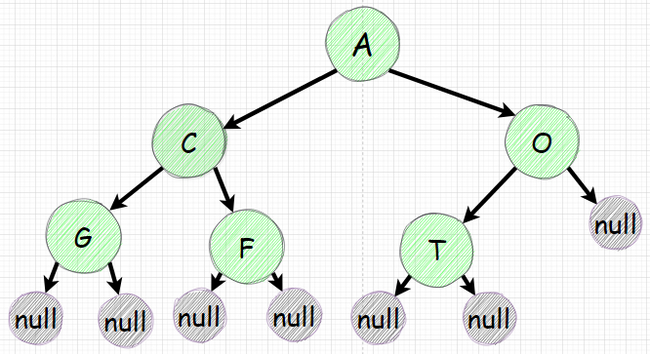
Инвертируем дерево
Целью является инвертировать дерево. Те для каждого узла нужно поменять местами его левый и правый наследники. Логику надо также применять к наследникам наследников.
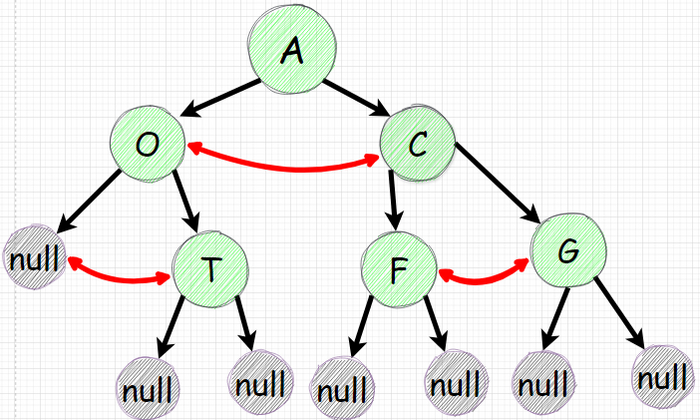
Давайте проговорим какие этапы нужно продумать:
Проитерироватсья по всем узлам рекурсией те нам понадобится функция которая будет вызывать саму себя.
Нижние пустые null узлы нужно будет проигнорировать
Для всех остальных узлов нужно выполнить смену ссылок для правого и левого наследников
Решение:

Думаю вам тоже задача показалось довольно простой но при этом она является одной из самых частых во время собеседований. В следующей статье мы рассмотрим более сложные случаи. Всем кому интересно - добро пожаловать в мою группу.
Показать полностью
2
Используем рекурсию для решения задач на деревья. Ищем максимальную глубину дерева
В прошлой части мы рассмотрели разные подходы рекурсивного обхода дерева. Давайте воспользуемся некоторыми из них для решения довольно известных задач.
Находим максимальную глубину дерева.
Одна из самых популярных и простых задач на деревья - поиск узла находящегося на максимально удаленом расстоянии. Рассмотрим дерево ниже:
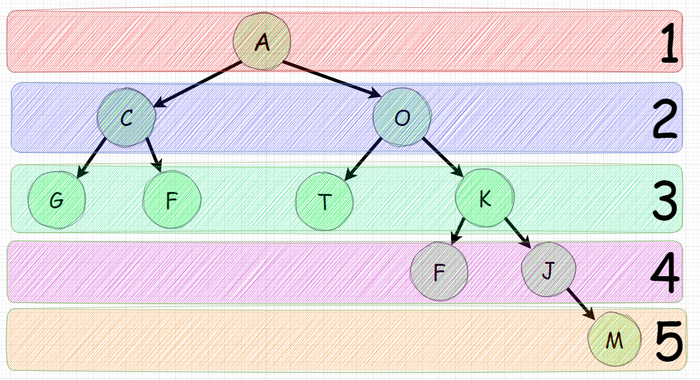
Высота данного дерева - пять
Довольно очевидно что самый длинный узел в данном дереве - M и он является пятым по счету если головной является первым.
Как решать данную задачу используя рекурсию.
Если сильно упрощать то нам нужно сделать 2 действия:
Обойти все узлы
Каким то образом "сохранять" состояния каждый раз когда мы обходим узлы
Но как же сохранять состояния о той глубине на которой мы побывали? Тут есть как минимум два варианта:
Использовать возвращемое значение самой рекурсивной функции и "возвращать" её на уровень выше.
Иметь какой то объект в котором мы будем сохранять состояния находясь внутри рекурсии
Воспользуемся первым подходом. Сосредоточимся на следующих аспектах:
Рекурсивная функция должна передавать значение сама себе "наверх"
Определить какое именно значение должно перебрасываться.
Логика передаваемого "наверх" значения.
Самые нижние уровни (те что указывают на null) должны возвращать 0 тк они не включены в расчет глубины данного подграфа
Нижний уровень который с листьями имеет лишь null предков должен вернуть 1 тк он является первым уровнем
Узел выше чем 1й (те не лист) должен выбирать максимальный уровень из двух его наследников и добавлять 1 тк находится на уровень выше из наибольшего из них.
После данных рассуждений у нас вырисовывается вот такая картина:
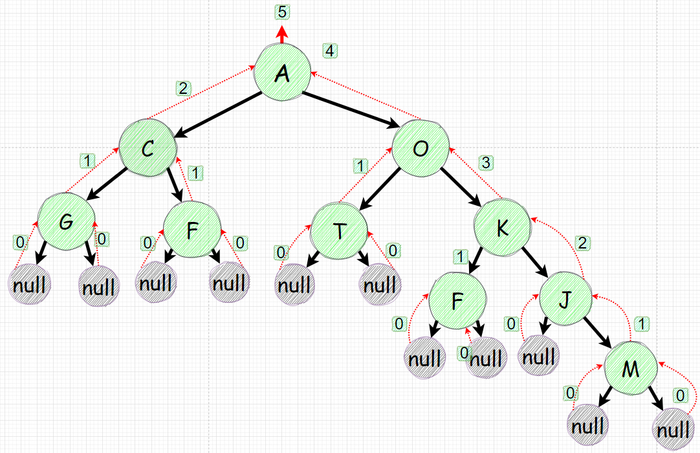
null уровни 0, листья 1 и все остальные узлы - выбирает наибольшее из наследников и добавляют 1.
К чему привели наши рассуждения?
Все эти рассуждения намекают что в нашей итеративной функциии будет 3 разных сценария и функция которая выбирает наибольшее из двух. Именно подобные размышления чаще всего помогают перевести абстрактные размышления в код.
И так первая версия кода:

Версия рабочая но слишком многословная - хотя для собеседования вполне подойдет.
Самый важная часть кода - итеративный вызов левого и правого поддерева и последующий расчет максимального значения среди них. И конечно же добавление 1 наибольшему из них чтобы учесть и текущую высоту.
Этот код можно было бы улучшить удалив случай когда мы находимся в самом низу - дело в том что если условие истино то возвращаемое значение maxDepth + 1 будет также равно 1.
Спасибо за внимание, всем кому интересна промышленная разработка приглашаю в мой канал.
Показать полностью
2

В очень ближайшем
Показать полностью
1
Типы данных
Тип данных - это набор значений и операций, которые можно проводить над этими значениями.
Концепция типа данных:
Тип данных определяет, какие значения может принимать переменная или выражение.
Мы можем узнать тип данных, просто посмотрев на его описание, без вычислений.
Каждая операция или функция требует аргументов определенного типа.
Простейшие типы данных
Простейшие типы данных - это базовые типы, которые определяются через перечисление значений.
Например, если у нас есть новый тип NAME, мы можем определить его значения как Value1, Value2, и так далее. Это выглядит примерно так: TYPE NAME = (Value1, Value2, ..., ValueN). Это значит, что переменная этого типа может принимать любое из этих значений.