


Как читают генетический код?

Книги мы читаем с начала. Открываем первую страницу и вперёд. Здесь ясно, какая буква первая, с какого слова начинается глава, абзац или предложение.
А теперь вспомним, как выглядит текст генетического кода: ААТГЦАГЦТТТАГЦТГАТЦЦТАА... И вспомним, что в каждом генетическом слове ровно три буквы: ТТТ, или АГЦ, или ГГГ, например.

Казалось бы, бери, да читай также с первой буквы. А нельзя! Почему?
Когда аппарат для чтения геномов - секвенатор - читает положенный в него образец ДНК, он сначала режет молекулу ДНК на маленькие фрагменты в 100-200 букв (размер фрагмента зависит от модели секвенатора, но остановимся на самом популярном от фирмы Illumina, см картинку).


Затем с каждого фрагмента делается множество его копий, чтобы повысить надежность прочтения.

Машина прочитывает каждый из фрагментов (и копий) и отдаёт результат в виде множества коротких кусочков текста (их называют «риды» (read) или «прочтения»).

На этом этапе легче всего представить, что роман «Война и мир» запихнули в шредер и превратили в салат. Много ли тут прочитаешь?:)

А дальше в бой вступают биоинформатики. С помощью разных математических подходов и алгоритмом они «склеивают» вместе кусочки прочтений, пытаясь восстановить исходный текст.

Но есть проблема: целиком текст восстановить нельзя, в нем обязательно будут отсутствующие куски (их называют «пробелы» или «гэпы» от gap).

Причин для пробелов много.
Например, этот отсутствующий кусочек ДНК находился у самой центромеры в хромосоме (центромера - это кусочек почти в центре хромосомы, его проще всего увидеть в одной из фаз деления хромосомы, тогда он та самая перемычка буквы Х). Вблизи центромеры ДНК туже всего скручена и при расплетении может повредиться.
Или ещё вариант ситуации ведущей к пробелу: по какой-то причине для этого фрагмента ДНК было сделано слишком мало копий (а чем больше у нас копий фрагмента, тем мы увереннее, что читаем его правильно) .
Итак, первая проблема, почему мы не знаем, с какой буквы надо начинать читать: у нас нет целого текста.
Есть лишь собранные из коротких ридов фрагменты (они называются "контиги"). И неизвестно, с какой буквы в контиге начинается "предложение".
Посмотрим пример: что пропущено в «...али они здесь уже давно»?
«бегАЛИ» давно? «спАЛИ»? или «кино снимАЛИ» уже давно?
Вот эта проблема и тут.
Вторая причина, почему с прочтением будут проблемы: а есть ли там вообще ген? И если есть с какой буквы он начинается?
Продолжим разбираться завтра.:)
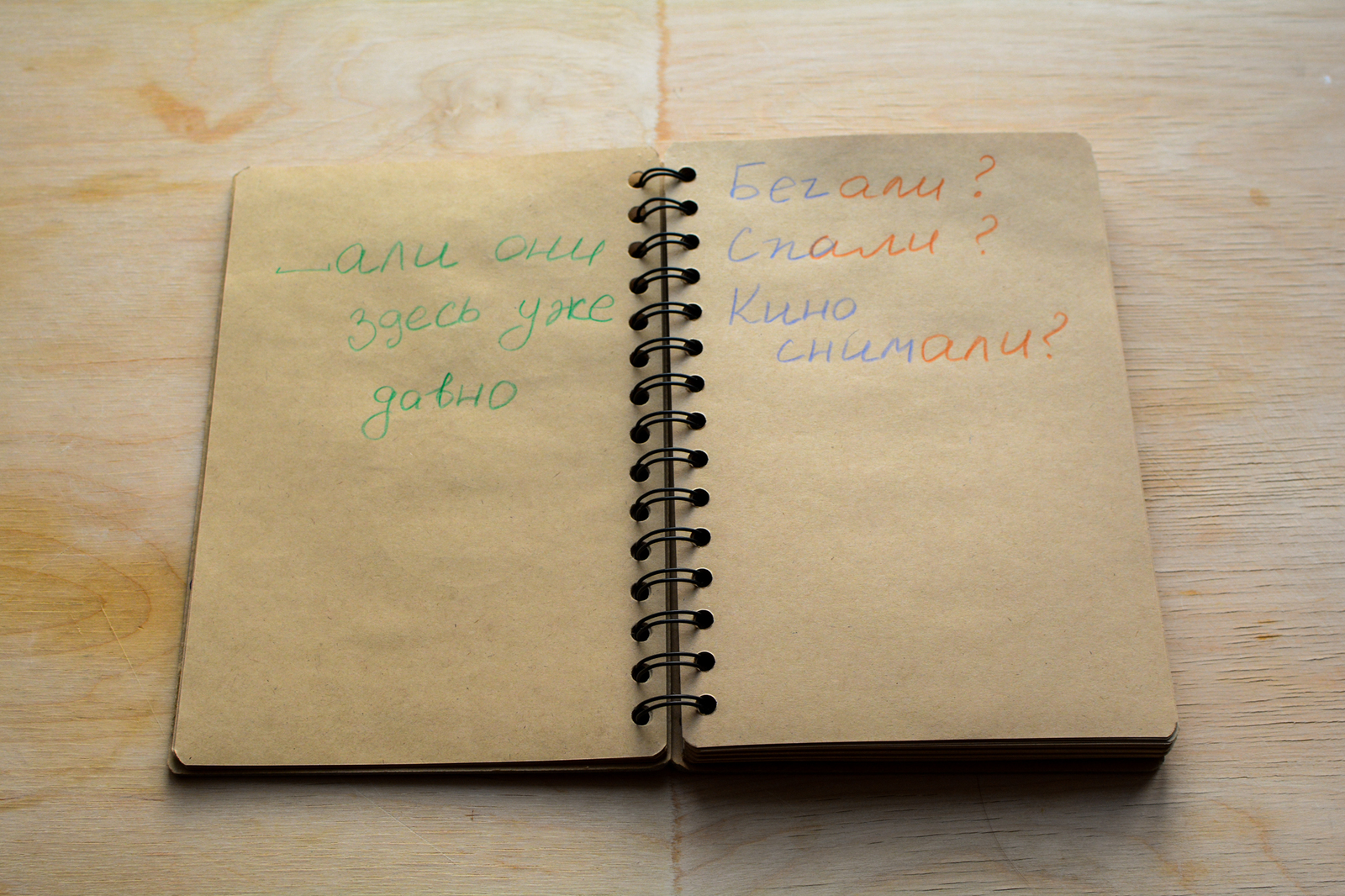
P.S.: В роли "секвенатора" выступает "заряжалка". :)
Написать что ли про принцип работы на иммунохемилюминисцентном анализаторе Architect от фирмы Abbott?
один лишь вопрос: зачем резать войну и мир и пытаться ее собрать, когда можно читать ее целиком? зачем секвентатор режет молекулу?) тема не раскрыта
Вопрос только один.
Насколько популярные нынче генные тесты точны? Дают ли они реальную и обоснованную информацию (т. е. расшифровка по подтверждённым фактам, что вот этот ген - это почти полная гарантия Паркинсона или плохих зубов), или это всё та же математически усреднённая модель?