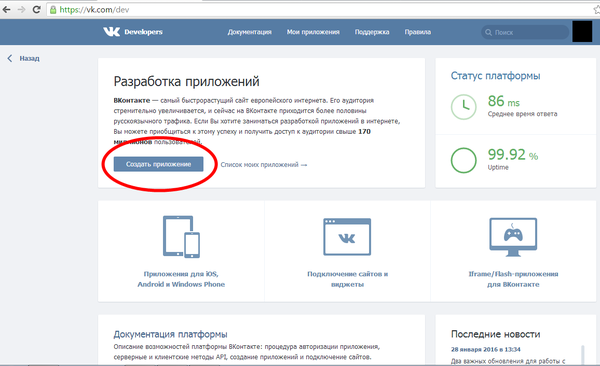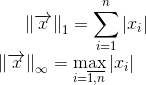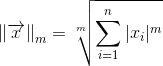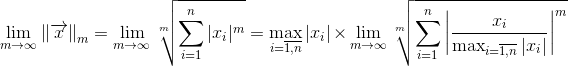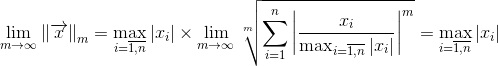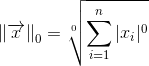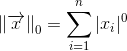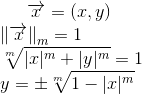


Код Хэмминга (7; 4)
Всем привет! Сегодня я хочу рассказать вам немного о коде Хэмминга (7; 4). Этот простейший код может быть с лёгкостью применён любым человеком для передачи самокорректирующихся сообщений , и сегодня я хочу вам показать как именно этот код можно легко и просто использовать.
Структурно слова кода Хэмминга состоят из двух частей. Сначала идут информационные 4 бита, затем три бита проверочных. Будем обозначать информационные биты буквами ABCD, проверочные буквами xyz.
Таким образом слово кода Хэмминга имеет следующую структуру:
ABCDxyz
Для передачи 4 бит информации нам требуется передавать кодовое слово из целых 7 бит! Последние три бита в случае, когда ошибки отсутствуют, не несут никакой новой информации, ибо они зависят от первых 4. Однако если в кодовом слове из 7 бит произошла 1 ошибка, то исходные информационные 4 бита всё равно можно будет восстановить точно! В этом и состоит главная особенность самокорректирующихся кодов.
Естественно, использование кода Хэмминга при передаче данных требует увеличенных ресурсов. Здесь есть такое важное понятие как скорость кода -- отношение числа информационных бит к общему числу бит. В случае кода Хэмминга скорость равна 4/7. Т.е., к примеру, чтобы передавать информацию со скоростью 1 Мбит/сек и коррекцией ошибок с помощью кода Хэмминга вам потребуется канал с пропускной способностью минимум в 7/4=1.75 Мбит/сек.
Для подсчёта проверочных бит можно использовать следующие формулы:
x = A + B + C mod 2,
y = A + B + D mod 2,
z = A + C + D mod 2,
где n mod 2 означает остаток от деления числа n на 2.
К примеру, если информационный вектор есть ABCD = 1001, то кодовый вектор будет ABCDxyz = 1001 100
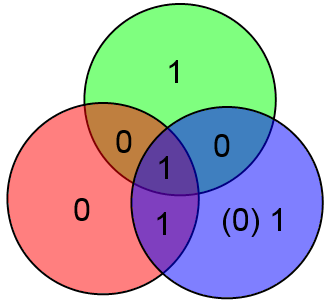
Вместо непонятных формул можно использовать следующую картинку:
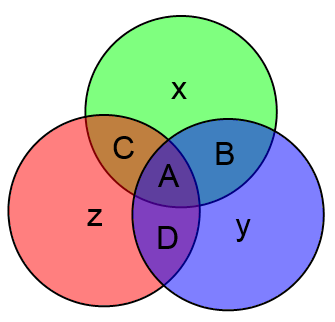
Здесь всё очень просто. Подставляете вместо букв значения соответствующих битов и затем считаете значения x, y и z как сумму по модулю 2 тех информационных бит, которые есть в соответствующем круге.
В приведённом выше примере будет:
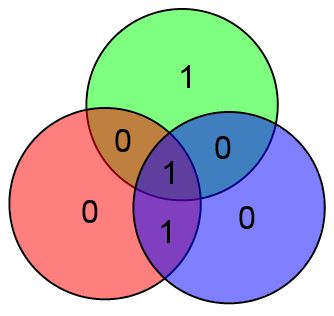
Куда более интересным является вопрос об исправлении ошибок. Очевидно, вывод об отсутствии ошибок приёмник может сделать просто взяв информационные биты ABCD, посчитав на их основе проверочные биты xyz и сравнить посчитанные проверочные биты с принятыми. Если есть ошибка, то часть проверочных битов не совпадёт.
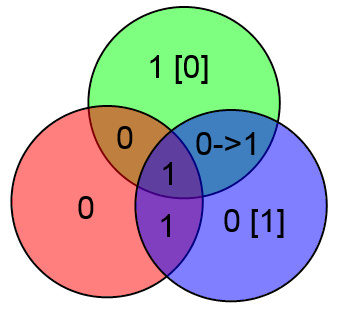
Предположим что произошла ошибка в проверочном бите y и было принято слово 1001 110
В таком случае два проверочных бита сойдутся, а один нет. Этого вполне достаточно чтобы сделать вывод что нужно исправить бит y (для которого проверка не сошлась).
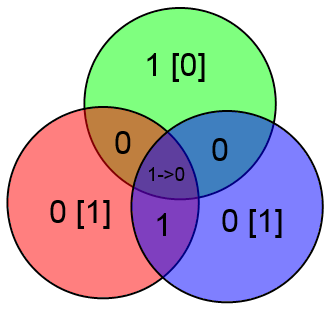
Предположим, что произошла ошибка в одном из информационных битов BCD -- к примеру в бите B.
В таком случае не сойдутся аж два проверочных бита -- x (он равен 1, а "должен" равняться 0) и y. Посмотрев на круги легко увидим что они пересекаются по битам B и A. Т.к. не сошлось две проверки, то берём бит B (расположенный на пересечении двух проверок).
Наконец, отдельно рассмотрим бит A. Если в нём ошибка, то у нас не сойдутся все три проверки:
Увидев такое безобразие сразу же делаем вывод о том, что ошибка в бите A.
Таким образом, можно легко и просто вычислять локацию ошибки и исправлять её. Замечу что если ошибок больше одной, то описанный выше алгоритм сработает неверно. К примеру, допустим что произошли ошибки в битах C и z:
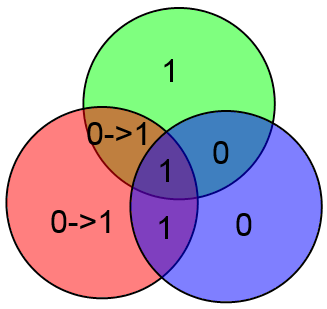
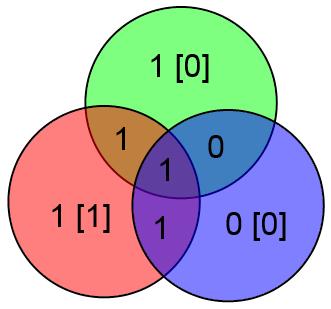
Проверочные биты y и z сойдутся, а бит x нет. Алгоритм исправит бит x и всё. Это вполне естественное поведение, т.к. если вероятность ошибки p < 1, то вероятность двух ошибок меньше чем вероятность одной ошибки (p^2 < p <= p < 1 при p <> 0).
Естественно, работать с цветными кругами удобно человеку, но неудобно компьютеру. У кодов Хэмминга есть одна особенность, которая позволяет их лёгкое декодирование на компьютере. Итак, рассмотрим следующий алгоритм:
Определим числа g, b, r как сумму всех четырёх бит в кругах соответствующего цвета. Т.е.:
g = A + B + C + x mod 2,
b = A + B + D + y mod 2,
r = A + C + D + z mod 2.
Фактически каждый из этих бит можно определить как сумму соответствующего проверочного бита, вычисленного на основании принятых информационных бит, с принятым проверочным битом. Т.е. к примеру g есть сумма (A + B + C mod 2) (по этой формуле считался x на стороне передатчика) и принятого x. Аналогично b соответствует y, r соответствует z.
Если ошибок нет, то gbr = 000 (принятые проверочные биты сошлись с вычисленными на основе информационного вектора).
Если же есть 1 ошибка, то число gbr есть номер (в двоичной записи) ошибочного бита в векторе ABCxDyz.
В качестве примера рассмотрим уже знакомый нам вектор ABCDxyz = 1001 100, в котором произошла ошибка в бите x (четвёртый бит в векторе ABCxDyz). Посчитаем gbr:
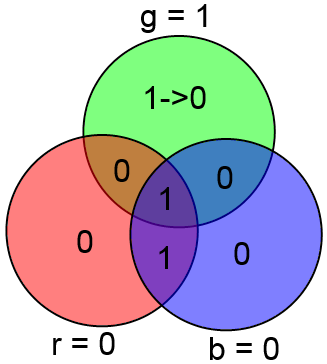
gbr = 100 [2] = 4 [10]. Ошибка в 4 бите, которым и является x. Таким образом, для декодирования и исправления ошибки в кодовом слове длины 7 требуется лишь вычислить три суммы и из полученного числа несложной функцией получить местонахождение ошибки.
На этом всё, спасибо за внимание!