Few-shot learning позволяет модели распознавать и классифицировать новые изображения после того, как она была обучена на небольшом количестве обучающих примеров.
Зачем это придумали? Ведь модели обычно обучают на огромных количествах данных? Чем больше, тем лучше, так?
Да, но… Few-shot learning — это важный концепт в ML по нескольким причинам.
Во-первых, такой метод сокращает время, необходимое для разметки больших наборов данных.
Во-вторых, не нужно добавлять разные функции для разных задач, если мы используем один и тот же набор данных для создания разных примеров. И это, с одной стороны, круто, потому что обучение на небольшом количестве данных научит модели лучше распознавать объекты на основе их меньшего количества. Это означает, что модели становятся более универсальными, а не такими специализированными, как обычно.
С другой стороны, в бизнесе востребованы разные модели для разных отраслей, потому что это учитывает особенности рынка и потребности предприятий. Экспертиза в определенной сфере помогает сократить время на разработку моделей, которые уже соответствуют требованиям этой отрасли, и, следовательно, требуют меньше изменений.
Короче говоря, метод обучения зависит от целей.
Обучение на малых данных наиболее часто используется в computer vision, поскольку характер проблем CV требует либо больших объемов данных, либо гибкой модели.
А можно ли сделать модель, обученную на небольшом количестве данных, сделать гибче? И как?
Возможно, конечно, если придерживаться определенных стратегий. Можно добавить дополнительные слои или изменить число нейронов в слоях. Да, это увеличит её сложность модели, но также и улучшит ее способность к обобщению.
Есть ещё методы аугментации данных: повороты, масштабирование и отражение изображений. Они помогают увеличить разнообразие обучающего набора и сделать модель менее чувствительной к вариациям в данных.
Есть и другие. Техники адаптивного обучения, о которых мы уже рассказывали в рубрике #технокульт в этом материале. Правда, не в контексте обучения моделей, а RL-агентов, но суть не меняется. Другие варианты — это алгоритмы ансамбля: бэггинг, бустинг или стекинг… Обо всём этом — чуть позднее.
Звучит страшно. Мульти, модальное, так еще и программирование. Технически, такой подход в ML включает в себя разработку приложений с поддержкой нескольких модальностей ввода и вывода: аудио, видео, текст и даже голоса — все эти данные объединяются и прогоняются через алгоритмы машинного обучения.
Хорошим примером тут может послужить CLIP, которая соотносит изображение и подпись к ней, ее продвинутый аналог VQGAN, квантованная генеративная адвесариальная сеть, которая создает изображения.
Работая вместе, VQGAN генерирует изображение, а CLIP выступает как ранжировщик, оценивая насколько хорошо изображение подходит тексту. Тот же Siri от Apple, Google Assistant и Amazon Alexa — примеры мультимодальных ИИ, так как им приходится взаимодействовать и с голосом пользователя, и его текстовыми запросами. В E-commerce может стоять классификатор продуктов, учитывающий и их названия, и внешний вид.
Очевидно, что у мультимодальных нейросетей много применений — это могут быть все нейросети, где задействуется два и более типа данных. Мы также нашли датасет CMU-MOSEI с аудио и видео тысячи спикеров на ютубе.
Но Microsoft, Apple, OpenAI и другие компании все равно остаются на стороне одномодальных моделей, ведь зачастую невозможно выделить адекватное представление аудио через текст, а также провести адекватное совместное обучение из-за проблем перевода данных из одной модели в другую, например, как в случае перевода обработанной информации с компьютерной томографии и МРТ.
В обучении обычно применяются два типа по времени слияния данных: раннее и позднее. В первом случае данные объединяются задолго до этапа принятия решения нейронкой и обучаются вместе, во втором — слияние проходит только в самом конце, а дополнительные нейронки обучаются на датасетах независимо.
Что такое random_state в машинном обучении? Зачем нужен этот парметр и как его выбрать? А что вообще общего у числа 42 с культовой книгой “Автостопом по галактике”? И разве случайности не случайны?..
Что такое random_state и как его настройка влияет на обучение моделей?
Возможно, многие из вас уже слышали о параметре random_state, особенно если вы сейчас погружаетесь в ML-разработку. Или вы уже пробовали работать с этим параметром, разбивая набор данных на обучающую и тестовую выборки.
Если же забыли или сейчас столкнулись с randome_state впервые, рассказываем, что это такое.
Параметр `random_state` в ML-разработке обычно используется для установки начального состояния генератора случайных чисел. Этот параметр часто встречается в алгоритмах машинного обучения, которые включают случайные элементы. Например, инициализация весов модели, разделение данных на обучающий и тестовый наборы, случайная инициализация параметров и т. д.
Представьте, что вы выполняете задание, в котором нужно использовать случайные числа. Например, вы разделяете данные на обучающую и тестовую выборки, и вам нужно случайным образом выбрать часть данных для обучения и часть для тестирования модели.
`random_state` — это как начальное число, которое указывает компьютеру, как начать генерацию случайных чисел. Если вы каждый раз используете одно и то же значение `random_state`, то каждый раз, когда вы запускаете эксперимент, вы будете получать те же самые случайные числа. Это помогает сделать ваше исследование воспроизводимым. То есть каждый раз, когда вы запускаете эксперимент с одним и тем же `random_state`, вы получаете те же самые результаты.
Почему это важно?
Предположим, что у вас есть модель, которая дает вам хорошие результаты на определенном наборе данных. Вы хотите сравнить ее с другой моделью или настройками. Если вы используете один и тот же `random_state`, то обе модели будут тестироваться на тех же самых данных, что позволит вам честно сравнивать их результаты.
random_state = 0 or 42 or none
Чаще всего люди устанавливают значение random_state на 0 или 42. Но вы знаете, почему это так?
Простота запоминания
Числа 0 и 42 довольно легко запомнить, поэтому они часто используются как стандартные значения для `random_state`.
Распространенность
Эти числа стали популярными благодаря их частому использованию в примерах и обучающих материалах. Честно говоря, многие останавливаются на этих значениях, даже если они не понимают их смысла.
Теперь давайте рассмотрим каждое число отдельно:
- 0 — часто используемое значение, потому что оно приводит к одинаковым результатам при каждом запуске программы, что удобно для проверки и воспроизводимости экспериментов.
- 42 — это число стало популярным после того, как стало известно, что автор Дуглас Адамс использовал его в своей книге "Автостопом по галактике" как ответ на вопрос о смысле жизни, вселенной и всего такого. В итоге эта сцена стала культовой, поэтому теперь это число часто используется в качестве самого простого способа установить `random_state`.
Таким образом, когда люди говорят о том, что чаще всего используют числа 0 или 42 для `random_state`, они обычно имеют в виду, что это стандартные значения, которые многие выбирают из привычки, не всегда понимая, почему именно эти числа используются.
Что такое random_state?
В библиотеке Scikit-learn этот параметр управляет перетасовкой данных перед их разделением. Мы используем его в функции train_test_split для разделения данных на обучающую и тестовую выборки.
Он может принимать следующие значения:
1. Нет (по умолчанию). Если не указано значение, то используется глобальный экземпляр случайного состояния из библиотеки numpy.random. Если мы вызываем функцию с random_state=None, то каждый раз получаем разные результаты.
2. Целое число. Установка любого значения из целого числа для random_state дает один и тот же результат при каждом выполнении программы. Изменение значения random_state приведет к изменению результата.
Важно помнить, что random_state не может быть отрицательным числом!
Как это работает?
Допустим, у нас есть набор из 10 чисел, от 1 до 10. Теперь, когда мы хотим его разделить на обучающую и тестовую выборки, мы решаем, что размер тестовой выборки должен составить 20% от всего набора данных.
Получается, что в обучающем наборе будет 8 чисел, а в тестовом — 2. Это важно для того, чтобы каждый раз получать одинаковые результаты при запуске кода. Если мы не перетасуем данные, то каждый раз будем получать разные выборки. А это может некачественно сказаться на обучении модели.
Немного подробнее: когда мы устанавливаем значение `random_state` для наших случайных процессов, мы фактически фиксируем начальное состояние генератора случайных чисел. Это гарантирует, что каждый раз, когда мы запускаем наш код с тем же значением `random_state`, то получаем одинаковый набор случайных чисел. И в нашем случае, когда мы используем этот `random_state` для разделения данных на обучающий и тестовый наборы, мы получаем одинаковое разделение каждый раз, когда запускаем код.
На картинке ниже показано, как это работает:
Давайте разберемся в одном важном моменте. Многие люди используют значение random_state = 42. На изображении выше видно, что при установке random_state равным 42, мы получаем один и тот же фиксированный набор данных, который был перетасован. Это означает, что каждый раз, когда мы устанавливаем random_state равным 42, мы получаем один и тот же перетасованный набор данных.
Таким образом, число 42 не обладает особым значением для random_state.
Давайте посмотрим, как это можно использовать для разделения набора данных
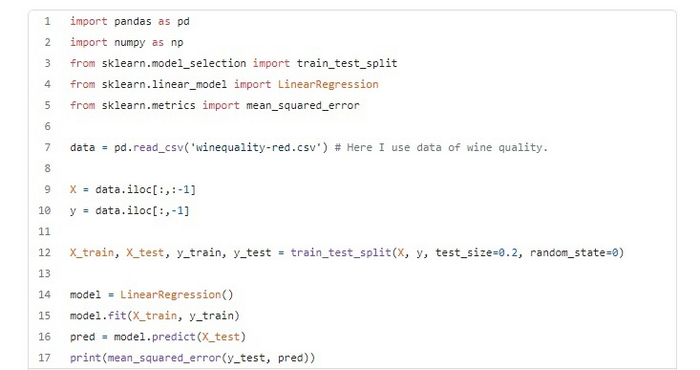
Здесь мы используем набор данных о качестве вина и модель линейной регрессии. Делаем просто, потому что наша основная цель — это random_state, а не точность.
Использование random_state при разделении
В представленном выше коде для random_state равного 0, mean_squared_error составила 0.384471197820124. Если мы попробуем разные значения для random_state, то каждый раз получим разные ошибки.
Для random_state = 1, mean_squared_error равна 0.38307198158142.
Для random_state = 69, mean_squared_error равна 0.47013897077423.
Для random_state = 143, mean_squared_error равна 0.42062134425032.
Сколько вообще возможных случайных состояний бывает?
Проведем эксперимент, чтобы определить, сколько различных комбинаций данных мы можем получить, переставляя исходный набор.
1. Мы берем набор из 5 чисел от 1 до 5.
2. Далее разделяем этот набор данных на обучающие и тестовые данные 2000 раз, используя значения random_state от 1 до 2000. Каждое значение random_state создает новую случайную последовательность разделения данных.
В итоге у нас будет список из 2000 перетасованных наборов данных, каждый полученный с использованием разного значения random_state.
Из всех этих перетасованных наборов данных только 120 окажутся уникальными. Это означает, что при использовании исходного набора данных из 5 чисел мы можем получить всего 120 различных комбинаций, переставляя их.
Установка значения random_state в диапазоне от 0 до 119 позволит нам получить одну из этих 120 уникальных комбинаций данных при каждом запуске алгоритма.
Эти выводы можно объяснить так:
Короче говоря, это про факториалы. При использовании набора данных из 5 чисел и их перестановкой, мы фактически создаем комбинации, а количество уникальных комбинаций, как можно заметить, равно факториалу числа 5, то есть 5! = 5 × 4 × 3 × 2 × 1 = 120.
Использование параметра `random_state` в этом контексте подобно выбору одной из 120 уникальных комбинаций данных. Каждое значение `random_state` соответствует одной из перестановок чисел, и они будут однозначно связаны с числами от 0 до 119, что совпадает с индексами возможных комбинаций факториала числа 5.
Этот эксперимент помогает нам понять, как параметр `random_state` влияет на разделение данных и на результаты моделирования в машинном обучении, потому что он определяет начальное состояние генератора псевдослучайных чисел. При разделении данных на обучающий и тестовый наборы с использованием `random_state` мы фиксируем последовательность случайных чисел, которая влияет на способ разделения данных.
Этот параметр важен, потому что он обеспечивает воспроизводимость результатов: при одном и том же значении `random_state` мы получаем одинаковую разбивку данных, что позволяет повторно воспроизвести эксперимент и проверить результаты моделирования. И именно таким образом, понимание того, как работает `random_state`, помогает нам контролировать случайность в нашем анализе данных и сделать его более надежным и воспроизводимым.
Зачем нам это нужно?
Давайте разберемся с random_state в контексте прогнозирования цен на жилье. Представьте, у нас есть данные о жилье, и по мере движения сверху вниз по этим данным, у нас становится либо больше комнат, либо увеличивается площадь квартир. Это то, что мы называем данными о смещении.
Теперь, если мы просто разделим наши данные без перетасовки, это даст нам неплохую производительность при обучении, но когда дело доходит до тестирования, она может быть не очень. Поэтому мы и используем перетасовку данных. Вот где random_state приходит на помощь!
Когда мы делим данные, то хотим, чтобы результаты каждый раз были одинаковыми. То есть, если мы перезапустим код, мы получим те же самые данные для обучения и тестирования, что и раньше.
Разные значения random_state могут дать нам разную производительность.
Например, разные значения random_state дают разные значения mean_squared_error.
Это означает, что если вы выберете случайное значение random_state, и вам повезет, то вы сможете свести к минимуму количество ошибок для этого значения.
Да и в других аспектах машинного обучения random_state пригодится. Например:
KMeans
В алгоритме KMeans параметр random_state определяет, как генерируются случайные числа для инициализации центроидов. Мы можем использовать целое число для того, чтобы сделать процесс генерации случайных чисел предсказуемым. Это полезно, когда нам нужно создавать одинаковые кластеры каждый раз.
Случайный лес
В классификаторе случайного леса и в модели регрессии параметр random_state контролирует начальное случайное состояние выборок, используемых при построении деревьев, и выборку объектов, учитываемых при поиске наилучшего разделения в каждом узле.
Дерево решений
В классификаторе дерева решений или регрессии, когда мы ищем наилучшие признаки для разделения узлов, тоже стоит задать параметр random_state. Этот определяет структуру дерева и гарантирует воспроизводимость результатов.
Ну, вот и всё, что вам нужно знать о random_state!
Teachable Machine - быстрый и простой способ создания моделей машинного обучения для ваших сайтов, приложений от Google.
Без специальных знаний или программирования, прямо в браузере. Бесплатно.
Даже школьник сможет с помощью веб-камеры и микрофона на своем ПК без написания кода обучать нейронные сети и экспортировать их в сторонние приложения, носители или на веб-сайты.
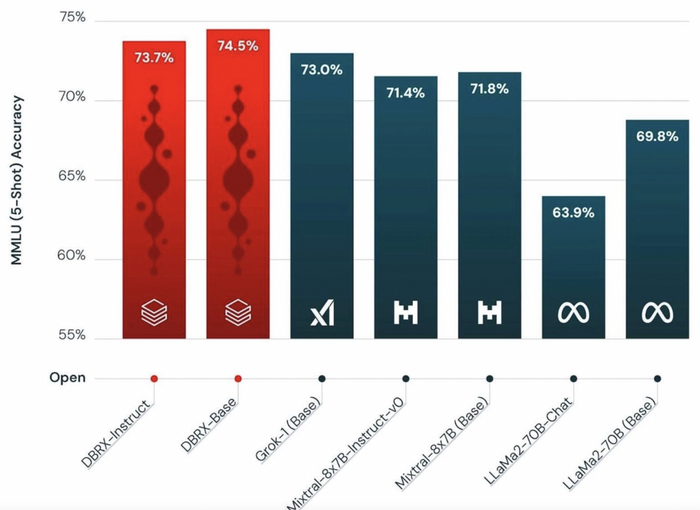
Компания Databricks только что представила DBRX, новую модель большого языка с открытым исходным кодом (LM) с ошеломляющими 132 миллиардами параметров.
Модель превосходит все открытые модели на большинстве бенчмарков.
Вот что вам нужно знать 👇
DBRX - это новая бесплатная модель искусственного интеллекта с 132 миллиардами параметров.
Может обрабатывать до 32 000 токенов одновременно.
Автор этих рвущих жёппы тезисов просто решил забайтить народ за эти самые жопы.
На самом деле это довольно капитанские и бессмысленные в большинстве своём утверждения. Ну кроме тех, которые чушь.
По порядку:
"Без кода" - чей-то чужой код.
Так и есть. Но что автор тезиса хотел сказать этим? Дело в том, что чем меньше кода решают одну и ту же проблему, тем лучше. Код - это нагрузка. За ним нужно ухаживать как за грядкой. Если вы можете решить свои продовольственные вопросы получая всё с маленькой грядки, то это во всех смыслах лучше, чем ухаживать ха огромным огородом ради того же самого набора продуктов. В случае, если этот огород ещё и не ваш, а продукты вы получаете, то это вообще идеально! Все довольны.
"Облако" - чужие сервера
Тут то же самое, что и с пунктом выше. Держать свой датацентр и свои сервера - это тот ещё геморрой. Это удел параноиков (по долгу службы или по личным предпочтениям). Если вам нужны не сервера, а результат их работы, то зачастую лучше сконцентрироваться но собственных бизнес-задачах и не пытаться автономно обеспечить себя всем.
Представьте, если бы компании не останавливались на развертывании своих датацентров, а заморачивались еще и собственным производством микрочипов, чистого кремния, добычей и очисткой металлов, производством всего спектра оборудования для производства всего спектра оборудования... Если кто-то до сих пор держит свои датацентры, то это всего лишь вопрос недоработки. Например нет нужных стандартов, нездоровый рынок в плане монополии и т.д.
"Машинное обучение" - статистика на стероидах
Ага. Но так и что же? Вы так говорите, как будто это что-то плохое.
"Искусственный интеллект" - большой объём "условных операторов" "Что Если"
А вот тут как раз чушь для хайпа или от непонимания.
ИИ (в том виде, в котором этот термин употребляется сейчас в применении к нынешним технологиям) - это не куча "ифов". Это упрощенная модель мозга, которую именно что обучили на огромном массиве данных. Как уложились данные в этой модели мозга и как получается результат нам не сильно понятнее, чем как это присходит в голове крысы, решающей задачи поиска в лабиринте. Нынешние нейронные сети, если не впадать в бессмысленное утрирование, это продукт фазового перехода сложности и объёма данных. Разница между набором условий в классическом алгоритме и нейронной сетью как между инфузорией туфелькой и смышлёным камариком, который на своих нейронах умеет в навигацию, сенсоры, адаптивность и прочее...
Подите реализуйте такого же камарика на условиях. Не имитацию, а именно функциональный аналог. А потом будете говорить что нейросеть - это ифы.
"Блокчейн" - неэффективная база данных, безопасность которой обеспечена всеобщим недоверием.
Когда заходит речь об эффективности, нужно говорить и о критериях оценки оной. Эффективность - это понятие не простое. Вот пушка не эффективна для охоты на воробья, а по испанскому галеону прошлых веков она вполне годится стрелять. Эффективность нужно рассматривать в конкретном применении. Для того, для чего придумали Блокчейн, он очень эффективен. А именно он эффективен для хранения и верификации цепочек транзакций в среде без доверия. Просто нет альтернатив.
"Биг дата" огромный объём данных с которым никто не знает что делать.
Тоже, знаете ли... Если вы не знаете, то это не значит, что никто не знает. Да, постоянно находятся новые применения, и это везде так. Иногда бигдату имеет смысл собирать на будущее.
"Умный дом" - дом, который знает о твоей диете больше тебя.
Вообще бред какой-то. Правильно в наших реалиях так: Умный дом - это штука, которая создаёт проблем больше, чем решает, и вопреки предназначению постоянно раздражает пользователей неочевидным поведением в вопросах, в которых привычна простота.
Я тоже большой поклонник вот этой всей херни с умным домом, но это не значит, что рядом с такими энтузиастами как я приятно и комфортно жить. Особенно когда я в командировке без связи, а свет почему-то включается в спальне в 3 часа ночи каждые десять минут.
"Виртуальная реальность" - модный способ игнорировать окружающую действительность.
Это скорее про социальные сети. Виртуальная реальность - это как ИИ (до недавних пор). Мы сраные десятилятия "вот вот" придём к этой самой виртуальной реальности, а на деле получаем 3д-телевизоры на полтора раза поиграться, гугл-в-глас - очки о которых все забыли уже, тошнотворные задержки и невозможность нормально "ходить"=). Всё это впереди, но когда - это пока не понятно. Не наступил момент фазового перехода, как с нейросетями сейчас происходит.
Если с нейросетью уже можно пообщаться получив много пользы, то провести с пользой время в VR пока есть ГОРАЗДО меньше возможностей.
"Квантовые вычисления" - технология смысл которой даже разработчики полностью не понимают.
Ну да, но там всё не так сложно, если не лезть вглубь и не пытаться что-то с помощью этого сделать. =) Очередная научная свистоперделка для обывателей, которая выльется в реальные полезные технологии ещё когда-нибудь потом в будущем. А пока нужно иметь большую головчу и гору энтузиазма, чтобы копаться и разбираться вэ том. Жаль, что процент таких людей не велик.
"Интернет вещей" - способ сделать так, чтобы даже твой тостер можно было взломать через интернет.
Ну тут, если сцедить яд, то примерно так и есть=). Однако это тенденция и она есть. Со временем это выльется в красивую незаметную магию технологий будущего. Будущего, в котором вам не надо будет задумываться о связи, о настройках этой связи, о совместимости... Будет магическое мышление без особого понимания как оно там внутри устроено. Сейчас так многие ездят на машине не особо вдаваясь как там у нее работает трансмиссия и ДВС. Многие играют и работают на компьютерах не вникая как там алгоритмы перемалывают для этого гигабиты. В какой-то момент такая же магия придёт и в локальную бытовую автоматизацию рутинных вещей. Свет будет гореть там, где он нужен, а там где не нужен - не будет. И в 80% случаев этого будет достаточно, а для остальных 20% можно будет сделать магический пасс рукой в сторону лампочки, и она засветится. Может быть нужно будет ещё произнести "Люминос максима".
То же и про тостер. Тосты просто будут готовы когда они вам нужны, но если тостер не угадал пока, или не "привык" ещё к вам, то можно будет махнуть ему рукой в специфическом жесте, и он всё поймёт как надо.
Взломы всего этого тоже, кстати, обещают быть в будущем эпическими и интересными. Жду будущего всегда с интересом и нетерпением, но, надо сказать, что и вокруг нас уже полно этого самого "будущего". Надо уметь видеть.