


Ответ на пост «Рецепт успеха от миллиардеров США»
Вопрос людям с позицией: ой, а дай тебе 300к, ты ж вообще нихера не сделаешь.
А смог бы Гейтс без связей мамки и подсуворенных контрактов IBM развить майкрософт? Смог бы Безос без болезненно возможности просрать 300к и получить их вновь развить свою империю? Аналогичный вопрос по остальным.
Почему вы прирпвниваете разовое дать 300к человеку, который жил в семье, у которой ни связей, ни просто лишних средств с человеком, который всегда жил при деньгах, который может все просрать, прийти к папке с мамкой и они ему помогут не то что не сдохнуть, а ещё накинуть, лишь бы дитятко не деградировало?
Историй с миллионера и из трущеб крайне мало, а даже те, что есть, оказываются нихера не из трущеб. На одном таланте хер, что по строишь, разве сто с чистой удачей.
А так, даже если дебилу дать доступ к неиссякаемому источнику инвестиций в него, главное, чтобы упертый был, он преумножит вложенные деньги. С 5,с 10 попытки, но преумножит, а ты нет, потому что у тебя будет 1 попытка. Да, не до миллиардов, возможно, но до сумм куда больших, чем есть у тебя.
Посмотрите интервью с разными около нонеймовыми миллионерами, там вообще вопрос, как они себя обслуживают, не то, что миллионы сделали

Ответ на пост «Рецепт успеха от миллиардеров США»
Ой люблю такой контент.
Типа у богатейших людей мира внезапно оказываются богатенькие родители-лоббисты при должностях и т. д. Ну понятно, что такие мемы - контрконтент на всякие мотивашки из 2000х, когда было популярно постить, что Билл Гейтс начинал с гаража, а Илон Масков бросил университет, чтобы сооучередить компанию (хз, я их биографии знаю поверхностно, но вроде так) - а чем хуже мы, ога.
Но давайте объективно: сколько сейчас мажоров учредили (хотя бы с помощью родителей) и управляют компаниями с миллиоными оборотами? Из 100%? 0,0001%? А остальные бухают, курят дурь, устраивают вечеринки в Дубаях, разбивают тачки, снимают тик токи про это ?кажется?
А какой процент из нас сможет в большой бизнес, если дать нам деньги? Особенно в реалиях России, это большой вопрос.

Вы хотите головоломок?
Их есть у нас! Красивая карта, целых три уровня и много жителей, которых надо осчастливить быстрым интернетом. Для этого придется немножко подумать, но оно того стоит: ведь тем, кто дойдет до конца, выдадим красивую награду в профиль!
Ответ на пост «Рецепт успеха от миллиардеров США»
Часто попадаются мемчики, где проводится параллель между успехом современных богачей и их родителями при бабках и связях.
Оке, оке, база у них реально охеренная для старта - это факт. Только вот у нас все мамкины богачи штоль достигают таких успехов? Прям как ринулись все в науку, да как приумножили вложенный в них капитал! Ведь да? Да ведь?


Когда сотрудники не рабы
Работа, работа, работа... каждый день, у кого-то без выходных.. почти каждый из нас работает, кто-то работает на износ, кто-то ходит на нелюбимую работу, а кто-то работает и счастлив тем, что делает. Мы все разные, но работа объединяет нас, делает нас сильнее, помогает развиваться.
Однако любое увлечение, в том числе и работой, дается непросто. Очень легко увлечься, как в мимолетном романе.. А дальше что?
Вот и моя читательница Ирина заметила:
Работа - современная форма рабства. Судя по вашей истории, рабы любят своих хозяев и не готовы на волю. Это всего лишь наёмная работа, а вы так говорите, как-будто развелись с мужем, а не работой.
На самом деле сложно принять то, что работа может быть увлекательной, такой интересной, что совсем не хочется отвлекаться, даже уходить домой на сон иногда нет времени - понять могут далеко не все.

Так бывает. Но не много тех, кому довелось работать на интересной работе. Есть и те, как я уже говорила, кому приходится работать, просто чтобы заработать на кусок хлеба.
Свою нынешнюю работу любят 53% россиян, тогда как каждый 4й (25%) вынужден отдавать себя нелюбимому делу. Женщины питают теплые чувства к работе заметно чаще мужчин (56% против 49%), а респонденты старше 45 лет — чаще опрошенных моложе 34 лет (58% против 48%).

Вот прямо как одного из пользователей сети, крик души которого я прочла недавно.
Молча уходить по-английски в первый же день -- это уже своего рода классика действий при поиске работы. Я сам лично так делал уже три раза, и всегда один и тот же сценарий: ты на собеседовании выясняешь обязанности, график, условия. Соглашаешься.
Приходишь на первый рабочий день, и тут выясняется, что, условно, обещанных перерывов нет, обязанности другие, да и не чувствуется в атмосфере той раскрепощённости и уюта, что было озвучено.
Всё. Молча встал посреди рабочего дня, собрал вещи, вышел за дверь. Домой пришёл, сел дальше искать работу.
Искренне жаль, что многие не могут так поступать ввиду банального отсутствия финансовой подушки, и соглашаются на любую работу ради выживания.
А ведь поступал бы так каждый - работодатели стали бы более вменяемы, и нанимали сотрудников, а не рабов.

А вы как считаете?
Показать полностью
3

Как не продалбывать задачи на день

Раз уж в предыдущем посте заговорил про список задач и про то, что туда надо добавлять, дам еще один полезный совет. Рано или поздно я опубликую пост о том, насколько полезно (де чего уж скромничать, это жизненно необходимый навык) вести список задач, и как продуктивнее всего это делать, но пока буду исходить из того, что он у вас уже есть.
Абсолютно каждый человек, который хоть когда-либо вёл такой список, знает, насколько сложно запланировать оптимальное количество дел на день. Запланируешь мало – сработает закон Паркинсона (об этом будет следующий пост, не пропустите) и больше за день ничего не сделаешь полезного. Запланируешь много – что-то не успеешь, появится чувство неудовлетворенности и будешь винить себя за это. Есть куча разных советов, как же всё-таки правильно выбирать количество задач на день. Я использую только один способ – делю все задачи на несколько категорий:
Первая категория самая важная – задачи, которые нужно ОБЯЗАТЕЛЬНО сделать сегодня. Если вы их не сделаете – значит произойдёт что-то плохое. Если сделаете только их – день прошёл не зря.
Вторая категория – задачи, которые ЖЕЛАТЕЛЬНО сделать сегодня, но не обязательно. То есть если вы сделали все задачи из первой категории, то можете переходить ко второй. Но если задачи из второй категории сегодня сделать не успеете, то ничего страшного не произойдет. Обычно это задачи, которые нужно сделать до конца недели, но ставить жесткий срок (вторник или четверг) не хочется. Рано или поздно задачи из второй категории сами попадут в первую.
На самом деле этих 2 категорий на начальном этапе и в большинстве случаев будет достаточно. Дальше уже каждый сам «докручивает систему» под себя. Выделю ещё одну категорию:
Третья категория – задачи, которые желательно сделать на этой неделе, но не обязательно. То есть это задачи, которые попадут во вторую и первую категорию не ранее следующей недели. На них можно иногда посматривать среди недели. И обязательно в начале каждой недели, чтобы не пропустить момент, когда они должны перейти во вторую или первую категорию.
Важно! Надо не расставлять приоритеты у каждой задачи, а именно делить все задачи на несколько категорий.
Пишу небольшие, но полезные посты о саморазвитии, подписывайся. Если понравилось, можешь подписаться и на Тележеньку, но я не настаиваю, она только создана и там только годнота и никакой рекламы.
Показать полностью

Одно и то же число, но разные результаты: как работает random_state в ML?

Что такое random_state в машинном обучении? Зачем нужен этот парметр и как его выбрать? А что вообще общего у числа 42 с культовой книгой “Автостопом по галактике”? И разве случайности не случайны?..
Что такое random_state и как его настройка влияет на обучение моделей?
Возможно, многие из вас уже слышали о параметре random_state, особенно если вы сейчас погружаетесь в ML-разработку. Или вы уже пробовали работать с этим параметром, разбивая набор данных на обучающую и тестовую выборки.
Если же забыли или сейчас столкнулись с randome_state впервые, рассказываем, что это такое.
Параметр `random_state` в ML-разработке обычно используется для установки начального состояния генератора случайных чисел. Этот параметр часто встречается в алгоритмах машинного обучения, которые включают случайные элементы. Например, инициализация весов модели, разделение данных на обучающий и тестовый наборы, случайная инициализация параметров и т. д.
Представьте, что вы выполняете задание, в котором нужно использовать случайные числа. Например, вы разделяете данные на обучающую и тестовую выборки, и вам нужно случайным образом выбрать часть данных для обучения и часть для тестирования модели.
`random_state` — это как начальное число, которое указывает компьютеру, как начать генерацию случайных чисел. Если вы каждый раз используете одно и то же значение `random_state`, то каждый раз, когда вы запускаете эксперимент, вы будете получать те же самые случайные числа. Это помогает сделать ваше исследование воспроизводимым. То есть каждый раз, когда вы запускаете эксперимент с одним и тем же `random_state`, вы получаете те же самые результаты.
Почему это важно?
Предположим, что у вас есть модель, которая дает вам хорошие результаты на определенном наборе данных. Вы хотите сравнить ее с другой моделью или настройками. Если вы используете один и тот же `random_state`, то обе модели будут тестироваться на тех же самых данных, что позволит вам честно сравнивать их результаты.
random_state = 0 or 42 or none
Чаще всего люди устанавливают значение random_state на 0 или 42. Но вы знаете, почему это так?
Простота запоминания
Числа 0 и 42 довольно легко запомнить, поэтому они часто используются как стандартные значения для `random_state`.
Распространенность
Эти числа стали популярными благодаря их частому использованию в примерах и обучающих материалах. Честно говоря, многие останавливаются на этих значениях, даже если они не понимают их смысла.
Теперь давайте рассмотрим каждое число отдельно:
- 0 — часто используемое значение, потому что оно приводит к одинаковым результатам при каждом запуске программы, что удобно для проверки и воспроизводимости экспериментов.
- 42 — это число стало популярным после того, как стало известно, что автор Дуглас Адамс использовал его в своей книге "Автостопом по галактике" как ответ на вопрос о смысле жизни, вселенной и всего такого. В итоге эта сцена стала культовой, поэтому теперь это число часто используется в качестве самого простого способа установить `random_state`.
Таким образом, когда люди говорят о том, что чаще всего используют числа 0 или 42 для `random_state`, они обычно имеют в виду, что это стандартные значения, которые многие выбирают из привычки, не всегда понимая, почему именно эти числа используются.
Что такое random_state?
В библиотеке Scikit-learn этот параметр управляет перетасовкой данных перед их разделением. Мы используем его в функции train_test_split для разделения данных на обучающую и тестовую выборки.
Он может принимать следующие значения:
1. Нет (по умолчанию). Если не указано значение, то используется глобальный экземпляр случайного состояния из библиотеки numpy.random. Если мы вызываем функцию с random_state=None, то каждый раз получаем разные результаты.
2. Целое число. Установка любого значения из целого числа для random_state дает один и тот же результат при каждом выполнении программы. Изменение значения random_state приведет к изменению результата.
Важно помнить, что random_state не может быть отрицательным числом!
Как это работает?
Допустим, у нас есть набор из 10 чисел, от 1 до 10. Теперь, когда мы хотим его разделить на обучающую и тестовую выборки, мы решаем, что размер тестовой выборки должен составить 20% от всего набора данных.
Получается, что в обучающем наборе будет 8 чисел, а в тестовом — 2. Это важно для того, чтобы каждый раз получать одинаковые результаты при запуске кода. Если мы не перетасуем данные, то каждый раз будем получать разные выборки. А это может некачественно сказаться на обучении модели.
Немного подробнее: когда мы устанавливаем значение `random_state` для наших случайных процессов, мы фактически фиксируем начальное состояние генератора случайных чисел. Это гарантирует, что каждый раз, когда мы запускаем наш код с тем же значением `random_state`, то получаем одинаковый набор случайных чисел. И в нашем случае, когда мы используем этот `random_state` для разделения данных на обучающий и тестовый наборы, мы получаем одинаковое разделение каждый раз, когда запускаем код.
На картинке ниже показано, как это работает:

Давайте разберемся в одном важном моменте. Многие люди используют значение random_state = 42. На изображении выше видно, что при установке random_state равным 42, мы получаем один и тот же фиксированный набор данных, который был перетасован. Это означает, что каждый раз, когда мы устанавливаем random_state равным 42, мы получаем один и тот же перетасованный набор данных.
Таким образом, число 42 не обладает особым значением для random_state.
Давайте посмотрим, как это можно использовать для разделения набора данных
Здесь мы используем набор данных о качестве вина и модель линейной регрессии. Делаем просто, потому что наша основная цель — это random_state, а не точность.
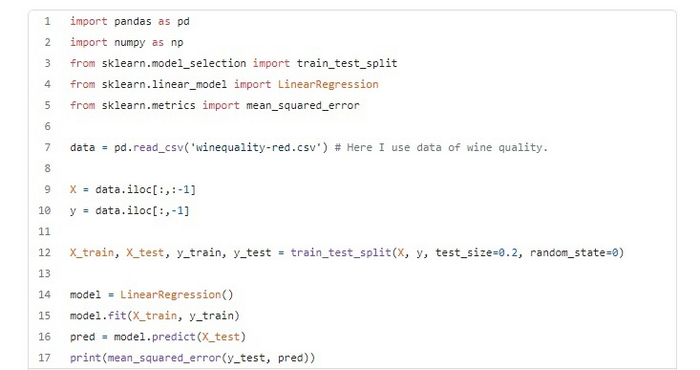
Использование random_state при разделении
В представленном выше коде для random_state равного 0, mean_squared_error составила 0.384471197820124. Если мы попробуем разные значения для random_state, то каждый раз получим разные ошибки.
Для random_state = 1, mean_squared_error равна 0.38307198158142.
Для random_state = 69, mean_squared_error равна 0.47013897077423.
Для random_state = 143, mean_squared_error равна 0.42062134425032.
Сколько вообще возможных случайных состояний бывает?
Проведем эксперимент, чтобы определить, сколько различных комбинаций данных мы можем получить, переставляя исходный набор.
1. Мы берем набор из 5 чисел от 1 до 5.
2. Далее разделяем этот набор данных на обучающие и тестовые данные 2000 раз, используя значения random_state от 1 до 2000. Каждое значение random_state создает новую случайную последовательность разделения данных.
В итоге у нас будет список из 2000 перетасованных наборов данных, каждый полученный с использованием разного значения random_state.
Из всех этих перетасованных наборов данных только 120 окажутся уникальными. Это означает, что при использовании исходного набора данных из 5 чисел мы можем получить всего 120 различных комбинаций, переставляя их.
Установка значения random_state в диапазоне от 0 до 119 позволит нам получить одну из этих 120 уникальных комбинаций данных при каждом запуске алгоритма.
Эти выводы можно объяснить так:

Короче говоря, это про факториалы. При использовании набора данных из 5 чисел и их перестановкой, мы фактически создаем комбинации, а количество уникальных комбинаций, как можно заметить, равно факториалу числа 5, то есть 5! = 5 × 4 × 3 × 2 × 1 = 120.
Использование параметра `random_state` в этом контексте подобно выбору одной из 120 уникальных комбинаций данных. Каждое значение `random_state` соответствует одной из перестановок чисел, и они будут однозначно связаны с числами от 0 до 119, что совпадает с индексами возможных комбинаций факториала числа 5.
Этот эксперимент помогает нам понять, как параметр `random_state` влияет на разделение данных и на результаты моделирования в машинном обучении, потому что он определяет начальное состояние генератора псевдослучайных чисел. При разделении данных на обучающий и тестовый наборы с использованием `random_state` мы фиксируем последовательность случайных чисел, которая влияет на способ разделения данных.
Этот параметр важен, потому что он обеспечивает воспроизводимость результатов: при одном и том же значении `random_state` мы получаем одинаковую разбивку данных, что позволяет повторно воспроизвести эксперимент и проверить результаты моделирования. И именно таким образом, понимание того, как работает `random_state`, помогает нам контролировать случайность в нашем анализе данных и сделать его более надежным и воспроизводимым.
Зачем нам это нужно?
Давайте разберемся с random_state в контексте прогнозирования цен на жилье. Представьте, у нас есть данные о жилье, и по мере движения сверху вниз по этим данным, у нас становится либо больше комнат, либо увеличивается площадь квартир. Это то, что мы называем данными о смещении.
Теперь, если мы просто разделим наши данные без перетасовки, это даст нам неплохую производительность при обучении, но когда дело доходит до тестирования, она может быть не очень. Поэтому мы и используем перетасовку данных. Вот где random_state приходит на помощь!
Когда мы делим данные, то хотим, чтобы результаты каждый раз были одинаковыми. То есть, если мы перезапустим код, мы получим те же самые данные для обучения и тестирования, что и раньше.
Разные значения random_state могут дать нам разную производительность.
Например, разные значения random_state дают разные значения mean_squared_error.
Это означает, что если вы выберете случайное значение random_state, и вам повезет, то вы сможете свести к минимуму количество ошибок для этого значения.
Да и в других аспектах машинного обучения random_state пригодится. Например:
KMeans
В алгоритме KMeans параметр random_state определяет, как генерируются случайные числа для инициализации центроидов. Мы можем использовать целое число для того, чтобы сделать процесс генерации случайных чисел предсказуемым. Это полезно, когда нам нужно создавать одинаковые кластеры каждый раз.
Случайный лес
В классификаторе случайного леса и в модели регрессии параметр random_state контролирует начальное случайное состояние выборок, используемых при построении деревьев, и выборку объектов, учитываемых при поиске наилучшего разделения в каждом узле.
Дерево решений
В классификаторе дерева решений или регрессии, когда мы ищем наилучшие признаки для разделения узлов, тоже стоит задать параметр random_state. Этот определяет структуру дерева и гарантирует воспроизводимость результатов.
Ну, вот и всё, что вам нужно знать о random_state!
Показать полностью
4


Вы - ваш лучший стартап: относиться к себе, как к бизнесу
Вводное
"Mind your own business." - “Не лезь ни в свое дело”/ “Занимайся своими делами”.
Эта фраза широко используется в английском языке, чтобы сказать кому-то не вмешиваться в чьи-то личные дела или проблемы. Идея этой статьи пришла ко мне во время создания дашборда для самоанализа моей личной жизни, абсолютно всех ее сфер без исключений. Когда я задумалась, как же эффективно и правильно организовать эту доску для работы над собой то начала проводить аналогии с бизнесом и вспоминать методики: SMART (определение конкретных, измеримых, достижимых, релевантных и временно ограниченных целей), OKR (объективы и ключевые результаты для установления и измерения целей), SWOT-анализ (анализ сильных и слабых сторон, возможностей и угроз), матрицу Эйзенхауэра (для приоритизации задач по срочности и важности) — это инструменты для построение стратегии, анализа и планирования бизнеса. В этот момент у меня случилась, что называется “ЭВРИКА!”.

"Человек, измеряющий облака" - скульптура современного бельгийского художника Яна Фабра.
Смена парадигмы
И в тот же момент посыпалась масса вопросов к самой себе.
А почему, черт возьми, я не использую это в личных целях? Почему я не отношусь к самой себе как к бизнесу? Как к делу всей своей жизни? И почему же я, в конце концов, не отношусь к себе как к системе, которую нужно СИСТЕМНО анализировать, настраивать, искать новые подходы по всем областям жизни, а не отдельно взятых?
Я точно знаю, что не первый человек, поймавший эту мысль, но также я и не претендую на первооткрывателя. В этом плане она [мысль] совершенна не уникальна, но вопрос в том, как много людей относятся к себе именно так? Как много людей об этом задумывалось? Каким было бы наше общество и качество жизни, будь подобное отношение к себе нормой? Я буду несказанно рада, если хотя бы один человек, прочитавший эту статью (или хотя бы этот момент, окэй?), словит такой же Вау-эффект. Напишите в комментарии, если у меня получилось.
Этимология
Уже после того, как я разработала свой личный дашборд на базе бизнес-методик, в очередное воскресенье просматривая доску, обновляя мысли - в общем-то работая над собой - я задумалась о происхождении слова “бизнес”. Ведь в английском языке это значит не только “Бизнес” в прямом его смысле слова. Оказалось, что этимология слова "business" восходит к древнеанглийскому слову "bisignis", которое обозначало "заботу, тревогу, занятость". Это слово произошло от "bisig", что означает "занятой, озабоченный".
Во-первых, это напрямую отражает суть бизнеса - быть озабоченным чем-то, быть встревоженным той или иной проблемой (которую пытается решить твой бизнес), быть занятым этим делом, чтобы что-либо изменить в мире и закрыть в первую очередь СВОЮ ЖЕ тревогу/гештальт (тут может быть много смыслов и они все верны). Но это тема для другой статьи.
Во-вторых, это в конце концов означает, что наша жизнь является главным бизнесом и требует соответствующего отношения к ней (даже более подробного и системного, чем к “реальному” бизнесу в привычном смысле слова, хотя я бы еще поспорила, что здесь более реально). И тут я вновь повторю вопрос: Почему мы не относимся к самим себе как к бизнесу, как к делу всей своей жизни?
Жизнь человека: единственный и главный бизнес.
Мне больше нравится перевод “бизнеса” как “дело”. И если рассматривать жизнь, как бизнес (дело), то у нас в ней есть много отделов, департаментов, если хотите. Каждый отдел можно рассматривать как мини-бизнес, подчиняющийся одному большому совету директоров, состоящему из вас (а также ваших тараканов, если не будет их лечить))).
Вот у вас есть отдел здоровья, вот у вас есть отдел личного роста, вот отдел финансов и денег, вот отдел семьи и личной жизни, вот отдел творчества и духовности, вот отдел карьеры и бизнеса, вот отдел, отвечающий за насыщенность жизни.
И вы не можете управлять отделом здоровья так же, как отделом финансов. Нужны разные системы и тактики для каждого отдела. Нельзя принять таблетку и от головной боли, и от бедности. Принципиально разные области жизни! При этом также нельзя забить болт на один из отделов вашего Бизнеса (Жизни) - непременно будут неполадки в других отделах, кто-то будет вынужден принимать на себя удар.
А теперь представьте, что происходит, если в вашем Бизнесе вообще работает только 1 или 2 департамента из 8? Далеко уедите? А представьте себе бизнес в котором вообще нет регулярного анализа, постановки целей, системы, внимания, стратегии развития. Много такой бизнес принесет?
В каждом отделе: вы начальник, т.е. только вы отвечаете за результат. Исполнителем чаще всего тоже являетесь вы сами, но, кстати, тут уже можно делегировать. Например, в отделе здоровья можно иметь косметолога, тренера, диетолога и т.д. Если есть финансовая возможность, то это отлично снизит нагрузку и позволит уделять больше внимания другим вещам. Если необходимость есть, а возможности нет, значит ваш финансовый отдел косячит, и разбираться надо в первую очередь с ним.
Но для того, чтобы все что угодно появилось в вашей жизни — НАЧАЛЬНИК, а то есть вы сами, должны поставить цель для отдела, а затем найти способы добиться этой цели. Иначе ваше бизнес умрет так и не начавшись. И потому целеполагание является одной из первых и важнейших вещей.
Заключение
Я соглашусь с вами, если вы скажете, что все эти слова не открытия, словно бы я описала очевидное. Да, очевидное, но как часто мы об этом думаем? Как часто мы ОСОЗНАННО относимся к себе как к бизнесу и серьезно управляем нашими отделами и задаем цели и инструменты в каждой области жизни? И даже больше - как много людей это делает?
"Относись к ближнему, как к самому себе, а к себе — как к бизнесу.".
И вот вам еще цитатка по теме из моей головы для статуса в ВК “Жизнь — это главный бизнес, работающий в первую очередь на ваше личное благо. Если вы успешно управляете им, то совершенно точно способны создать новый физический бизнес (читайте новую жизнь!), который будет хорошо работать на все общество, и в ответ благодарить вас деньгами”.
P.S. дайте знать, если хотели бы увидеть мой дашборд для работы над собой и, вероятно, тоже использовать его в своих целях. Также буду благодарна, за любые репосты, лайки и комментарии, если эта статья была вам полезна.
Подписывайтесь на мой телеграм канал про попытку фиксировать путь, а также поиск единомышленников, комьюинити по интересам и потребность приносить пользу окружающим.
Показать полностью
1