

Как начать создавать искусственный интеллект если вы юрист/рыболов/трубочист или у вас лапки. Часть III.
Абсолютно всем добрый день, сегодня мы будем играться с модельками и че-нибудь еще. Запасайтесь чайком либо клавиатурой, и мы начинаем!
В прошлом посту мы остановились на самом интересном месте. Мы обучили модельку:

Тут есть сурьезный трабл. Если мы будем проверять на одних и тех же данных, то будет не очень хорошая проверка (ну а что если в обуч. выборке у нас одни нолики, а в тестовой - единички?). Так давайте сделаем кросс-валидацию, о которой все так твердят.
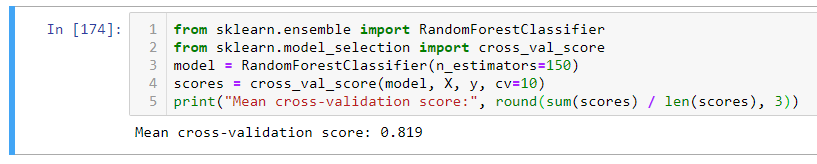
Тэк блэт что тут произошло нафиг?
Мы создали модельку в 3 строке, а в 4 самое интересное. Мы просто передаем функции нашу модельку (необученную) и данные. Я еще поставил cv=10, что означает произвести 10 проверок.
Уже более честный результат! Едем дальше. Как видите, я изменил параметр n_estimators на 150. Этот параметр отвечает за количество деревьев.
Так, ну давайте линейную регрессию? "Неа, не давайте", - скажете вы и будете правы: кто ж классификацию делает линейкой? Погнали с логистикой!

Так, на этот раз нам дали только 0.8
Теперь почему бы не зарешать методом ближайших соседей?

Нда... Ну и черт с ним!
Мы поступим по-другому. Давайте объединим мнения всех трех моделей, ведь если каждая работает с такой эффективностью - то вместе будут работать с большей!
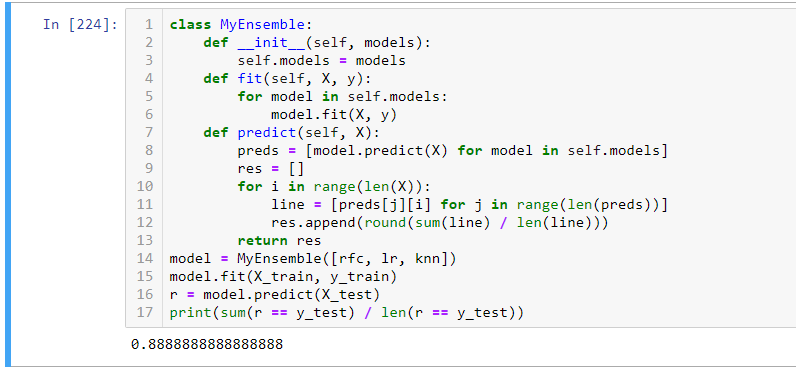
Здесь без кросс-валидола зато с ансамблем, написанным на коленке :))). Итак, что мы сделали: просто взяли обученные модельки (rfc, lr, knn - я переименовал model во всех трех случаях) и при каждом решении смотрели: если двеы или более проголосовали за 1, то ответ 1, если 1 или 0: ответ 0.
Ну что ж, попробуем залить на каггл. Для этого еще чуть-чуть попишем код.

Не очень красивый код, но я ds и мне как-то пофигу :).
Кстати на второй строке мы заменяем NaN в столбе Fare. А все почему? Потому что не заметили их при обработке! Кто ж знал...
Ладно, проехали. Самое интересное вот прям щас. Гоним на kaggle!
Ну и make submission. Смотрим, что вышло :).
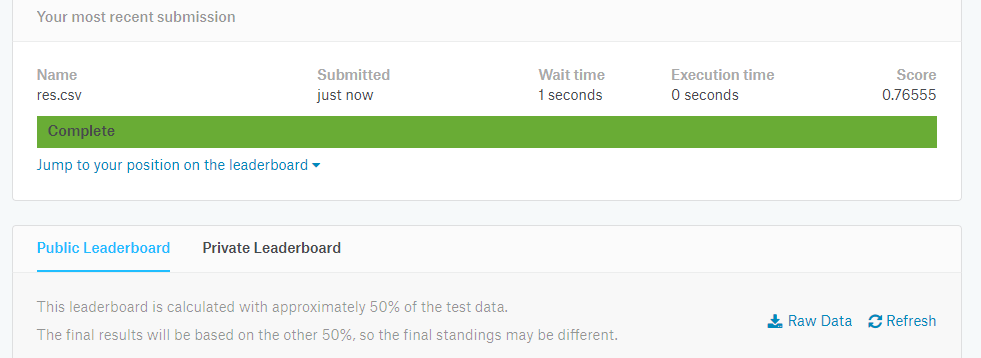
Поздравляю, если вы дошли до сюда, то вы уже получили 76% точности на финальной выборке и свое почетное 7000+- место :))). Теперь играйтесь с модельками, с их параметрами (о коих буду по-тихоньку рассказывать) и так далее. Обработайте по-другому данные. В общем, творчества тут много.
Спасибо всем за прочтение, заинтересовавшихся приглашаю в сообщягу. Ну и ссылочка на кот.
На этот раз по мнению бм в посту Гитлер...
Вопрос.
В экземпляре MyEnsemble ты передаешь rfc,lr,knn.
Но они нигде не обозначены ранее.
Естессно, питон ругается "name 'rfc' is not defined".
Откуда их взять?
Почему использованы только эти три модели?
@WhiteBlackGoose а что-нибудь на тему Keras сказать можешь? А так же пример использования TensorFlow или иную библиотеку отличную от Scikit на примере Титаника сделать можешь? Или ссылку дать, а то хочется попробовать другие библиотеки, но что-то не очень выходит.
под какую задачу оно затачивается?
На всякий случай схоронил, мало ли...