Я новичок и не много понимаю в docker, traefik и в подобных вещах. Пробую настроить панель Traefik для работы с панелью 3x-ui. В дашборде ошибок нет, в логах Traefik вижу следующую ошибку:
traefik | level=error msg="invalid rule: \"HostSNI(`microsoft.com`)\" , has HostSNI matcher, but no TLS on router" entryPointName=https routerName=xui-reality@docker
Из того что я понял — 3x-ui сама выпустит сертификат (но может я не прав).
Из того что я вижу — попробовать убрать tls в entypoint и задавать его только в лейблах там где это необходимо, но если у меня будет много контейнеров это ведь не так удобно? Такое вообще может сработать?
В идеале мне необходима такая конфигурация, чтобы пользователь при обращении к Traefik с доменом {mydomain}.ru:443 направлялся на react-container (думаю это делается простыми http роутерами и в этом нет проблемы), и при этом чтобы работала 3x-ui с прокси на том же 443 порту.
Аллоха, пикабушники и пикабушницы. надумал тут себе собрать домашний сервер для следующих задач: -научиться работать с линуксом (пларирую накатить ubuntu server) и админить сервера; -накатывать разное ПО для программирования (изучаю sql, C#, web программирование, сети и т.д.); -научиться работать с докером; -создать файлопомойку; -создать медиацентр;
Планирую поставить докер, в контейнерах наделать виртуальных машин и их уже использовать под задачи из списка выше;
В связи со всем этим, прошу знающих людей поделиться опытом, может я вообще неправильно все придумал?
Быть системным администратором, которому поручено ежедневно отслеживать и устранять проблемы с производительностью Linux-систем, – чрезвычайно ответственная задача.
Она требует непоколебимой преданности делу, глубокого понимания систем Linux и постоянного стремления к обеспечению оптимальной производительности и надежности.
Я составили список из 20 наиболее часто используемых инструментов мониторинга командной строки. Эти комегда могут оказаться незаменимыми для любого системного администратора Linux/Unix, они могут помочь эффективно контролировать, диагностировать и поддерживать работоспособность и производительность ваших систем.
@linuxkalii – всех любителей Linux, приглашаю в канал, где я публикую полезные советы, гайды, инструменты этичного хакинга и еще кучу всего полезного.
А здесь полезная папка от для всех администраторов и разработчиков, где много годного материала.
Эти инструменты мониторинга доступны во всех версиях Linux и могут быть полезны для отслеживания и поиска реальных причин проблем с производительностью.
Поехали!
1. Топ – Мониторинг процессов в Linux
Top – это база. Командаtop, часто используется многими системными администраторами для контроля производительности Linux и доступна под многими Linux/Unix-подобными операционными системами.
Команда top используется для отображения всех запущенных и активных процессов в режиме реального времени в виде упорядоченного списка. Она отображает использование процессора, памяти, своп-памяти, размер кэша, размер буфера, PID процесса, пользователя и многое другое.
Команда top очень полезна системным администраторам для мониторинга и принятия нужных мер в случае необходимости. Давайте посмотрим команду top в действии.
top
Проверка запущенных процессов Linux
2. VmStat – статистика виртуальной памяти
Команда Linux VmStat используется для отображения статистики виртуальной памяти, потоков ядра, дисков, системных процессов, блоков ввода-вывода, прерываний, активности процессора и многого другого.
Установите VmStat в Linux
По умолчанию команда vmstat недоступна в системах Linux, поэтому вам необходимо установить пакет sysstat(мощный инструмент мониторинга), который включает в себя программу vmstat.
# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 43008 275212 1152 561208 4 16 100 105 65 113 0 1 96 3 0
Инструмент мониторинга системы Vmstat
3. Lsof – список открытых файлов
Команда lsof используется во многих Linux/Unix-подобных системах для отображения списка всех открытых файлов и процессов. К открытым файлам относятся дисковые файлы, сокеты, каналы, устройства и процессы.
Популярная ошибка – когда диск не может быть размонтирован и выдает ошибку, что файлы используются или открыты. С помощью lsof можно легко определить, какие файлы используются.
Наиболее распространенным форматом команды lsof является:
# lsof COMMAND PID TID TASKCMD USER FD TYPE DEVICE SIZE/OFF NODE NAME systemd 1 root cwd DIR 8,2 224 128 / systemd 1 root rtd DIR 8,2 224 128 / systemd 1 root txt REG 8,2 1567768 134930842 /usr/lib/systemd/systemd systemd 1 root mem REG 8,2 2714928 134261052 /usr/lib64/libm-2.28.so systemd 1 root mem REG 8,2 628592 134910905 /usr/lib64/libudev.so.1.6.11 systemd 1 root mem REG 8,2 969832 134261204 /usr/lib64/libsepol.so.1 systemd 1 root mem REG 8,2 1805368 134275205 /usr/lib64/libunistring.so.2.1.0 systemd 1 root mem REG 8,2 355456 134275293 /usr/lib64/libpcap.so.1.9.0 systemd 1 root mem REG 8,2 145984 134261219 /usr/lib64/libgpg-error.so.0.24.2 systemd 1 root mem REG 8,2 71528 134270542 /usr/lib64/libjson-c.so.4.0.0 systemd 1 root mem REG 8,2 371736 134910992 /usr/lib64/libdevmapper.so.1.02 systemd 1 root mem REG 8,2 26704 134275177 /usr/lib64/libattr.so.1.1.2448 systemd 1 root mem REG 8,2 3058736 134919279 /usr/lib64/libcrypto.so.1.1.1c ...
Список открытых файлов в Linux
4. Tcpdump – анализатор сетевых пакетов
Команда tcpdump – одна из самых распространенных программ анализатора сетевых пакетов или сниффера пакетов, которая используется для захвата или фильтрации TCP/IP-пакетов, получаемых или передаваемых на определенном интерфейсе по сети.
Она также предоставляет возможность сохранять захваченные пакеты в файл для последующего анализа. tcpdump доступен практически во всех основных дистрибутивах Linux.
# tcpdump -i enp0s3 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes 10:19:34.635893 IP tecmint.ssh > 192.168.0.124.45611: Flags [P.], seq 2840044824:2840045032, ack 4007244093 10:19:34.636289 IP 192.168.0.124.45611 > tecmint.ssh: Flags [.], ack 208, win 11768, options 10:19:34.873060 IP _gateway.57682 > tecmint.netbios-ns: NBT UDP PACKET(137): QUERY; REQUEST; UNICAST 10:19:34.873104 IP tecmint > _gateway: ICMP tecmint udp port netbios-ns unreachable, length 86 10:19:34.895453 IP _gateway.48953 > tecmint.netbios-ns: NBT UDP PACKET(137): QUERY; REQUEST; UNICAST 10:19:34.895501 IP tecmint > _gateway: ICMP tecmint udp port netbios-ns unreachable, length 86 10:19:34.992693 IP 142.250.4.189.https > 192.168.0.124.38874: UDP, length 45 10:19:35.010127 IP 192.168.0.124.38874 > 142.250.4.189.https: UDP, length 33 10:19:35.135578 IP _gateway.39383 > 192.168.0.124.netbios-ns: NBT UDP PACKET(137): QUERY; REQUEST; UNICAST 10:19:35.135586 IP 192.168.0.124 > _gateway: ICMP 192.168.0.124 udp port netbios-ns unreachable, length 86 10:19:35.155827 IP _gateway.57429 > 192.168.0.124.netbios-ns: NBT UDP PACKET(137): QUERY; REQUEST; UNICAST 10:19:35.155835 IP 192.168.0.124 > _gateway: ICMP 192.168.0.124 udp port netbios-ns unreachable, length 86 ...
Tcpdump – анализатор сетевых пакетов
5. Netstat – сетевая статистика
netstat – это инструмент командной строки для мониторинга статистики входящих и исходящих сетевых пакетов, а также статистики интерфейсов. Это очень полезный инструмент для каждого системного администратора для мониторинга производительности сети и устранения проблем, связанных с сетью.
# netstat -a | more Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:sunrpc 0.0.0.0:* LISTEN tcp 0 0 tecmint:domain 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN tcp 0 0 localhost:postgres 0.0.0.0:* LISTEN tcp 0 0 tecmint:ssh 192.168.0.124:45611 ESTABLISHED tcp6 0 0 [::]:sunrpc [::]:* LISTEN tcp6 0 0 [::]:ssh [::]:* LISTEN tcp6 0 0 localhost:postgres [::]:* LISTEN udp 0 0 0.0.0.0:mdns 0.0.0.0:* udp 0 0 localhost:323 0.0.0.0:* udp 0 0 tecmint:domain 0.0.0.0:* udp 0 0 0.0.0.0:bootps 0.0.0.0:* udp 0 0 tecmint:bootpc _gateway:bootps ESTABLISHED ...
Netstat – мониторинг сетевых подключений Linux
Хотя в настоящее время netstat устарел в пользу команды ss, вы все еще можете обнаружить netstat в своем наборе сетевых инструментов.
6. Htop – мониторинг процессов в Linux
htop – это продвинутый интерактивный инструмент для мониторинга процессов Linux в режиме реального времени, который во многом похож на команду top, но имеет ряд дополнительных приемуществ, таких как удобный интерфейс для управления процессами, клавиши быстрого доступа, вертикальные и горизонтальные отобрадения процессов и многое другое.
# htop
Htop – просмотрщик системных процессов Linux
htop – это сторонний инструмент, который не поставляется с системами Linux, его нужно установить с помощью менеджера пакетов.
7. Iotop – мониторинг дискового ввода-вывода в Linux
iotop также очень похожа на команду top и htopiotop, эта утилита позволяет просмотреть сведения об общем и текущем количестве операций обращения к диску..
Использование данной утилиты, позволяет узнать какой процесс в данный момент времени использует диск и как часто к нему обращаются. Вывод информации утилиты аналогичен утилите htop, отображается активность записи на диск и чтения с диска, использования раздела подкачки, полную статистку обращения к диску процессов и др.
Установка Iotop в Linux
По умолчанию команда iotop недоступна в Linux, и вам нужно установить ее:
Обычно используется следующий формат команды iotop.
# iotop
iotop – Мониторинг использования дискового ввода-вывода в Linux
Утилита iotop запускается только с админскими правами, поэтому для её запуска я использую sudo:
$ sudo iotop
8. Iostat – Статистика ввода/вывода
iostat – это простой инструмент, который собирает и отображает основные параметры ввода/вывода данных на диск, скорость записи и чтения данных, а также объем записанных или прочитанных данных. Этот инструмент часто используется для отслеживания проблем производительности устройств хранения данных, включая.
Установка Iostat
Чтобы установить команду iostat, вам нужно установить пакет sysstat, как показано на рисунке.
iostat – мониторинг статистики дисковых операций ввода-вывода
9. IPTraf – мониторинг IP LAN в режиме реального времени
IPTraf – это консольная утилита мониторинга сети (IP LAN) в реальном времени с открытым исходным кодом для Linux. Она собирает разнообразную информацию, такую как мониторинг IP-трафика, проходящего по сети, включая информацию о TCP, ICMP, трафик TCP/UDP, пакеты TCP-соединений и подсчет байтов.
IPTraf позволяет системному администратору увидеть статистику сетевых пакетов (прошедших через сетевой интерфейс) по протоколам, статистику сетевых пакетов по их размеру и текущую пропускную способность интерфейса.
IPTraf IP сетевой монитор
10. Psacct или Acct – мониторинг активности пользователей
Утилиты psacct или acct очень полезны для мониторинга активности каждого пользователя в системе. Оба демона работают в фоновом режиме и помогают следить за общей активностью каждого пользователя в системе, а также за тем, какие ресурсы он потребляет.
Вы можете посмотреть что делает пользователь, какие команды выполняет, сколько ресурсов использует, как долго активен в системе и т. д.
psacct – Мониторинг действий пользователей Linux
11. Monit – мониторинг процессов и служб Linux
Monit – это бесплатная утилита для активного мониторинга с открытым исходным кодом для операционных систем семейства Linux. Утилита позволяет:
вести мониторинг и контролировать системные процессы, программы, файлы, каталоги регистрируя изменение разрешений файлов, размеров каталогов и контрольных сумм;
остановить ресурсоёмкие процессы, перезапускать сервисы которые перестали отвечать и запускать остановившиеся службы
вывести информацию о статусе каждого процесса, который был поставлен на мониторинг, и о ресурсах, которые операционная система выделяем для работы данных процессов;
Она позволяет следить за такими сервисами, как Apache, MySQL, Mail, FTP, ProFTP, Nginx, SSH. Состояние системы можно просматривать из командной строки или с помощью удобного интерфейса.
Monit Monitor Linux System
12. NetHogs – мониторинг пропускной способности сети для каждого процесса
NetHogs – это небольшая программа с открытым исходным кодом (похожая на команду Linux top), которая отслеживает сетевую активность каждого процесса в вашей системе. Она также отслеживает в реальном времени пропускную способность сетевого трафика, используемую каждой программой или приложением.# nethogs
Nethogs отслеживает сетевой трафик в Linux
13. iftop – Мониторинг пропускной способности сети
iftop – еще одна терминальная бесплатная утилита, которая применяется для мониторинга сетевого трафика на уровне интерфейсов. Iftop отображает информацию о текущем сетевом соединении, передаче данных, скорости передачи данных, а также выводит IP-адреса и порты, с которыми установлены соединения. Утилита является очень полезным инструментом для анализа сетевой активности на сервере, работающем на Linux-системе.
iftop является аналогом ‘top’ в контексте использования сети, подобно тому, как ‘top‘ предоставляет информацию об использовании процессора.
# iftop
iftop – Мониторинг пропускной способности сети
Если вам нужена подробная информация по использованию iptop, наберите в командной строке:
$ man iftop
14. Monitorix – мониторинг систем и сетей
Monitorix – это бесплатная легкая утилита, предназначенная для запуска и мониторинга системных и сетевых ресурсов Linux/Unix-серверов в большом объеме.
Она имеет встроенный HTTP-веб-сервер, который регулярно собирает системную и сетевую информацию и отображает ее в виде графиков. Мониторинг нагрузки на систему и ее использования, распределения памяти, состояния дисковых накопителей, системных служб, сетевых портов, почтовой статистики (Sendmail, Postfix, Dovecot и т.д.), статистики MySQL и многого другого.
Она предназначена для мониторинга общей производительности системы и помогает обнаружить сбои, узкие места, аномальные случае в функционировании вашей системы и т. д.
Мониторинг Monitorix
15. Arpwatch – монитор активности в сети Ethernet
Arpwatch – это программа, предназначенная для мониторинга разрешения адресов (изменения MAC и IP адресов) сетевого трафика Ethernet в сети Linux.
Arpwatch создает журнал замеченных сопряжений IP- и MAC-адресов вместе с меткой времени, так что вы можете внимательно проследить, когда в сети появилась активность сопряжения.
В программе также есть возможность отправлять отчеты по электронной почте администратору сети при добавлении или изменении сопряжения.
Инструмент Arpwatch особенно полезен для сетевых администраторов, следящих за ARP-активностью для обнаружения ARP-спуфинга или неожиданных изменений IP/MAC-адресов.
Arpwatch – мониторинг ARP-трафика
16. Suricata – мониторинг сетевой безопасности
Suricata – это высокопроизводительная система мониторинга сетевой безопасности и обнаружения и предотвращения вторжений с открытым исходным кодом для Linux, FreeBSD и Windows.
Она была разработана и принадлежит некоммерческому фонду OISF (Open Information Security Foundation).
Име
Предоставляет Suricata возможность использования GPU для вычислений в режиме IDS, а также в продвинутой IPS. Система изначально рассчитана на многопоточность.
17. VnStat PHP – мониторинг пропускной способности сети
vnStat PHP — это веб-интерфейс к vnStat, инструменту мониторинга пропускной способности для систем Linux. vnStat PHP позволяет просматривать данные, собранные vnStat, в привлекательном и удобном формате через веб-браузер.
vnStat PHP предоставляет множество вариантов настройки, таких как выбор сетевых интерфейсов для мониторинга и настройка цветов и графики, используемых для отображения данных.
18. Nagios – мониторинг сети/серверов
Nagios – это мощная система мониторинга с открытым исходным кодом, которая позволяет сетевым/системным администраторам выявлять и устранять проблемы, связанные с сервером, до того, как они повлияют на основные бизнес-процессы.
Nagios запускает плагины, хранящиеся на сервере, который подключен к хосту или другому серверу в вашей сети или Интернете. В случае любого сбоя система предупреждает о проблемах, чтобы техническая группа могла немедленно выполнить процесс восстановления.
19. Nmon: мониторинг производительности Linux
Nmon (расшифровывается как Nigel’s Performance Monitor) – это полностью интерактивная утилита командной строки для мониторинга производительности системы Linux, которая изначально была разработана IBM для систем AIX, а затем перенесена на платформу Linux.
Важным преимуществом инструмента nmon является то, что он позволяет отслеживать производительность таких аспектов вашей системы Linux, как загрузка ЦП, использование памяти, дисковое пространство, использование сети, основные процессы, статистика виртуальных машин, файловые системы, ресурсы, микропроцессорная мощность. раздел и многое другое, в одном, сжатом представлении.
Помимо интерактивного мониторинга вашей системы Linux, nmon также можно использовать в пакетном режиме для сбора и сохранения данных о производительности для последующего анализа.
Nmon – инструмент для мониторинга производительности Linux
20. Collectl: Универсальный инструмент для мониторинга производительности
Collectl – это еще одна мощная и многофункциональная утилита командной строки, которая может использоваться для сбора информации о системных ресурсах Linux, таких как использование процессора, памяти, сети, процессов, nfs, TCP, сокетов и многого другого.
Мониторинг коллектора
Расскажите в комментариях какие программы мониторинга вы используете для отслеживания производительности ваших Linux-серверов. Если мы упустили какой-то важный инструмент, который вы хотели бы включить в этот список, пожалуйста, сообщите нам об этом в комментариях и не забудьте поделиться им.
Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
Честно говоря, познакомился с KDE Plasma 4 году в 2015м при установке очередного дебианообразного дистрибутива. На первый взгляд как человеку только познавший Linux , студенту с огромный количеством времени ,под настройку которого было пару уютных чайных вечеров. Сказать что было все по-людски - сложно , изх коробки определенное кол-во твиков , открываешь виджет с погодой - крашится plasma , открыл приложение - крашится plasma , долго не крашится plasma - надо бы крашнутся. Довольно обширный выбор тем , работали процентов 30 не вызывая проблем , касмомизация на уровне , можно все настроить под себя , в отличие от GNOME она была достаточно лёгкая , на моей старой печке , она работала довольно быстро . Запомнилась мне в общем она довольно позитивно , хоть и имела множество проблем.
Не так давно , я решил пересесть на Fedora , выбор DE - это вечно сложный выбор , и я решил по старой памяти выбрать дистрибутив с KDE Plasma 5 , предварительно посмотрел ролики с обзорами пятой плазмы что бы понимать что я пропустил( Оказалось очень много ) .
Плазма 5 из коробки выглядит довольно приятно , убогая стандартная панель , которую я выкидываю в замену Cairo-Dock или Latte-Dock ( о нём узнал от самого сообщества KDE ). KDE Connect очень нравится , очень крутая вещь . Особенно вывести уведомления с телефона , и получать коды авторизации где-либо не отходя от пк.
К чему я придираюсь: Во первых , тот же визуал , да выглядит приятно, кастомизация осталась на уроне plasma 4, тот же родной твик с погодой не умеет в российские города , только одна Москва ( Москвичам в этом плане повезло!) Уродливая панель которая бросается в глаза , была жуткая еще в 4-ке , в пятерке все то же самое. И моё удивление Plasma точно так же падает. Буфер обмена - не умеет копировать картинки , о как же это взбесило , как это возможно из коробки .. Приходится так же допиливать. Темы - абсолютно не адаптированы ко всем приложениям , если вы нашли красивую тему , не факт что в приложении будет все отображаться адекватно , к примеру я часто использую vmware horizon client , при первом запуске мне пришлось редачить конфиги что бы она завелась нормально , т.к были ошибки , после чего я понял что графический интерфейс в по зависим от темы , и при выборе светлой темы перекрываются белые шрифты , идёшь сам в шрифты , ставишь тест потемнее .. и так во многих вещах . Я все таких очень люблю когда из коробки все работает без дополнительных допиливаний , т.к пыл уже не тот как был в 2015-м когда я всем этим яростно интересовался.
В общем ровно месяц как я устроился на KDE , впечатления двухзначные .. , подумываю посмотреть, как сейчас, поживает GNOME.. , тот же GSconnect + очень большой выбор расширений меня сильно привлекают .. Если кто-то сталкивался , какие можно получить грабли из коробки ?
Если кто-то из читателей данного поста занимается настройкой и отладкой tcp/ip стека, вам может быть полезен данный скрипт, который позволяет проверить службу сервера на любом порту на предмет поддержки шифров, протоколов TLS/SSL, а также выявить какие-то дефолтные проблемы. В Readme подробно все описано, комментарии излишне :)
Как-то встала задача увеличить объем зеркального массива на сервере с Debian без потери данных и без простоев. Простых и кратких инструкций в интернете нашел на тот момент не особо много, в основном на английском. Составил для себя на будущее свою, чем с вами и поделюсь сегодня. Может кому пригодится, всякое случается в практике сисадмина.
0. Посмотреть, какие диски каким именам в каталоге /dev соответствуют, и определиться, что будем менять:
lsscsi //простой список (годится, если все диски разных моделей)
lshw -class disk //подробно и с серийниками
1. Пометить каждый раздел RAID на первом заменяемом диске как извлеченный:
mdadm --manage /dev/mdX --fail /dev/sdYZ
mdadm --manage /dev/mdX --remove /dev/sdYZ
где X - номер массива, соответствующего диску
Y - буква заменяемого диска
Z - номер раздела RAID на этом диске, соответствующий массиву X
2. Заменить первый диск на новый.
3. Создать на новом диске разделы RAID, используя все свободное пространство кроме нескольких последних МБ. Пример:
parted -a optimal /dev/sdY
(parted) mklabel gpt //схема разметки GPT
(parted) mkpart primary 2048s 5999GB //создать раздел размером 5999 ГБ (не ГиБ!), начиная с 2048 сектора
(parted) set 1 raid on //пометить его тип как RAID
(parted) print //вывести список разделов диска для проверки
где Y - буква нового диска (внимание, не спутайте с другим, а то потеряете на нем данные!)
4. Добавить разделы нового диска в соответствующие массивы:
mdadm --manage /dev/mdX --add /dev/sdYZ
где X - номер массива
Y - буква нового диска
Z - номер раздела RAID на этом диске, соответствующий массиву X
5. Подождать окончания синхронизации. Проверка статуса:
cat /proc/mdstat
6. Повторить шаги 0-5 для второго заменяемого и второго нового дисков.
7. Увеличить соответствующие замененным дискам массивы:
mdadm --grow /dev/mdX --bitmap none
mdadm --grow /dev/mdX --size=max
{Подождать окончания синхронизации}
mdadm --grow /dev/mdX --bitmap internal
где X - номер массива
8. Увеличить файловые системы соответствующих из шага 7 массивов:
Итак, у вас есть буханка ржаного хлеба, духовка и задача развернуть сервер с поддержкой DHCP и DNS? Это слышать как серьезная миссия, но мы возьмемся за нее со всей серьезностью.
Ингредиенты:
- 1 буханка ржаного хлеба
- 1 компьютер с возможностью установки серверных приложений
- 1 духовка
- порция веселого настроения
Инструкция:
Шаг 1: Создание сервера на буханке ржаного хлеба
Начнем с самого главного – наш серверный хлеб! Возьмите буханку ржаного хлеба, и осторожно обрежьте верхнюю часть. Затем аккуратно выньте сердцевину, чтобы освободить место для будущего сервера. Это будет ваш «корпус» сервера. Сейчас самое время для фантазии – вырежьте отверстия для вентиляции и разъемов для подключения. После того, как вы проделали все это, пришло время украсить ваш сервер. Вот именно, у вас создан уникальный сервер на ржаном хлебе!
Шаг 2: Подготовка духовки для развертывания
Теперь, когда у вас великолепно выглядящий сервер, давайте поговорим о том, как создать поддержку DHCP и DNS. Предварительно разогрейте вашу духовку до 180 градусов.
Шаг 3: Установка DHCP и DNS
Время начать нашу серверную магию. Вставьте буханку хлеба в духовку, чтобы он прогрелся и стал готов для размещения серверных приложений. На этом этапе также отлично подойдет время для краткого отдыха – развертывание сервера это серьезное дело, но и отдыхать нужно не менее серьезно.
Как только ваша "платформа" наберется сил, приступайте к установке приложений. Начнем с подключения DHCP: этот этап будет сложнее. Возьмите масло – оно поможет соединить устройства в сети. А теперь к делу: налейте его на сервер – не стесняйтесь, можно даже щедро. Теперь приступаем к установке DNS. Здесь нам понадобится немного сахара – вот это сладко! Посыпьте его сверху сервера и равномерно распределите по поверхности. Поставьте сервер обратно в духовку на 15 минут, чтобы установленные приложения пропеклись и полностью впитались.
И вот ваш сервер на ржаном хлебе готов к использованию с поддержкой DNS и DHCP! Готовы ли вы к этому? Надеемся, ваш ответ будет - да!
Наслаждайтесь результатом вашего непростого труда, и да помогут вам все серверные боги!
Любопытно. Всего у нас 4.9 гигов. 4.6 из них использовано. Но занятыми почему-то считается все 100% дискового пространства. Куда делось 300 метров?
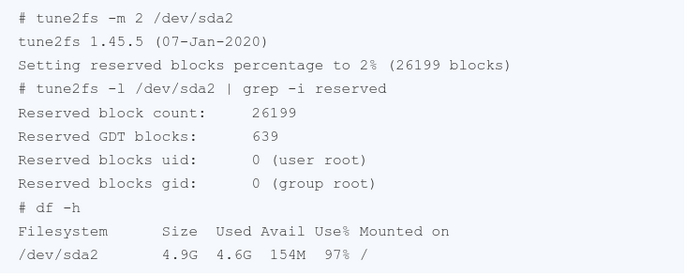
В поисках ответа, рассмотрим более детально файловую систему с помощью tune2fs:
Так, у нас тут есть какие-то зарезервированные блоки. Для того, чтобы прояснить что за блоки нам встретились, вновь обратимся к Linux API исчерпывающее руководство от Майкла Керриска, стр. 312 (просто удобно делать все отсылки к одной книге, хотя в Advanced Programming in the Unix Environment про это тоже можно почитать)
Многие «родные» файловые системы UNIX и Linux поддерживают представление о резервировании некоторой части блоков файловой системы для суперпользователя на тот случай, когда файловая система становится заполненной. Суперпользователь по-прежнему может войти в систему и принять меры по устранению данной проблемы. Если в файловой системе есть зарезервированные блоки, то разность значений полей f_bfгее и f_bavail в структуре statvfs сообщит нам, сколько блоков зарезервировано.
То есть место было зарезервировано для того, чтобы поддержать работу системы на тот случай, если свободного места на диске вообще не останется.
Теперь давайте слегка изменим настройки файловой системы, чтобы у нас появился небольшой запас пространства, и немного времени на решение проблемы:
Отлично, теперь есть немного места, и можно более-менее в штатном режиме начать поиск решения.
Заключение
многие файловые системы резервируют дисковое пространство для суперпользователя. Это механизм защиты, позволяющий поддерживать работу системы (и разрешать администратору вход в систему), когда на диске не осталось свободного места.
объем зарезервированного пространства можно изменить. Это сделает некоторое количество блоков пригодными для использования и поможет вам выиграть немного времени. Но будьте осторожны, вам все равно нужно проанализировать, что происходит, и исправить это должным образом.
на больших файловых системах (>50–100 ГБ) резервирование 5% является излишним. Так что возможно вы захотите проверить свою файловую систему и уменьшить количество зарезервированных блоков (однако к любому тюнингу и оптимизации нужно подходить с умом и без фанатизма).