Перезалив.ИНФОРМАЦИЯ не для домашнего применения! Все ссылки на изученные мной источники, для составления поста в конце поста.
Всем привет. Сегодня я хочу рассказать вам об основных антидотах, применяемых в практике врача. Думаю, многие из вас вспоминая разные фильмы сразу рисуют в голове ситуацию с укусом змеи или подсыпанием яда в чай, после чего герою нужно срочно найти антидот. Да, такие вещества действительно существуют, но правильнее их называть (если речь идет об укусе змеи): противозмеиные сыворотки. Но речь сегодня пойдет о таких веществах, которые на первый взгляд точно не выглядят как антидот. Например, этиловый спирт, витамин К или даже обычный кислород. Подробней о некоторых из них поговорим ниже.
1/3
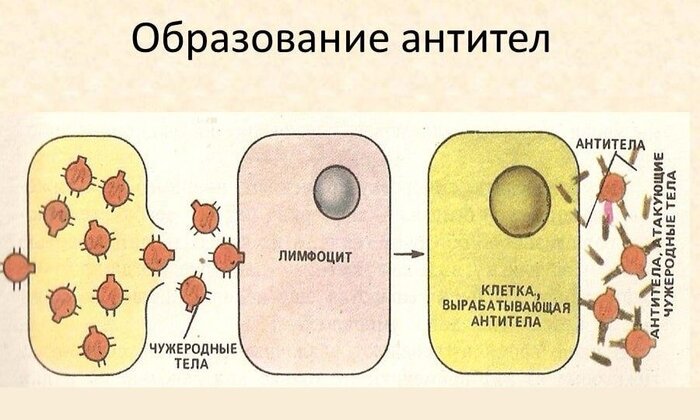
Суть метода такова: У ядовитой змеи извлекают особые железы, которые и производят яд, выделяемый при укусе;Полученный яд вводят в кровь свиньи или лошади в небольших, не смертельных дозах;Организм животного вырабатывает антитела. Которые затем и используют
В практике врачей, особенно в практике врачей скорой помощи не редки случаи, при которых у пациента происходят различные отравления. Базовым методом помощи, когда неизвестна причина отравления является промывание желудка, чтобы прекратить контакт с отравляющим веществом или же применяют форсированный диурез (это когда путем введения мочегонных препаратов увеличивают выведение мочи из организма и как следствие выведение опасных веществ) и другие методы, но, когда причина отравления или состояния известны, принимают специфические антидоты.
Чаще всего мы имеем дело со следующими категориями пациентов:
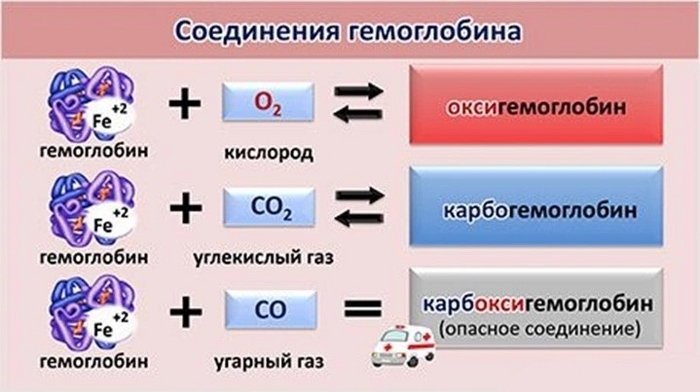
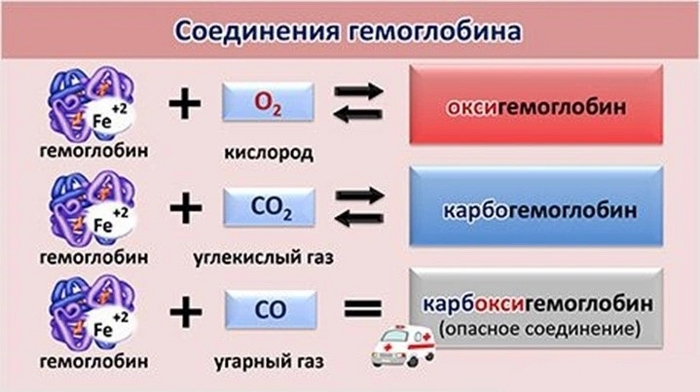
1) Это люди, пострадавшие при пожаре. При нахождении в горящем помещении происходит вдыхание угарного газа, который образует очень прочную связь с молекулой гемоглобина образуя карбоксигемоглобин из-за чего обычный кислород находящийся в нашем воздухе (напомню: его процентное соотношение от всего воздуха около 21%). Не в состоянии разрушить эту плотную связь и в таком случае применяют гипербарическую оксигенацию практически 100% кислородом (т.е. кислород 100%-й под высоким давлением). Что делает 100% кислород антидотом при отравлении угарным газом.
2) Вторая группа: отравление алкоголем. Но речь именно про те случаи, когда пострадавшим был куплен контрафактный (поддельный) алкоголь, где недобросовестный производитель в надежде заработать деньги использует вместо этилового спирта, метиловый спирт (технический спирт) который является сильнейшим ядом, который даже может привести к слепоте. Его антидотом является как раз-таки этиловый спирт 0.6 г/кг веса разведенный в 5% растворе глюкозы применяемый внутрь.
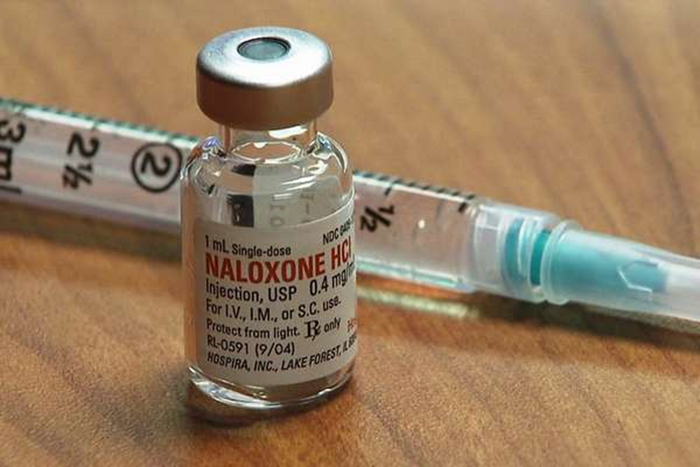
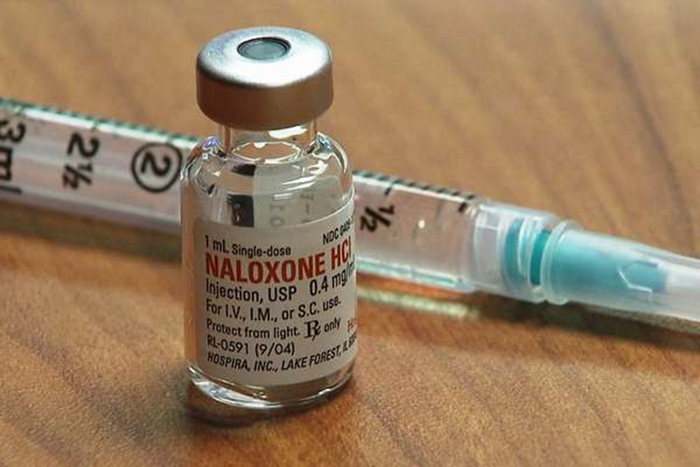
3) Еще одной группой пациентов являются потребители опиатных наркотиков, при передозировки данными веществами антидотом является препарат налоксон он является антагонистом опиатных рецепторов, т.е. он блокирует все те рецепторы организма куда должны присоединяться опиатные наркотики и вызывать свое действие. Он занимает их место и тем самым спасает пациента.
Налоксон
4) И наконец это могут быть дети и люди пожилого возраста, которые ошибочно могу принять не то лекарство, не в той дозировке из-за плохого зрения, памяти и прочих причин. Дети же, оставшись без присмотра взрослых могут найти красивую цветную коробочку, поэтому важно хранить все лекарства и бытовую химию в недоступном от детей месте.
В зависимости от отравления конкретным веществом существует свой антидот для этого я подготовил таблицу представленную ниже где собраны основные антидоты при различных состояниях. Данная таблица будет полезна главным образом врачам, особенно врачам скорой помощи, студентам медикам как лишнее напоминание о существования оных.
Тем, кому понадобится таблица в максимальном качестве, приглашаю в свои телеграммы канал https://t.me/ProMEDoN , также вы там найдете множество другого полезного контента по медицине. Спасибо за внимание!
СПИСОК ИСТОЧНИКОВ И ЛИТЕРАТУРЫ (изученных для составления поста):
ИНФОРМАЦИЯ не для домашнего применения! Все ссылки на изученные мной источники, для составления поста в конце поста.
Всем привет. Сегодня я хочу рассказать вам об основных антидотах, применяемых в практике врача. Думаю, многие из вас вспоминая разные фильмы сразу рисуют в голове ситуацию с укусом змеи или подсыпанием яда в чай, после чего герою нужно срочно найти антидот. Да, такие вещества действительно существуют, но правильнее их называть (если речь идет об укусе змеи): противозмеиные сыворотки. Но речь сегодня пойдет о таких веществах, которые на первый взгляд точно не выглядят как антидот. Например, этиловый спирт, витамин К или даже обычный кислород. Подробней о некоторых из них поговорим ниже.
1/3
Суть метода такова: У ядовитой змеи извлекают особые железы, которые и производят яд, выделяемый при укусе;Полученный яд вводят в кровь свиньи или лошади в небольших, не смертельных дозах;Организм животного вырабатывает антитела. Которые затем и используют
В практике врачей, особенно в практике врачей скорой помощи не редки случаи, при которых у пациента происходят различные отравления. Базовым методом помощи, когда неизвестна причина отравления является промывание желудка, чтобы прекратить контакт с отравляющим веществом или же применяют форсированный диурез (это когда путем введения мочегонных препаратов увеличивают выведение мочи из организма и как следствие выведение опасных веществ) и другие методы, но, когда причина отравления или состояния известны, принимают специфические антидоты.
Чаще всего мы имеем дело со следующими категориями пациентов:
1) Это люди, пострадавшие при пожаре. При нахождении в горящем помещении происходит вдыхание угарного газа, который образует очень прочную связь с молекулой гемоглобина образуя карбоксигемоглобин из-за чего обычный кислород находящийся в нашем воздухе (напомню: его процентное соотношение от всего воздуха около 21%). Не в состоянии разрушить эту плотную связь и в таком случае применяют гипербарическую оксигенацию практически 100% кислородом (т.е. кислород 100%-й под высоким давлением). Что делает 100% кислород антидотом при отравлении угарным газом.
2) Вторая группа: отравление алкоголем. Но речь именно про те случаи, когда пострадавшим был куплен контрафактный (поддельный) алкоголь, где недобросовестный производитель в надежде заработать деньги использует вместо этилового спирта, метиловый спирт (технический спирт) который является сильнейшим ядом, который даже может привести к слепоте. Его антидотом является как раз-таки этиловый спирт 0.6 г/кг веса разведенный в 5% растворе глюкозы применяемый внутрь.
3) Еще одной группой пациентов являются потребители опиатных наркотиков, при передозировки данными веществами антидотом является препарат налоксон он является антагонистом опиатных рецепторов, т.е. он блокирует все те рецепторы организма куда должны присоединяться опиатные наркотики и вызывать свое действие. Он занимает их место и тем самым спасает пациента.
Налоксон
4) И наконец это могут быть дети и люди пожилого возраста, которые ошибочно могу принять не то лекарство, не в той дозировке из-за плохого зрения, памяти и прочих причин. Дети же, оставшись без присмотра взрослых могут найти красивую цветную коробочку, поэтому важно хранить все лекарства и бытовую химию в недоступном от детей месте.
В зависимости от отравления конкретным веществом существует свой антидот для этого я подготовил таблицу представленную ниже где собраны основные антидоты при различных состояниях. Данная таблица будет полезна главным образом врачам, особенно врачам скорой помощи, студентам медикам как лишнее напоминание о существования оных.
Тем, кому понадобится таблица в максимальном качестве, приглашаю в свои телеграммы канал https://t.me/ProMEDoN , также вы там найдете множество другого полезного контента по медицине. Спасибо за внимание!
СПИСОК ИСТОЧНИКОВ И ЛИТЕРАТУРЫ (изученных для составления поста):
Попалась статья с названием "Какой контент поощряют алгоритмы социальных сетей". Вот таким названием и надо искать, автор пишет, что яндекс его удаляет из поиска. И да, так и есть, по автору я тут же его потеряла.
В тексте несколько рыхлом, все ресурсы перешли на рекомендации искусственного интелекта, это: очень частые, очень короткие, шокирующие публикации. Автор пишет что ориентированные на большие лайки, но вот это не правда. В лучшем и горячем тут на пикабу какой-то отстой с ерундовыми лайками, ну в основном.
Раньше горячее я читала до издевательской подписи от Пикабу Хорошая работа. Теперь это очень странные подборки.
Вообще Пикабу я для себя нашла совсем недавно и сначала мне было безумно интересно, и то что я писала, вроде бвло интересно кому-то, спасибо, я извинюсь, очень боюсь читать камментарии после некоторых случаев, ну просто не могу себя заставить.
Для меня Пикабу способ высказаться, поделиться с надеждой, вдруг кому пригодиться или улыбнет, и да, я зануда, люблю длинно и писать и читать.
А я все изумляюсь, куда все люди делись из вконтакта, у меня нет лайков, нет просмотров, все уменьшилось в разы за последний год. Ну очевидно, я поглупела, тут нет сомнений. Но не настолько же. А оно вот как, алгоритмы ленты и рекомендаций заточены на шоковый и короткий и очень частый контент, извините за слово. Я и в своей ленте вижу совершенно не то что мне нравится, и это очень странно.
Продолжаю думать о том что в статье написано, нашла ее на конте, и тут же потеряла, она мгновенно исчезла из поиска, нашла обходными способами. И конспирология в голову лезет такая страшная, что не осознать. А нет ли в этом всем диверсии? Ведь нет никакого искусственного интеллекта, это просто программы, их пишут люди, и они вообще-то простенькие, похожи на работу с базами данных. Все они построены на принципе запрос, ответ, и вот эти запросы или вопросы они определяют алгоритм работы, их пишут люди, их прописывают в тех заданиях, но иногда и нет, а кто их пишет и главное зачем? И никто же код не читает. А кто их пишет такими вредоносными? Ведь людям не интересно, денег такое не приносит. Зачем так все бессмысленно? А не нужно ли нас спасать уже всеми руками? Мы тонем!
я думаю вы думаете мы думаем ии не умеет думать, это вранье
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
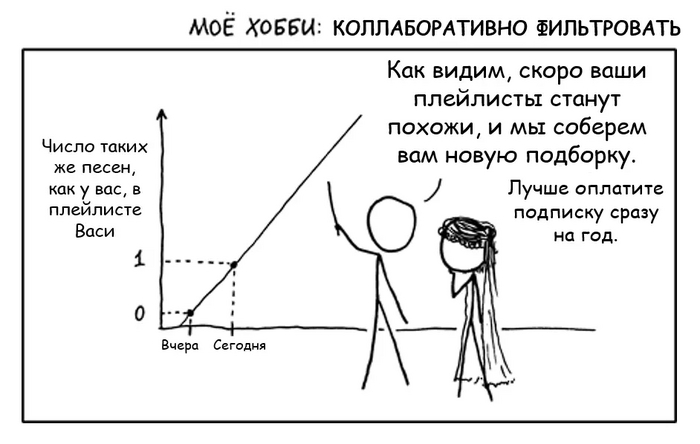
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Я решил сменить профессию и стать программистом. 🤡 Составил примерный план.
Выбрал направление бэкенд, язык java. Хочу пойти в Яндекс стажёром. Посмотрел, что нужно выучить. Нашёл в интернете материал по джаве. Сейчас ищу материал про алгоритмы и кое что не понял. Для алгоритмов нужна математика или нет? Я совсем в ней не шарю, мой максимум это 4 + x = 6 x=6-4=2. Мне нужно в свой план обучения вставлять математику или без неё можно обойтись?
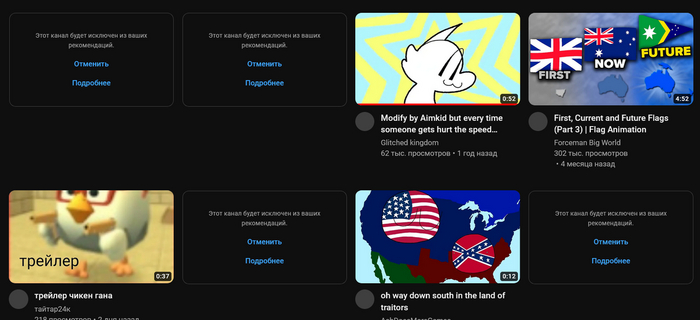
Не знаю, как вы, а я в какой-то момент взвыла от этих голов из унитаза, прущих в каждой рекомендации Youtube. Я нормальный человек, у меня нормальные вкусы и предпочтения, и вот я обнаруживаю, что привычные каналы мне приходится вытаскивать через поиск, потому что Ютуб вместо обычных приличных видео насовал мне полный лист нипоймичего.
(Во предложение, да, почти четыре строчки, это все гнев человеческий))))
Оказывается весь секрет в едином IP-адресе для роутера, которому все равно, мама смотрит видосики, папа, ребенок или пудель. Плюс загадочные алгоритмы самого ютуба, который настойчиво пропихивает этого #скибиди-тойлета по всем углам. Плюс юные видеоблогеры, радостно побежавшие строчить собственный креатив по мотивам. И снова восторженный ютуб, рекомендующий в листе новинок "набирающий популярность тренд.
Омг. А у меня нормальный ребенок, в школу ходит, смотрит человеческие мультики, музыку пишет САМ вот такую https://band.link/3qcFx 😄 И ему все эти скибиди, ну скажем честно, совершенно не нужны.
И уж тем более мне.
Про пуделя и вовсе молчу.
Я сперва вежливо отмечала в листе выдачи, что такое видео нас "не интересует". Не помогло, скибиди все равно лезли не из одного канала, так из другого. В конце концов я рассердилась и стала просто блокировать каналы. Примерно так:
Заодно бессовестно пролезла в ребенкин профиль, поудаляла там всякий треш из подписок и насовала с десяток человеческих каналов. Теперь буду недельку наблюдать, как оно все сработает.
Пишу справедливости ради, обидно за хорошую бригаду.
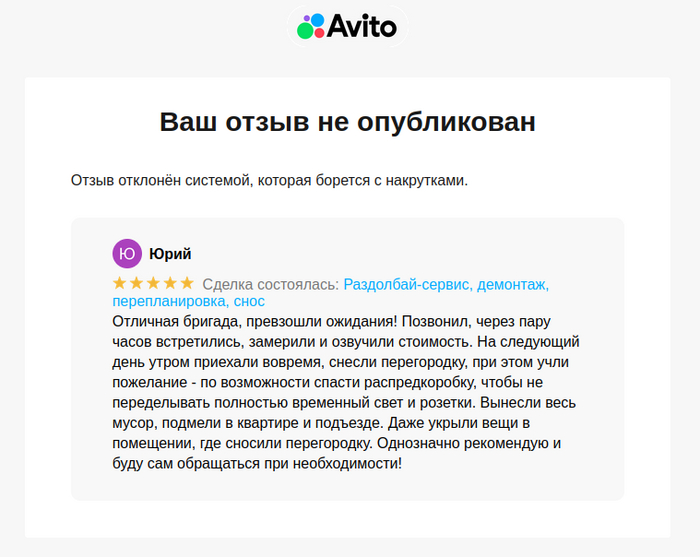
Позавчера нашел на авито "Раздолбай-сервис" - нужно было снести в новой квартире перегородку.
По опыту - грамотных работников всегда найти трудно, поэтому был очень приятно удивлён, когда быстро договорились на встречу, быстро просчитали, приехали вовремя, все сделали не просто быстро, но и аккуратно и чисто. Даже подъезд подмели.
Накрыли вещи и скрутили проводку (чего я даже не просил) - хотя просил просто не перебивать по возможности провода к коробке (чтобы не переделывать временный свет):
Решил написать хороший отзыв бригаде на Авито - фотку приложил. Но отзыв отклоняет "автоматика":
Подал аппеляцию, но результат - тот же:
@Avito.help, я уже писал в аппеляции - а теперь продублирую публично. Ваши ИТшники, занимающиеся этой "автоматикой" - зря получают ЗП. Ваша система защиты от накруток не работает - вы режете реальные отзывы реально хорошим рабтникам.
Не удивлюсь, если всякий скам наоборот проходит без проблем.
Алгоритмы спотифай: ты часто ешь шоколад, может тебе понравится шоколадное мороженое. Алгоритмы яндекс-музыки: ты часто ешь шоколад, наверное тебе нравится всё коричневое, значит тебе должно понравиться 💩