


Осень, и общага.
Пришло время осенних "брррр...".
И вот нашлось фото) Общежитие. 2-й курс.
середина октября)

upd. Да, были уже нормальные батареи)).
Пришло время осенних "брррр...".
И вот нашлось фото) Общежитие. 2-й курс.
середина октября)
upd. Да, были уже нормальные батареи)).

*Уважаемые чатлане!
Какие-то контрабандисты украли мой "Тысячелетний сокол", самый быстрый космолёт в галактике. Он очень заметен в свете звёзд, и вообще.
Если кто-то увидит его в нашей галактике - звоните в Галактическую Полицию "102" или сообщите мне.
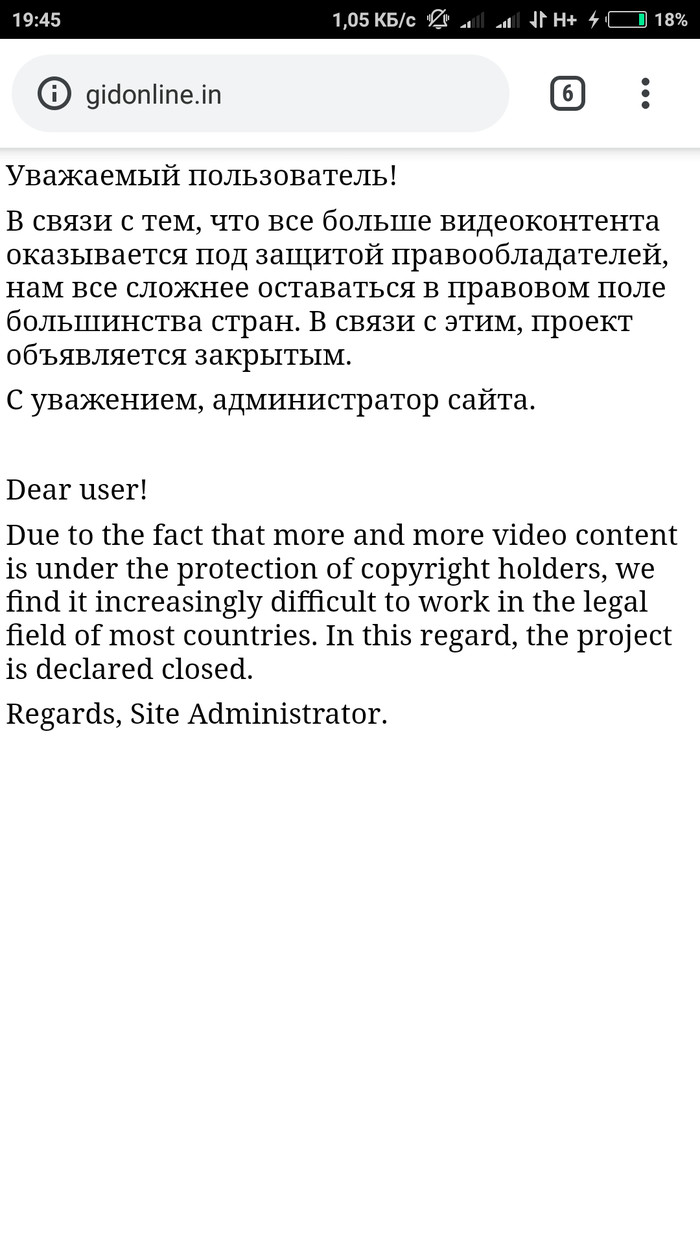
Зашёл вот... Думал посмотрю что-то. Нравился мне гидонлайн, был получше(имхо) всяких шдрезок, фильмиксов, и иже с ними
Увидел пост. Ну, как, увидел) Даже не читал толком, так, "просмотрел"... Вот выдрал вам наши будни из контекста.

Это вот самое читал).
https://pikabu.ru/story/plyusyi_i_minusyi_rabotyi_v_more_584...
пы сы... без всяких там задних мюслей=) Просто увидел. Просто заскринил) Незнаю зачем.
Здравствуйте. Как и обещал, делаю первый пост по таблицам Google. Начнем с парсинга страниц, и попробуем вытащить все комментарии к моему предыдущему посту: https://pikabu.ru/story/google_drive_docs_maps_i_izhe_s_nimi... <- вот к этому.
Давайте попробуем вытащить их к нам в документ(вот сюда: https://docs.google.com/spreadsheets/d/18MfMRSo9cHzsrTM-t4WE...), и посмотрим, что из этого выйдет. Делается это с помощью формулы "importxml". Она умеет получать содержание из таких источников как xml, html, csv, и еще нескольких, но мне пока приходилось работать только с этими.
Итак, пробуем: =IMPORTXML("https://pikabu.ru/story/google_drive_docs_maps_i_izhe_s_nimi...";"*")
У формулы два обязательных параметра. Первый - это источник информации, и второй - это строка запроса и фильтра источника(формируется на xPath). В данном случае "*" означает, что получаем все подряд. Результат, мягко говоря, не очень:)
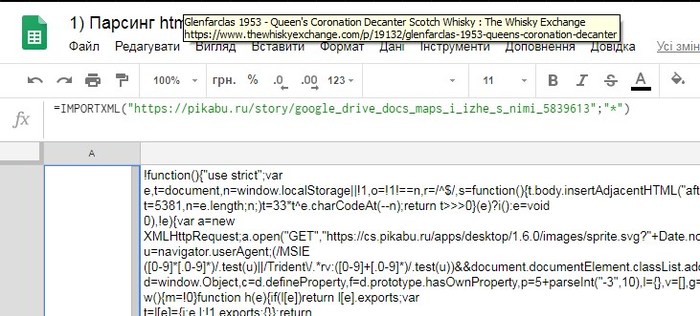
С этим нужно что-то делать, надо как-то отфильтровать нужную нам информацию. Нам ведь нужны только комментарии, без всего вот этого. Значит, нужно понять, как эти самые комментарии можно отличить от остальной информации на странице. В браузере есть такой инструмент, как просмотр кода страницы, открыть его можно клавишей F12. Выглядит вот так:
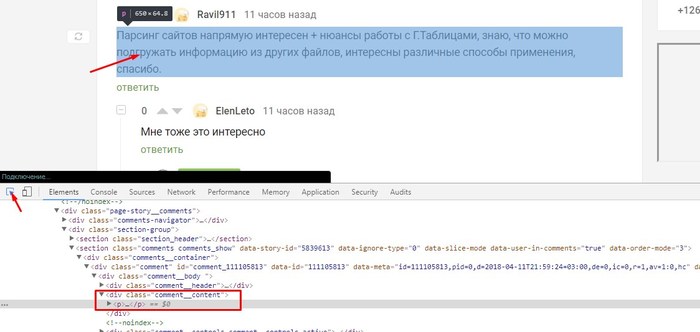
Отсюда видно, что текст коментариев у нас находится в блоке, с названием "comment__content", и теперь можем пробовать использовать это в нашей выборке.
=IMPORTXML("https://pikabu.ru/story/google_drive_docs_maps_i_izhe_s_nimi...";".//*[@class='comment__content']")
Тут нужно пояснить, что же изменилось. Во второй параметр формулы мы добавили ".//*[@class='comment__content']".
То, что в квадратных скобках - наш фильтр, который отсеет все, кроме того, что находится внутри блока с данным класом.
На скриншоте выше нужно пояснить следующее:
Розовенькое - это блок, в котором находится информация или другие блоки.
Ораньжевенькое - это атрибут блока, бывают разные, и может быть много. Помогает идентифицировать блок.
И, наконец, синенькое - это значение атрибута, по которому можна обратится к самому атрибуту.
Звездочка - означает, что искать нужно во всех блоках("div", "section", "p"...).
Две косых линии - это значит, что просматривать нужно все вложенные блоки, а не только первые. На втором скриншоте это серые стрелочки, которыми можно разворачивать блок, и посмотреть, что там внутри.
И, наконец, точка - значит что начать искать нужно с самого начала страницы.
Надеюсь хоть немого понятно) Сильно не пинайте)
Итак, теперь результат выглядит вот так:
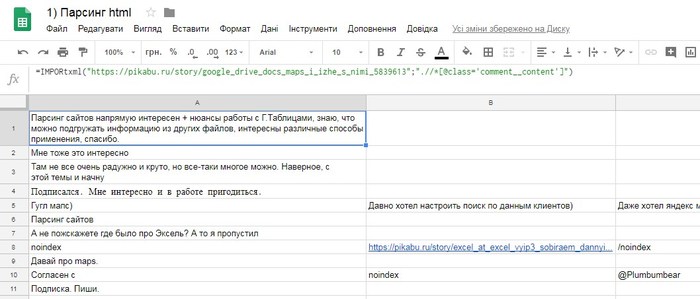
Уже намного лучше, но все-таки не очень.Некоторые комментарии разбиты по разных столбцах(это когда автор при написании на Ентер жмакал:) ), и есть непонятный "noindex".
noindex - это такая штука, которую умный Пикабу добавляет ко всем вашим ссылкам для того, что бы поисковые системы их не индексировали.
Это нужно не нам, а администрации, поэтому попробуем сделать так, что бы он не попадал в наш документ.
Дальше есть два пути решения проблемы. Можно все описать с помощью xPath, а можно использовать и другие формулы. Пользоватся будем формулами, так как в первом случае надо будет делать отдельный пост по xPath :)
Итак, попробуем в соседнюю вкладку вытащить те же комментарии, но так, чтобы они были в одном столбце. Использовать будем функцию textjoin:
=TEXTJOIN(" ";true;'Шаг 2'!1:1), заполняем этой формулой весь столбец.
Итак, что там внутри, и зачем:
Первый параметр - это символ, который будет добавлятся перед каждым соединением ячеек. В нашем случае - пробел.
Второй параметр - логическое значение. Если стоит "true" - то будут пропускатся все пустые ячейки, если поставить "false" - они тоже будут добавлятся к обьединению.
Третий параметр - это диапазон, который обьединяем. В нашем случае - это вся строка.
Результат:
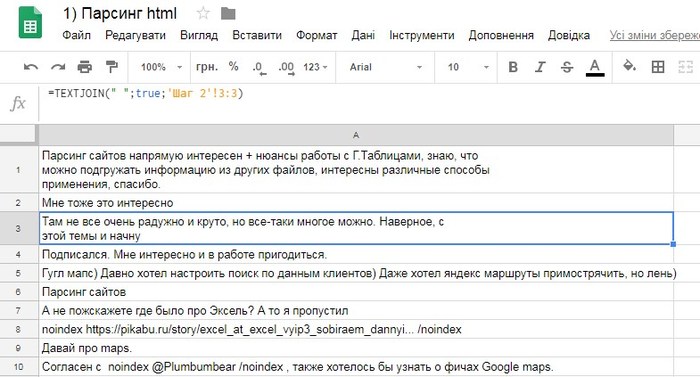
Значит, осталось только забрать noindex. Для этого есть функция SUBSTITUTE, которая умеет искать, и заменять текст. Там все просто, три параметра: первый - где ищем, второй - что ищем, третий - на что меняем. искать нужно "noindex", и "/noindex", значит использовать ее нужно два раза для удаления noindex, и еще раз для удаления двойных пробелов.
=SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(TEXTJOIN(" ";true;'Шаг 2'!1:1);"/noindex";"");"noindex";"");" ";"")
Результат:
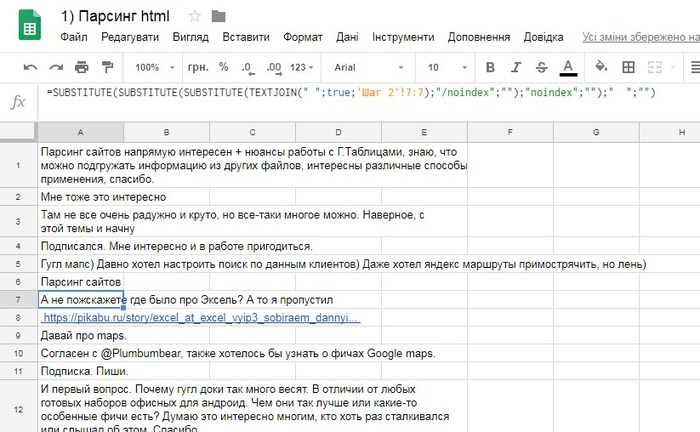
Вот так у нас есть все комментарии к определенной статье.
Для чего это можно использовать? Ну, например можно вместо комментариев получать обьявления с авито)
p.s.
На этом пока все, вышло итак довольно много, и, наверное, немного сумбурно :)
Документ с пошаговым примером:
https://docs.google.com/spreadsheets/d/18MfMRSo9cHzsrTM-t4WE...
Документ с итогом:
https://docs.google.com/spreadsheets/d/1zyxNPnrc2vavor6W1aYV...
Здравствуйте. Увидел сегоднешние посты с гайдами по Екселю, вчитался, вдумался. Это хорошо, круто и нужно. Многие пользуются, многие многого не знают, и не умеют. А тут вот такой неплохой доступный учитель.
Вообщем, почитал-подумал, и понял, что тоже могу кое-что рассказать. Но раз по мелкософту уже гайды есть - взгляд упал на google docs, maps, drive, etc...
Если кому интересно, если кому-то это нужно - могу запилить ряд постов о нюансах этих ресурсов(например парсинг сайтов напрямую в Гугл таблицы, защита просмотра документа при работающем фильтре, могу дать большой-хороший курс по Гугл-мапс апи и по встроенному скриптоврму языку документов)
Что касается таблиц - покажу несколько приемов, которые умеет Гугл, и не умеет Ексель)
Сообщество, если интересно - отпишитесь в комментах что в первую очередь разобрать, и завтра начну пилить пост.
p.s. Пост первый, какой из меня выйдет учитель-писатель ещё хз, посмотрим)