
Дизайнеры творят чудеса
больше видео - https://t.me/bobstudiomagazine
больше видео - https://t.me/bobstudiomagazine
Meshy-3 является передовой системой, использующей нейронные сети для создания впечатляющих 3D-моделей.
Что нового в Meshy-3?
Прежде всего, система теперь способна генерировать 3D-модели не только на основе текстовых инструкций, но и путем анализа фотографий. Это позволяет художникам и дизайнерам быстро воссоздавать реальные объекты в виртуальной 3D-среде.
Также Meshy-3 предлагает целый ряд усовершенствований, по сравнению с предыдущей моделью, которые включают:
1.улучшенную детализацию текстур-модели отличаются исключительной четкостью и реалистичностью, что делает их пригодными для использования в самых разных проектах;
2.повышенное качество полигонов в скульптурном стиле-художники теперь могут создавать невероятно органичные 3D-скульптуры;
3.PBR и функция добавления патчей – это усовершенствованные средства редактирования, которые помогают довести объекты до совершенства
Попробовать бесплатно возможности этой модели можно здесь
Сервис работает без vpn, но требует регистрации

Бюст штурмовика создан при помощи Dall-E и tripo3d.
Астрологи объявили взрывной рост объемов 3D-контента — только за последние месяцы опубликовано 13 статей про генерацию трехмерных объектов из текста и изображений.
SV3D: Stability AI показала новую модель для реконструкции изображения в 3D с высоким разрешением.
LATTE3D от NVIDIA: новый метод преобразования текста в 3D, позволяющий генерировать текстурированные сетки из текста всего за 400 мс.
Isotropic3D: генерация изображения в 3D на основе создания многоракурсных плоских изображений.
MVControl: преобразование текста в 3D с управлением по типу ControlNet (резкость, глубина и т. д.).
Make-Your-3D: преобразование изображения в 3D с возможностью управления генерацией с помощью текстовых подсказок.
MVEdit: поддерживает преобразование текста в 3D, изображения в 3D и 3D в 3D с генерацией текстур.
VFusion3D: преобразование изображения в 3D на базе предварительно обученных моделей видеодиффузии.
GVGEN: преобразование текста в 3D с объемным представлением.
GRM: эффективное преобразование текста в 3D и изображения в 3D за 100 мс.
FDGaussian: преобразование изображения в 3D с предварительной генерацией разных ракурсов в 2D.
Ultraman: преобразование изображения в 3D с упором на человеческие аватары.
Sculpt3D: и снова преобразование текста в 3D.
ComboVerse: преобразование картинок в 3D с комбинированием моделей и созданием сцен.
Не везде доступен код, так что сравнивать сложно, но первые результаты уже есть. Я сравнил восемь image-to-3d нейронок на картинках, сгенерированных в Dall-E. Все модели созданы при настройках по умолчанию.

2. TripoSR

3. CRM

4. GRM

5. mvedit

6. InstantMesh

7. tripo3d


Условно, эти решения делятся на три группы.
Самые слабые - GRM и dreamgaussian не справляются реконструкцией невидимых на картинке деталей и оставляют сквозные отверстия. Они создают деформированные, непригодные для дальнейшей обработки модели.
У второй категории решений: TripoSR, CRM, mvedit, InstantMesh - наблюдаются сложности с созданием симметричных моделей, мелкие артефакты, например, каверны и искаженные текстуры. Под ними - грязные сетки и сглаженные болванки-обмылки.
3d.csm tripo3d - лучше создают текстуры, додумывают детали на невидимых частях объекта. Хотя tripo3d умеет в ретопологию, генерациям все еще недостает выраженного рельефа. Большая часть деталей остается на текстуре.
Пока что технология image-to-3d находится в зачаточном состоянии и напоминает результаты, которые выдавали первые версии stable diffusion. Реконструкции поддаются только сравнительно простые изображения монолитных предметов.
Да, сравнивать 3d.csm, tripo3d с демо на huggingface нечестно, так как это демонстрационные версии коммерческих сервисов, которые используют более сложные пайплайны и генерируют в несколько этапов. Однако сейчас именно они юзабельнее. Более детальные текстуры - заметное преимущество, так как их можно преобразовать в карту высот и перенести часть деталей в меш.
Вряд ли результаты их работы подойдут для нужд 3D-художников, однако уже сейчас они могут быть основой для скульптинга и годятся для распечатки на FDM-принтере. Буду продолжать эксперименты в телеграм.

Новое слово в мокапах, модель с открытым кодом переносит движения реального человека или животного из видео на модель, при этом плавность и динамика не теряются.
Multi-view Ancestral Sampling (MAS) — это техника для создания 3D-движений из 2D-данных. Эта методика использует модель диффузии для обработки нескольких 2D-последовательностей движений, снятых с разных углов, чтобы синтезировать последовательное 3D-движение.
Основное преимущество MAS заключается в возможности создавать реалистичные 3D-анимации без необходимости текстового описания исходных движений, что особенно важно в областях, где сбор 3D-данных осложнён.
MAS применяет алгоритм обратного диффузионного моделирования для синтеза чистых 2D-образцов движения, а затем согласует их в единое 3D-движение. Этот процесс включает этапы триангуляции и репроекции, обеспечивая согласованность между разными взглядами на движение, что позволяет добиться высокой точности и естественности анимации.
Для более подробной информации о проекте и его технических деталях можно посетить официальную страницу проекта MAS здесь или ознакомиться с их научной работой на arXiv.
В качестве примеров применения, разработчики MAS демонстрируют, как модель справляется с анимацией профессиональных баскетбольных маневров, элементов художественной гимнастики с мячом и соревнований по конному спорту. У технологии большой потенциал в различных областях, где традиционные методы 3D-моделирования либо слишком дороги, либо технически невозможны.
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? В своем телеграм канале НейроProfit я рассказываю, как можно использовать нейросети для бизнеса
TripoSR очень быстро создает 3D модель, стоит только загрузить картинку. Можно использовать с телефона.
Бесплатно до 10 3D-моделей в месяц
Преобразование текста в 3D и изображения в 3D
Доступ и загрузка созданных моделей
Неограниченная генерация эскизов
Скорость
Возможность пользоваться бесплатно даже на телефоне
Хорошее качество
Можно загрузить результат и доделать по своему усмотрению
Попробовать можно на HuggingFace
Код на GitHub
Так что можно бесплатно генерировать объекты для игр или фильмов и CGI в один клик.
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой телеграм канал НейроProfit, там я рассказываю, как можно использовать нейросети для бизнеса.
Специалисты из Университета Цинхуа и Университета Жэньминь Китая разработали высокоточную генеративную модель для прямого преобразования изображения в 3D-модель с использованием режима сверточной реконструкции (CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Mode). Это позволяет создавать полноценные 3D-модели с текстурами непосредственно из одного изображения, которое можно скачать в формате .obj.
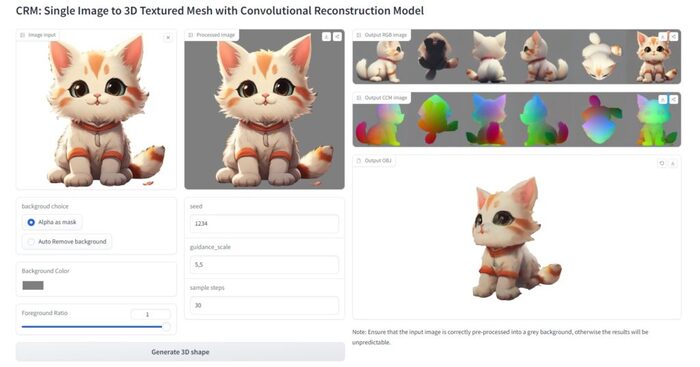
Нейросеть CRM обеспечивает более точный и эффективный метод по сравнению с существующими методами, которые включают несколько изображений или сложные вычислительные процессы. С помощью CRM пользователи могут быстро создавать реалистичные и подробные 3D-модели, начиная с одного изображения.
Попробовать нейросеть можно тут https://hubai.ru/crm-3d-convolutional-reconstruction-model/
Год назад смотрел видео в youtube “Картинку в 3D объект с помощью нейронной сети”, которая из изображения делает 3D модели. Ссылка на видео https://youtu.be/vHYxAMVFOb4?si=Q5vIlqkqz-7TAUxC Из недостатков этой нейросети было долгое ожидание генерации 3d модели (1 день) и сумма за готовую 3d модель, которая сопоставима со стоимостью заказа 3D модели на фрилансе. Под этим видео был комментарий следующего характера «Скорее это не нейронка, а просто дешёвый труд”. На тот момент я тоже подумал, что скорее всего делают люди и моделят за деньги. Со временем мое мнение поменялось. За последнее время нейронные сети стремительно развиваются. И сегодня доступно несколько нейронных сетей которые генерируют 3д модель по изображению или текстовому описанию

Большая Гауссова Модель
По своей сути Большая Гауссова Модель — это тип нейронной сети, которая может обучаться и генерировать сложные трехмерные фигуры на основе простых входных параметров. По сути, она действует как своего рода цифровой скульптор или художник, используя вероятности и статистику, чтобы заполнить пробелы между известными точками данных и создать связное, цельное целое. В одной из недавних демонстраций исследователи использовали Большую Гауссову Модель для создания детальных реконструкций целых зданий всего лишь из нескольких фотографий, сделанных под разными углами. Анализируя закономерности и особенности, общие для нескольких изображений, модель смогла заполнить недостающие детали и создать полное и точное представление экстерьера здания.
Видео по созданию с помощью программы LUMA AI
Нейросеть Pifu HD
Нейросеть PIFU - это алгоритм машинного обучения, который позволяет создавать 3D-модели человека на основе одной фотографии. Он был разработан в 2019 году командой ученых из Университета Цюриха в Швейцарии.
Процесс создания 3D модели с помощью PIFU начинается с загрузки фотографии человека в специальную программу для обработки изображений. Затем программа использует алгоритмы машинного обучения для анализа формы и пропорций лица на фотографии. На основе этих данных создается геометрическая модель, которая затем преобразуется в 3D модель.
Одной из особенностей PIFU является то, что он может создавать 3D модели людей с различными типами кожи, волос и глаз. Это позволяет создавать более реалистичные модели, которые могут быть использованы в различных областях, таких как медицина, кино и видеоигры.
Однако, следует отметить, что PIFU не является идеальным алгоритмом для создания 3D моделей людей. Он может иметь некоторые ограничения и ошибки, особенно если фотография не очень хорошего качества или если человек на фотографии имеет необычный тип лица или прическу. Кроме того, для создания 3D модели требуется достаточно высокое качество фотографии, чтобы алгоритмы могли точно проанализировать форму и пропорции лица.
Нейросеть ICON
ICON – революционная нейронная сеть, которая меняет традиционные методы создания трехмерных аватаров. В отличие от существующих методов, которые требуют либо постановочного 3D-сканирования, либо тщательно контролируемых двумерных изображений, ICON может создавать реалистичные 3D аватары из неограниченного количества реальных положений человека, используя только стандартные фотографии. ICON – Implicit Clothed humans Obtained from Normals (Неявные одетые люди, полученные от нормальных людей)
Попробовать нейросеть ICON https://hubai.ru/icon/
Создание 3D модели по текстовому запросу (описанию)
Мы рассказали Вам как нейросети могут создавать 3д модели по изображению. Но, нейросети способны не только создавать 3D модели из изображений, но и по текстовому описанию. Создание 3d моделей по текстовому описанию было лишь вопросом времени. Компания OpenAI создала генеративную нейросеть, которая способна преобразовывать текстовые промты в 3D-модели.
Нейросеть Shap E состоит из двух моделей: первая генерирует простое изображение на основе текстового запроса, а вторая — преобразовывает его в 3D-модель. Для этого она создает облака точек в пространстве, которые повторяют трёхмерную форму объекта.
Специалисты OpenAI обучили нейросеть Point-E создавать 3D-модели на массиве данных состоявшего из нескольких миллионов 3D объектов. В компании продолжат обучение алгоритмов, а также будут работать над тем, чтобы повысить качество детализации генерируемых моделей.
Нейросеть Shap-E с легкость генерирует предметы, скульптуры, архитектуру. И после повышения качества генерируемых 3д моделей в будущем это может пригодиться для 3D-печати. Или созданные нейросетью 3д модели будут появляться в виртуальных мирах,
В настоящее момент многие созданные нейросетью 3д модели из выглядят очень просто и даже примитивно, но потенциал этой нейросети весьма значителен.
Нейросеть TripoSR
TripoSR AI — уникальная платформа от компании Stability AI и Tripo AI, которая использует искусственный интеллект для создания первоклассных и удобных в использовании трехмерных моделей за считанные секунды! Благодаря современным методам синтеза и алгоритмам машинного обучения нейросеть TripoSR AI позволяет пользователям мгновенно преобразовывать тексты или визуальные изображения в сложные 3D-проекты, значительно сокращая время и ресурсы, необходимые для художественного творчества.
Попробовать нейросеть TripoSR https://hubai.ru/triposr/
Нейросеть для создания 3D модели с помощью карты глубины
Нейронная сеть, называемая генеративно-состязательной сетью (GAN), может быть обучена для преобразования двухмерных изображений в трехмерные модели. В данном случае нейросеть использует маску глубины изображения для определения глубины каждого пикселя на изображении. Затем эта информация используется для создания трехмерной модели, которая включает в себя текстуры и цвета, соответствующие исходному изображению.

Модель созданная при помощи нейрости с помощью карты глубины https://skfb.ly/oFoQz
Для обучения нейронной сети требуется большой набор данных, состоящий из пар изображений: двухмерного изображения и соответствующей ему трехмерной модели. Эти данные могут быть получены с помощью специальных 3D-сканеров или путем ручной работы.
После обучения, генеративно-состязательная сеть может быть использована для преобразования любого двухмерного изображения в трехмерную модель. Однако, следует учитывать, что результаты могут быть не очень точными, особенно если исходное изображение имеет низкое разрешение или содержит сложные детали.
Одним из основных преимуществ создания нейронных 3D-моделей является то, что оно устраняет многие ограничения, связанные с другими методами. Например, фотореалистичные 3D-модели, созданные традиционными методами, требуют обширных ресурсов, включая дорогостоящее оборудование, специализированное программное обеспечение и квалифицированных операторов. Более того, создание этих моделей вручную требует значительного времени и усилий, особенно для сложных сцен. Напротив, новый подход позволяет быстро и экономично создавать невероятно детализированные модели на основе базовых изображений. Это также облегчает создание динамических анимаций с участием виртуальных персонажей, которые убедительно двигаются и ведут себя.
Эта технология имеет множество практических применений в различных отраслях. Например, в сфере развлечений кинематографисты и игровые дизайнеры могут использовать Neural 3D Model Generation, чтобы воплощать в жизнь вымышленные миры и персонажей с большей легкостью и эффективностью, чем раньше. Между тем, преподаватели могут использовать его, чтобы предоставить учащимся интерактивную и увлекательную среду обучения, выходящую далеко за рамки простых учебников и слайд-шоу. Архитекторы и инженеры могут использовать его для виртуального тестирования проектов перед созданием физических прототипов, тем самым экономя ценные ресурсы и сводя к минимуму ошибки. Медицинские работники потенциально могут применять его для моделирования операций, помогая им в подготовке процедур и снижая риски во время реальных операций. Кроме того, розничные предприятия могут извлечь из этого выгоду, предлагая клиентам персонализированную демонстрацию продуктов удаленно через приложения дополненной реальности.
Несмотря на огромные перспективы, существует ряд проблем, которые необходимо преодолеть, прежде чем генерация нейронных 3D-моделей получит широкое распространение. Некоторые эксперты утверждают, что нынешний уровень точности все еще может не соответствовать определенным стандартам в конкретных областях. Более того, вычислительные требования для запуска алгоритмов могут существенно повлиять на производительность системы и энергопотребление, что требует мощной аппаратной настройки. Тем не менее, исследователи продолжают добиваться успехов в решении этих проблем, поэтому вполне вероятно, что в ближайшем будущем нас ждут дальнейшие улучшения.
В заключение отметим, что создание нейронных 3D-моделей — это инновационная и преобразующая технология, которая обещает изменить многие аспекты нашей жизни. По мере развития этой технологии мы ожидаем увидеть все более сложные и универсальные реализации, которые откроют множество новых приложений.





