


Куда спрятались гены? (Как читать геномы. Продолжение)

Начало истории о том, как читают генетический код было тут: https://pikabu.ru/story/kak_chitayut_geneticheskiy_kod_56254...
[Продолжение]
Мы получили строчку текста, в которой не знаем, где начало, где конец, но в которой, возможно, записан ген. А может быть и нет.

Почему строчка ДНК не обязательно содержит ген?
Давайте посчитаем. В геноме человека почти три миллиарда пар оснований (то есть букв на каждой из двух цепей ДНК).
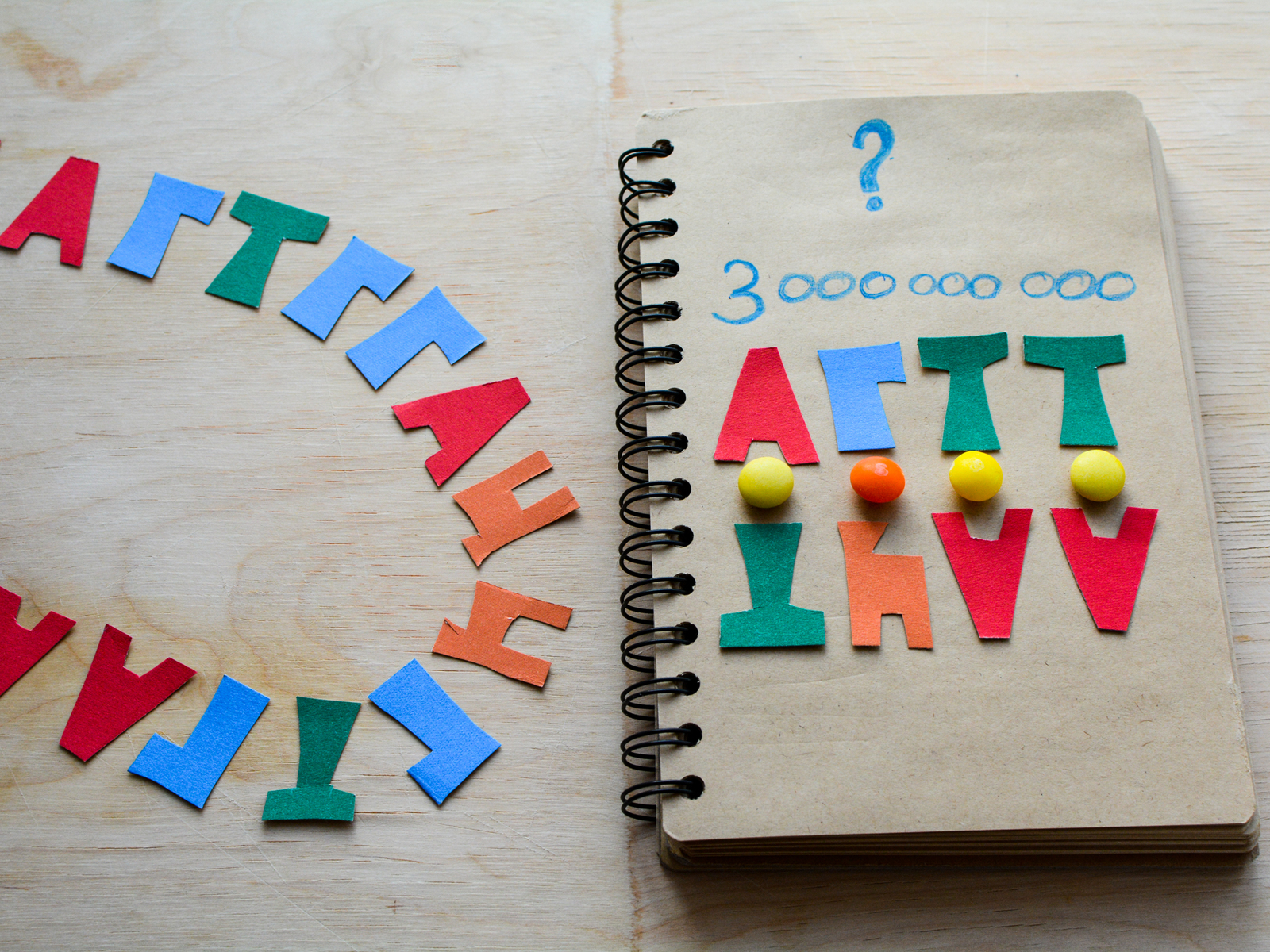
В одном генетическом слове 3 буквы. Итого получили миллиард возможных слов (закодированных аминокислот).

Сколько нужно слов, чтобы записать белок? От 2х до нескольких сотен. Давайте округлим в большую сторону и примем, что длина белка 1000 аминокислотных слов.
Делим 1 000 000 000 на 1000 и получаем 1 000 000(!) возможных белков.
Вот только... по оценкам на сегодняшний день в ДНК человека белков всего... чуть более 20 000!
То есть 20 000 / 1 000 000 = 2/100 = 0,02 или 2% (а на самом деле ещё меньше, около 1%)
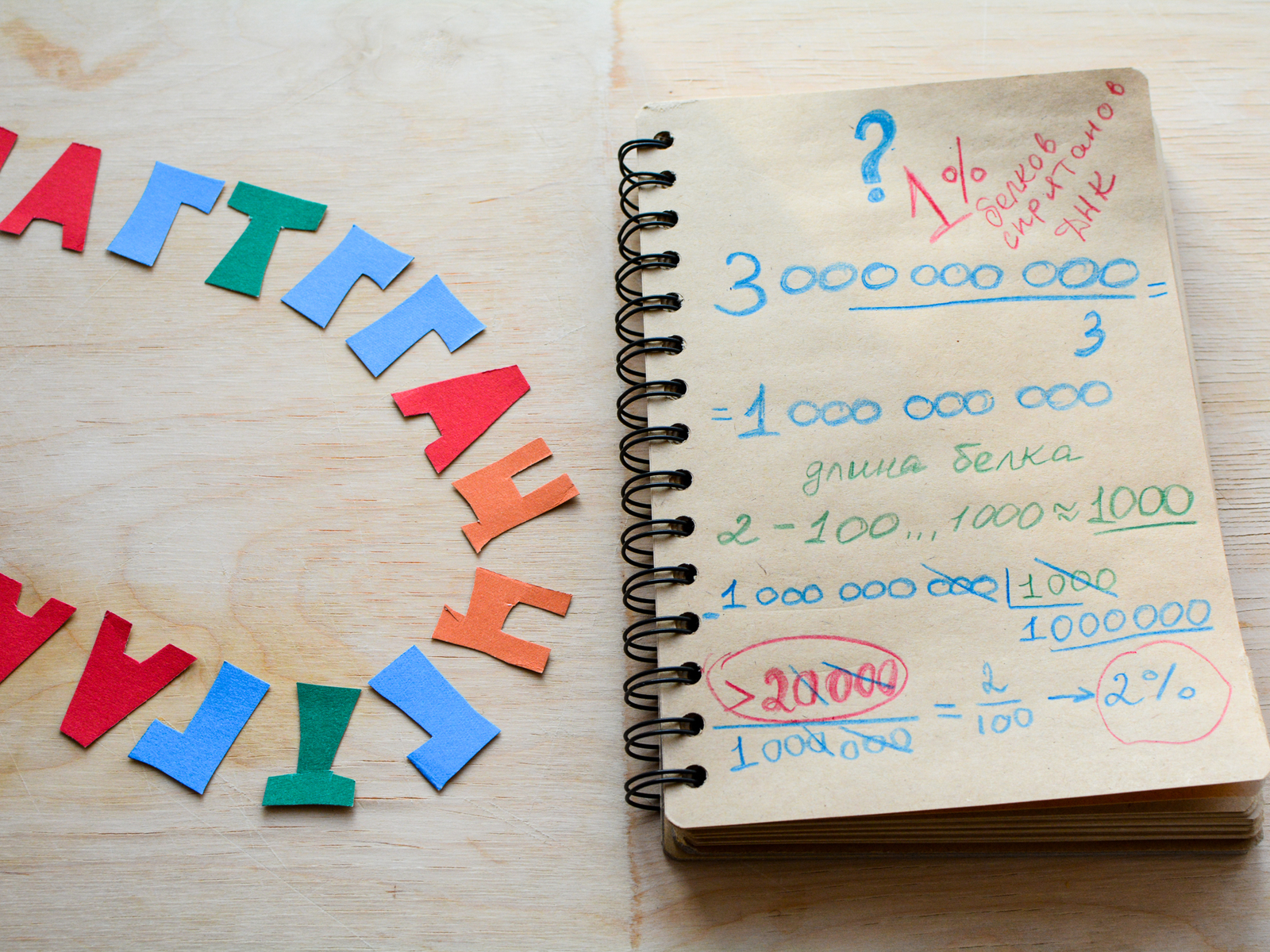
Представьте, вы получили кусочек непрерывного текста, в котором надо найти что-то, у чего неизвестно начало, непонятна его длина, а ещё и вероятность найти хоть что-то в довольно небольшом «отрывке» общей «ДНК-книги» мизерная!
Примерно, как разделить текст этого поста на произвольные кусочки, вставить эти кусочки в текст двухтомника Майн Рида, положить в измельчитель и попробовать восстановить исходный текст поста, содержимое которого мы только примерно представляем:)

Но и это не конец условий задачи: гены ядерных организмов (к которым мы с вами относимся) состоят из нескольких кодирующих частей - экзонов, разделённых длинными кусками «белиберды» - интронов. То есть: кусочек гена, «мусор», снова кусочек гена, «мусор» и так много раз. (прим.: автор текста в курсе, что "мусор" это давно уже не мусор, но об этом в простых примерах он расскажет в другой раз)
Крутая задачка? Дзен-пазл нервно курит в сторонке:)
В общем, вновь время звать биоинформатиков.
Задача предсказания генов ещё одна проблема, в которой нужен мозг математика и навыки программиста.
P.s.
И еще одно примечание. Меня упрекнули в прошлых постах, что я рассказываю элементарщину, которую все должны помнить со школы. Но, к сожалению, мой опыт популяризации показывает, что помнят это всё лишь те, кто и сам интересовался темой впоследствии.
Я пишу для тех, для кого школьная биология была "непонятной и скучной", для тех, у кого (как, кстати, у автора) школьную биологию вел некомпетентный преподаватель (у автора ее вел священник. В обычной школе, да).
Для тех, кто открыт воспринять новое, когда оно рассказано просто и, надеюсь, понятно.
А еще я пишу для тех, кто сам занимается популяризацией, и для тех, у кого есть дети-школьники.
В общем, если вам очень хочется поставить минус и в очередной раз написать "автор, ты что нашел школьный учебник и решил поделиться?", знайте, вы не первый:) Но есть те, кому это нужно и интересно. Пройдите мимо и прочтите что-то более подходящее для вас:)
Конечно, должны. Вот только гомеопатия до сих пор успешно продается с витрин аптек, а против высокотехнологичной ГМ-индустрии до сих пор выступает немалый процент населения. Хотя физика, химия и биология (в необходимом минимальном объеме) в школе были у всех, и в ВУЗе у многих.
Порой очевидные нам вещи для окружающих совсем не очевидны. На то существуют разные причины (низкий познавательный потенциал, некомпетентные педагоги, отсутствие мотивации, некачественные источники информации, отсутствие критического мышления, эффект Даннинга-Крюгера, Елена Малышева, Геннадий Малахов и другие), но грустный факт остается грустным фактом.
Поэтому, пожалуйста, не останавливайтесь, пишите. Капля камень точит :-)
Всё хорошо, но много неточностей. Например, Нельзя говорить про 1 миллиард "генетических слов", потому что возможен сдвиг рамки считывания. Нельзя говорить, что для кодирования белка нужно от двух триплетов - мРНК содержит как минимум всякие 3'- и 5'-UTR. И нельзя говорить о 20 000 белков в ДНК, правильней говорить о генах (и их, если мне не изменяет память, около 25к), так как существует альтернативный сплайсинг.
Понятно, что популяризация связана с упрощениями, но упрощение не есть перевирание. Лучше сделать оговорку или вообще не упоминать о чём-то, чем создавать ложной мнение. В том-то и сложность работы популяризатора.
Читают не код все-таки, а последовательность букв. Код - это таблица соответствия кодонов и аминокислот.