

Кухня переводчика-фрилансера
В продолжение этой и этой темы:
https://pikabu.ru/story/pro_perevod_6420875
https://pikabu.ru/story/ya_zh_perevodchik_6419304
Пару слов о себе — я переводчик-фрилансер с 2006 года, английский язык, тематики: юриспруденция, экономика, IT, общая.
Но здесь я хотел бы рассказать не о тонкостях перевода различных тематик, объёме работы в день, процедуре поиска заказчиков, а о техниках, применяемых при переводе. А их довольно много. Смею надеяться, что мой пост сделает работу современного переводчика более понятной для обывателя, а также позволит моим коллегам чему-то научиться или поделиться своими вариантами выполнения той или иной задачи.
Процесс подготовки документа
Если документ прислан в редактируемом формате, то пробежаться по нему глазами всё же крайне желательно. Иногда документ бывает некачественно распознан из PDF самим бюро или даже заказчиком, а предложения в нём — разорваны посредине. Иногда часть документа бывает не распознана (остаётся картинкой), а менеджер второпях этого не видит. Всякое бывает. Всегда смотрите, что суёте в кошку (поясняется ниже). Также существенную помощь оказывает утилитка TransTools. Например, она умеет чистить документ от лишнего форматирования, который человек в распознанном документе своими глазами не видит, умеет автоматически создавать из обычного договора договор в две колонки (одна из которых остаётся как есть, а вторая идёт под перевод) а также имеет ряд других полезных функций.
Если формат изначально нередактируемый, в дело вступает ABBYY FineReader. Лично я предпочитаю сохранить документ в виде «только текст» и сверстать всё заново, максимально близко к вёрстке оригинала.
Суём документ в кошку
«Кошка» для переводчика означает один из CAT-инструментов, что расшифровывается как Computer-Assisted Translation (также часто пишут Computer-Aided Translation). Не путать с машинным переводом, это совершенно разные вещи! Ниже рассматривается и то, и другое.
Мою любимую кошку зовут MemoQ. И документ на перевод в неё суётся следующим образом:
1. Создается проект
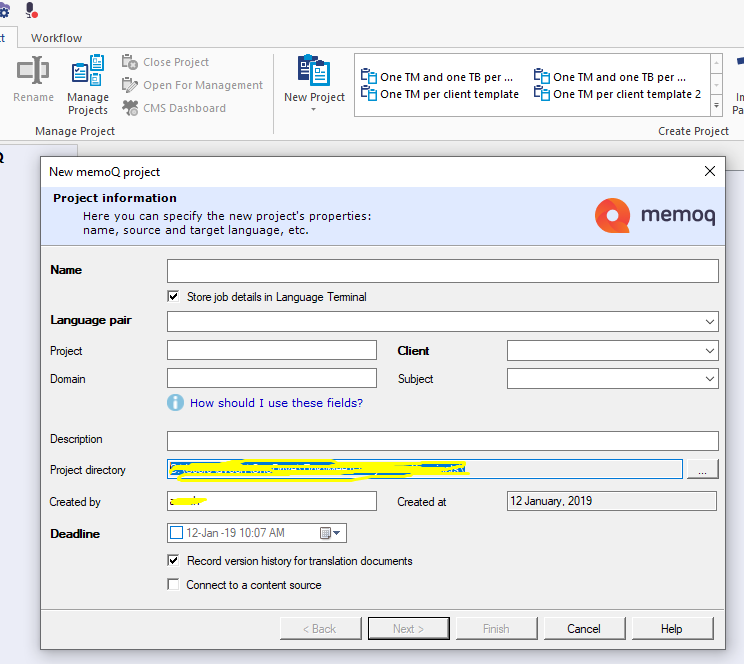
В нём указываются номер/название проекта, клиент, выбираются язык исходного документа и язык перевода.
После загрузки проекта получаем вот такую рабочую атмосферу (это не реальный договор, я просто набросал насколько типовых строчек):
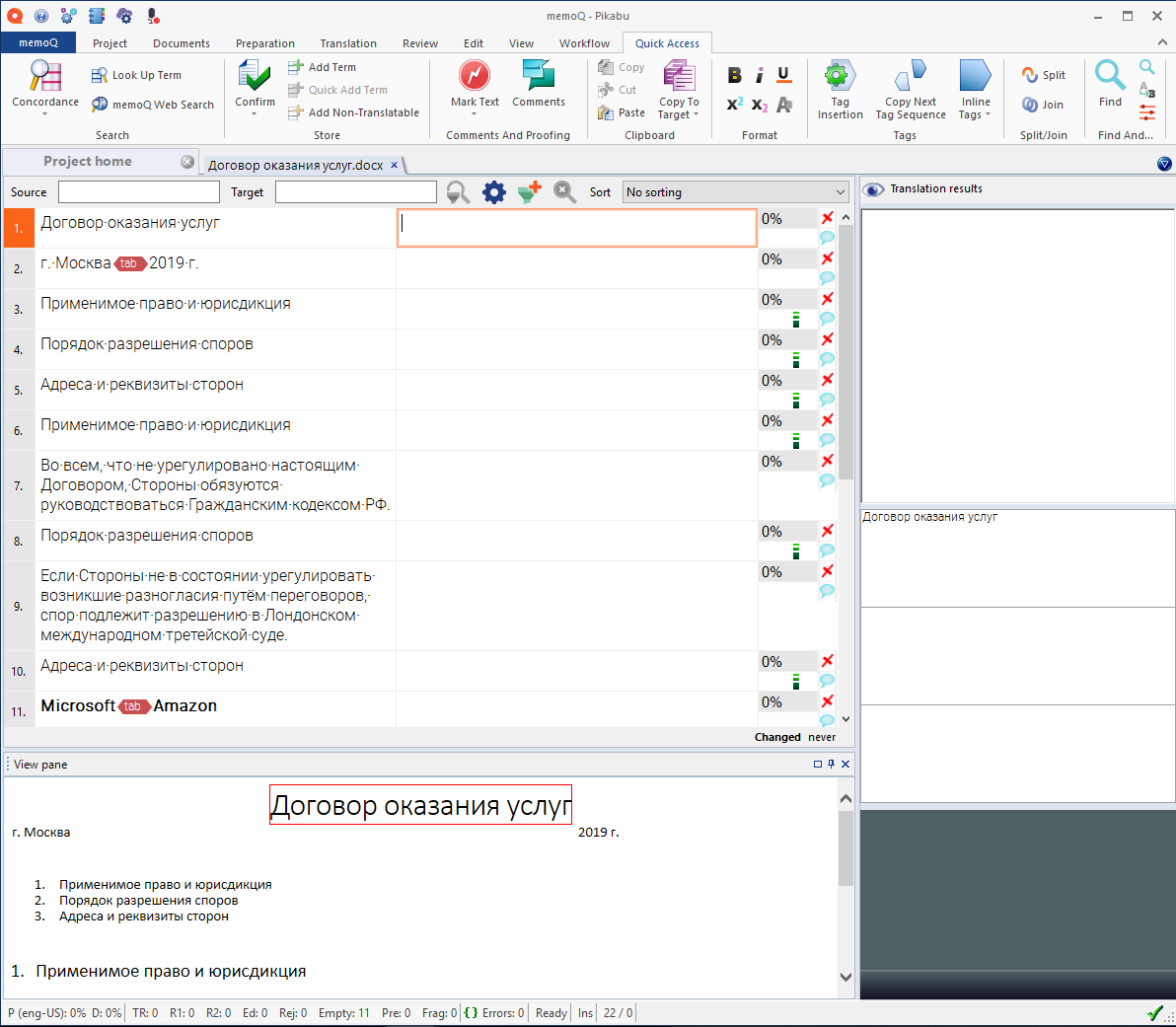
В центре и немного влево (в две колоночки) — область трудов праведных. Слева — как было (source), справа — как будет (target). А вместе это всё, каждая отдельная «строчка» — так называемый «сегмент перевода». Как видите, сегменты даже пронумерованы, чтобы переводчик мог написать менеджеру - «у вас в таком-то сегменте херня написана, спросите клиента, что он вообще имел в виду».
Внизу виден сам документ, поскольку правильность перевода иной раз зависит от контекста расположения соответствующего слова или предложения. Слева видны совпадениях и баз переводов и терминологических баз (в данном случае базы сейчас пусты и ничего не видно).
Машинный перевод
Становится всё лучше, должен заметить. Надеюсь, что на моём веку не станет лучше меня лично как переводчика (но на всякий случай уже активно изучаю программирование).
Для машинного перевода использую небольшую тулзу под названием QTranslate (в настройках указываю Гуглоперевод, хотя при желании там можно указать и другие сервисы). Маленькое редактирование горячих клавиш в настройках QTranslate
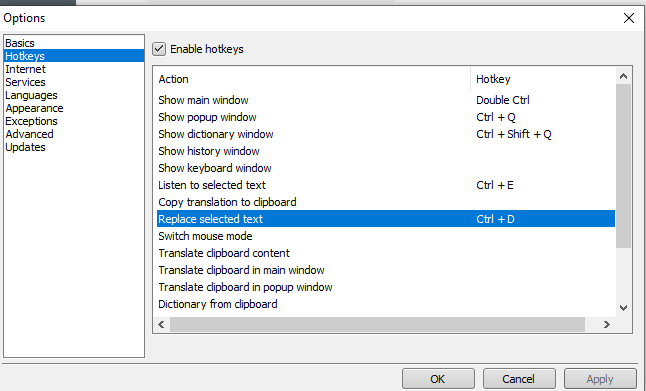
позволяет делать следующую магию:
1. Копируем текст их source в target (Ctrl + Insert)
2. Выделяем в target и нажимаем Ctrl + D
3.....
4. Profit!!!! Текст в target внезапно перевёлся на нужный язык!!!
(разумеется, сперва нужно указать в настройках QTranslate нужные языки)
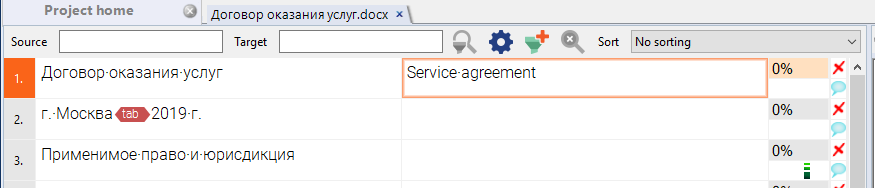
Урра, результат вполне крут. Разве что я второе слово тоже написал бы с большой буквы. Исправляем на Service Agreement и идём дальше, подтверждая переведенный сегмент клавишами Ctrl + Enter.
При этом эта пара (исходный текст + текст перевода) попадают в так называемую «память переводов» (translation memory). Зачем это нужно? Терпение, друзья, всё поймёте далее.
Переходим к следующему сегменту. Эта хрень непонятного красного цвета называется тег. Их необходимо переносить в target, поскольку это — элемент вёрстки. Уважайте теги! Иначе документ на выходе превратится в кашу (или вообще не сможете его экспортировать).
Переводим - выделили слово «Москва», нажали волшебные клавиши Ctrl + D, затем убрали « .г». Великолепно!

Следующий сегмент - ещё интереснее. Обратите внимание, что сегменты 3 и 6 у нас одинаковые. Переводим сегмент 3. Маааагия!!!

Итак, сегмент 6 тоже переведён. Теперь понимаете, зачем нужно, чтобы сегмент попадал в память переводов? Причем при подтверждении сегмента 3 перевод не только попал в базу, MemoQ ещё при создании проекта увидела, что сегменты 3 и 6 идентичны, и тут же подсунула в сегмент 6 перевод, внесённый в базу (память) переводов в момент подтверждения сегмента 3. Умная кошечка, очень умная. Это называется 100% совпадение (100% match). Ну разве не круто?
Но не кажется ли Вам избыточным копировать сегмент из source в target, потом выделять его, потом нажимать Ctrl + D? Вот и мне кажется. Поэтому в дело вступает программа Autohotkey.
Вот написанный мной для этого скрипт:

Теперь можно, перейдя на следующий сегмент, просто нажать Ctrl + Shift + D, и вуаля! Единственное, теги придётся расставить заново ручками. Но это же мелочи, правда?
А вот машинный перевод сегмента 4 можно и поправить:

Ибо ниже про Лондонский международный третейский суд. Поэтому пусть будет так:

Это я к тому, что машинный перевод можно и нужно править. В 99 случаев из 100.
Идём дальше. Машинный перевод меня опять не устраивает полностью, поэтому исправим и дополним:

Завершаем перевод оставшихся двух сегментов. Опять нужно вносить исправления — вносим, будет так:

Хм... Следующий сегмент требует пристального внимания. Машинный перевод - всегда нуждается в проверке и перепроверке:

If the Parties are unable to resolve the dispute by negotiation - говорят ли так носители? Проверить легко, ведь есть же Autohotkey, где имеется такой скрипт:

Суть скрипта - поиск выделенного текста в Google, причём в обрамлении кавычками (на предмет точного соответствия). И что же мы видим?
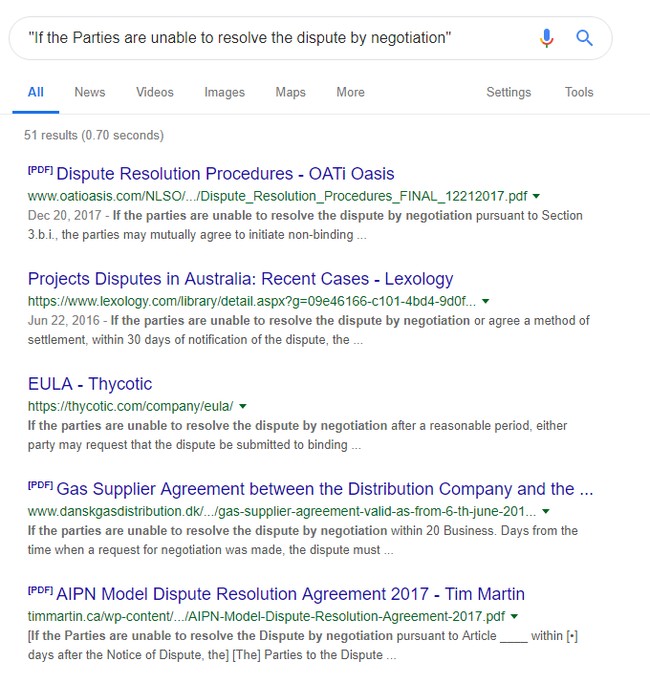
Как-то маловато совпадений, хотя последняя ссылка на картинке, судя по домену — Канада, вроде как носители языка. Сочетание горячих клавиш Ctrl + Alt + G у меня - одно из наиболее частных, я всегда проверяю употребляемые мной фразы - а говорят ли так носители вообще? Если совпадений в Гугл несколько сотен тысяч или миллионов — то как-то более уверенно себя чувствуешь.
Та же петрушка с London International Arbitration Court — Ctrl + Alt + G что-то маловато вариантов находит. И немудрено, правильное название, как услужливо подсказывает Google — London Court of International Arbitration. Поэтому данный сегмент пусть будет переведён так:

Далее видим сегмент, который вообще не нужно переводить. Хм... Ладно тут он один такой. А если в документе их куча? Как бы их найти и сразу подтвердить? А легко! Благо, MemoQ поддерживает фильтр по регулярным выражениям:
1. Активируем фильтр:
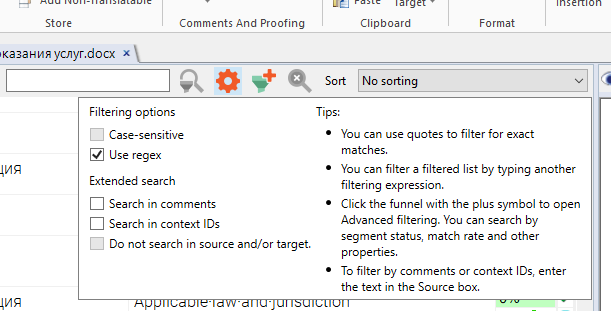
Ищем все исходные сегменты, в которых нет кириллицы:

Вуаля! Отображается только сегмент 11. Где нет кириллицы, а есть только тег и латиница. Как видим, Regexp переводчику весьма полезен, и тот факт, что многие кошки его поддерживают — тоже.
Думаете, всё? Как бы не так.
Перевод ещё нуждается в вычитке (proofreading) и проверке качества (QA-check).
Лично я делаю так — переключаюсь в настройках на Редактора 1
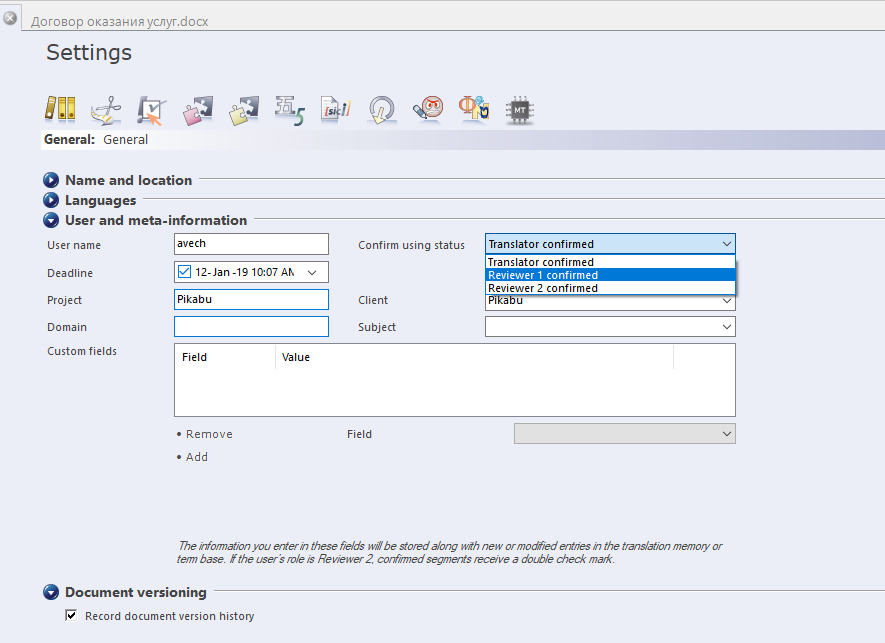
И прохожусь по всему переводу заново на предмет «ещё раз вдумчиво прочитать». Очень много вещей на этом этапе дополняются и исправляются, не стоит пренебрегать этим этапом вычитки. Ещё одна вычитка — проходит по уже экспортированному документу, каким он будет представлен заказчику. Лишний раз вычитать — никогда не мешает. Вычитывайте. И потом ещё раз.
QA-check
Человеку свойственно ошибаться. Поэтому, даже при самой тщательной вычитке, человеческий глаз может что-то упустить. Давайте внесем в документ пару ошибок.

Мы перепутали год, два раза написали and и поставили два пробела вместо одного. Да ещё и при вычитке, уставшие и с замыленным взглядом всё это пропустили. Но давайте прогоним QA-check:
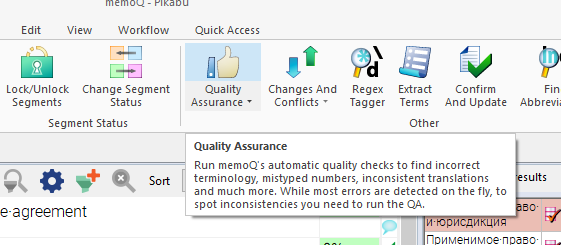
Погнали!
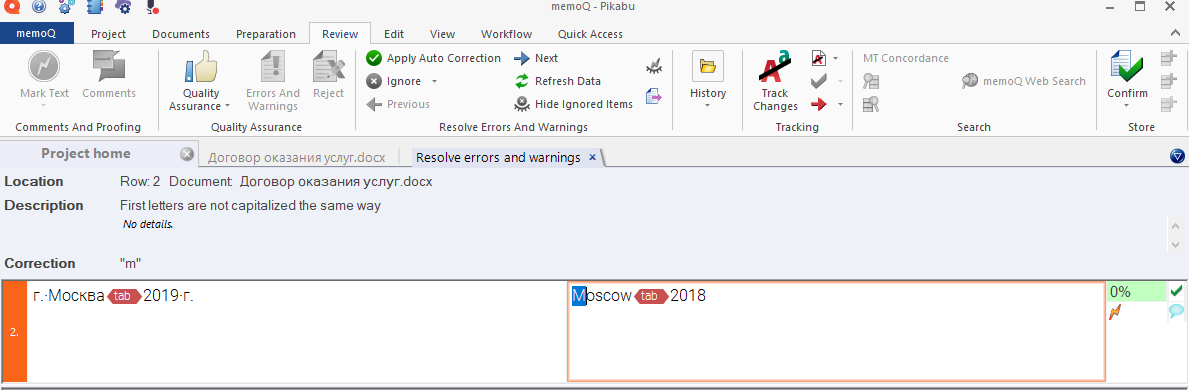
Так, тут всё норм. Не совпадает регистр первой буквы («г.» и “M”). Одна маленькая, другая большая. Так и должно быть. Жмём Ignore (Игнорировать).
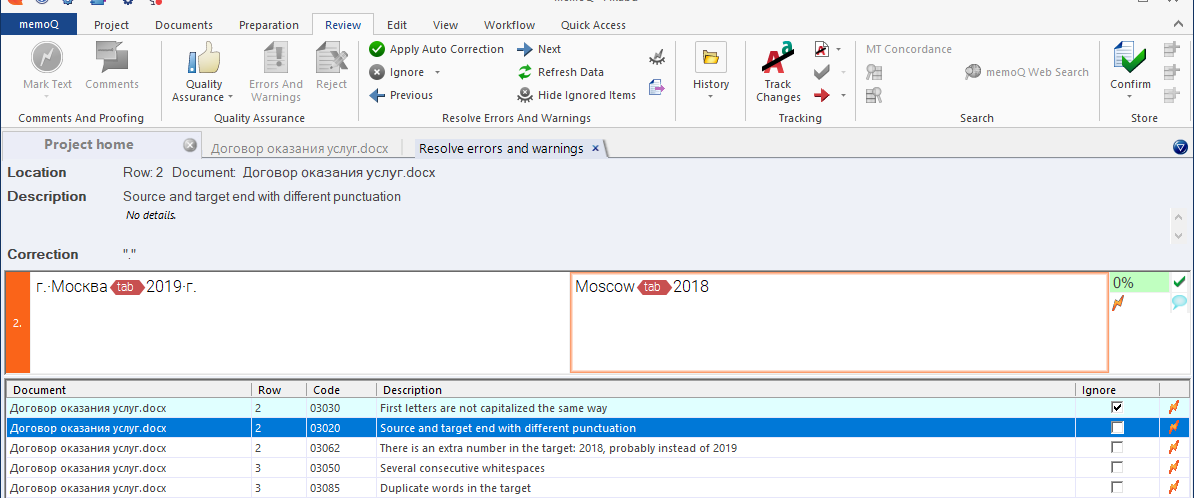
Различия в пунктуации (в исходнике точка есть, в переводе — нет) нас тоже устраивают. Ignore.

Так, а год-то неверен! Причём MemoQ даже пытается предположить, каким именно образом накосячил переводчик.
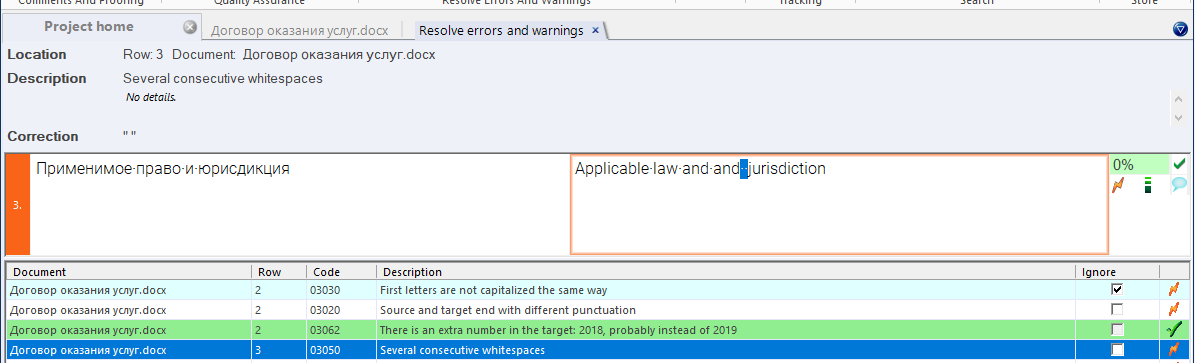
Лишний двойной пробел кошка тоже видит:
Равно как и два and подряд (а вот тут у меня наступает ограничение на количество блоков в посте, поэтому скрина не будет). Просто поверьте на слово — кошка видит :)
И вот после этих проверок, документ можно экспортировать, ещё раз читать, и отдавать в трясущиеся от нетерпения руки заказчика. Заказ выполнен.
P.S.
В завершение немного о применяемых ресурсах:
1. Мультитран — онлайн-словарь (очень осторожно, там рядовые пользователи всякую хрень пишут не так уж и редко);
2. Проз (proz. com/ search) — онлайн-словарь, там хорошие пояснения, часто от носителей языка, можно самому задавать вопросы.
3. Транскриптор Лебедева — произношение имен, написанных на ряде языков, о чтении на которых я лично не имею ни малейшего представления (румынский типа, или болгарский — хотя какая разница? (с))
4. ABBYY Aligner — создание памяти переводов из двух документов, где один — исходник, а второй — перевод.
Если ещё чего вспомню — дополню в комментариях. В оных же постараюсь ответить на ваши вопросы.
Я не профессиональный переводчик, но по работе приходится писать кучу документации на языке потенциального противника. Мне в последнее время нравится context.reverso.net для проверки "а как обычно эту фразу переводят?"
Подскажите как удобнее перевести книгу на 200+ страниц (англ—>рус)? Начала вашими тулзами, но это нереально долго. Прикинула на калькуляторе - мне понадобится полтора месяца на это.
И можно у вас попросить скрипты в печатном виде, а не картинкой? Мб в телеге..
Я раньше пользовалась Традос на винде, потом на шесть лет ушла в последовательный перевод. Сейчас подумываю вернуться в удалённые письменные. Не хотелось бы ставить симулятор винды на макбук, думаю освоить другую кошку не будет проблемой.
Я ретроград. Мне легче переводить самому, чем потом тратить массу времени на правку.
Кошки, по моему глубокому убеждению, хороши лишь для однотипных табличных перечней, номенклатур и т.п.
А сейчас, когда можно не печатать, а наговаривать текст прямо в ворд, я и не подумаю пользоваться всякими традосами и пр. Хотя тут, конечно, дело привычки.