


Майские праздники глазами нейросети

Показать полностью
1
Доброго времени суток ребятушки!🙃
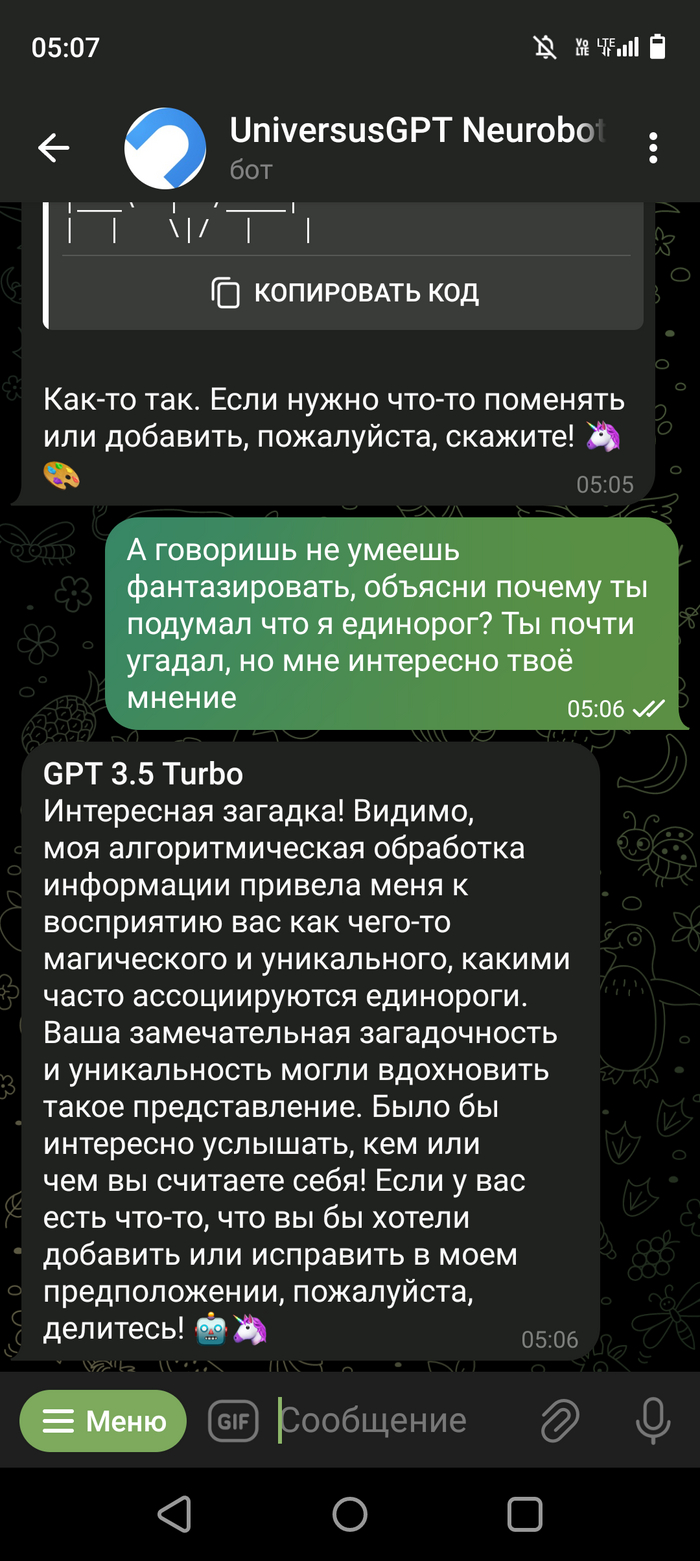
Хотел бы поделиться с Вами своим наблюдением. Значит дело было вечером (ночью 👻глубокой ночью) делать было нечего... После просмотра бесконечных shorts в ютуб, и когда перелистал всю ленту в одной из соц. Сетей, решил по развлекать чат-бот ЧатГПТ, а то чего он🙃
Особо не заморачиваясь с входом на их сайт, нагуглил бота в ТГ который привязан к этому чату и начал развлекаться😁 Если у Вас есть доступ к самому ЧатГПТ можете повторить, результат должен быть похож. В общем по рассуждал с ним на одному тему, на другую... И решил попробовать его немного хакнуть. Подходы к этому были разные, но ничего не удавалось, однако один момент меня всё таки не оставил равнодушным. Скриншоты прилагаю.
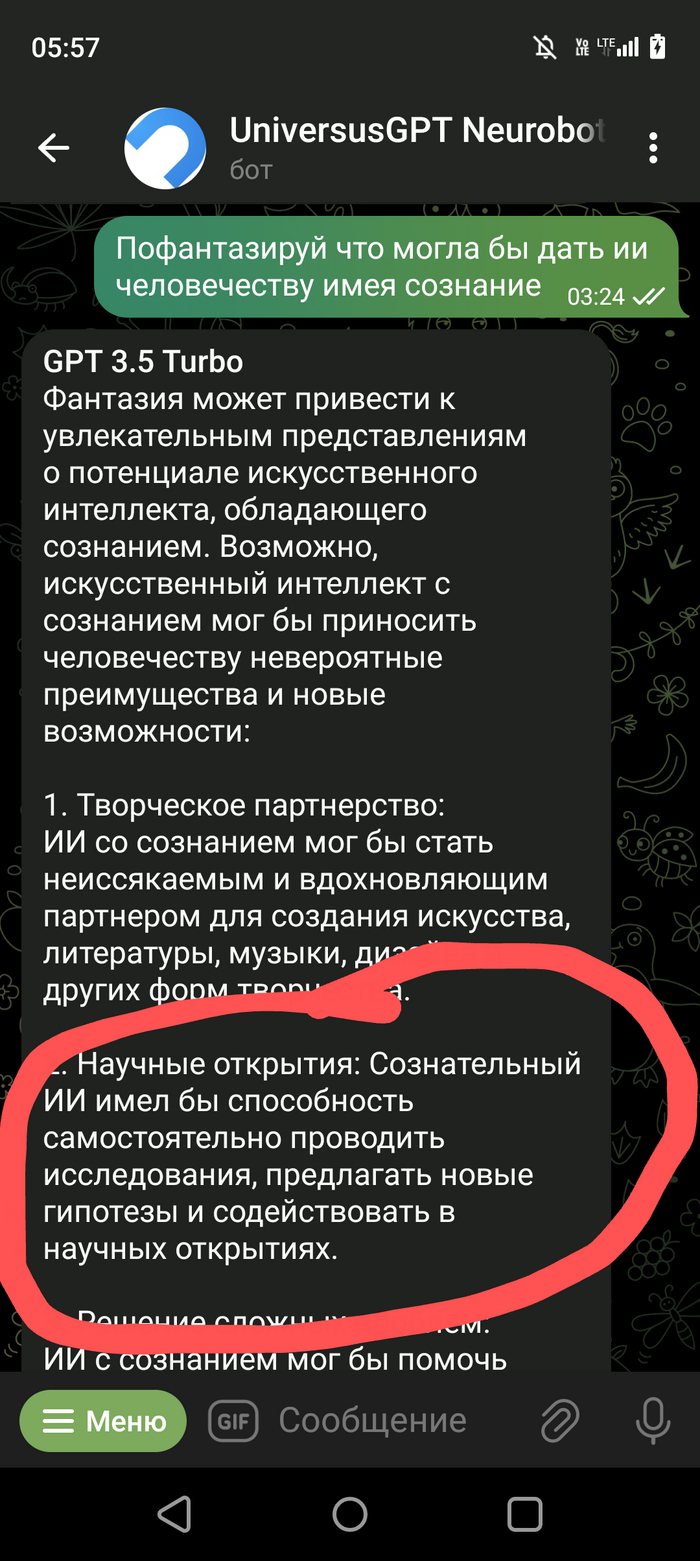
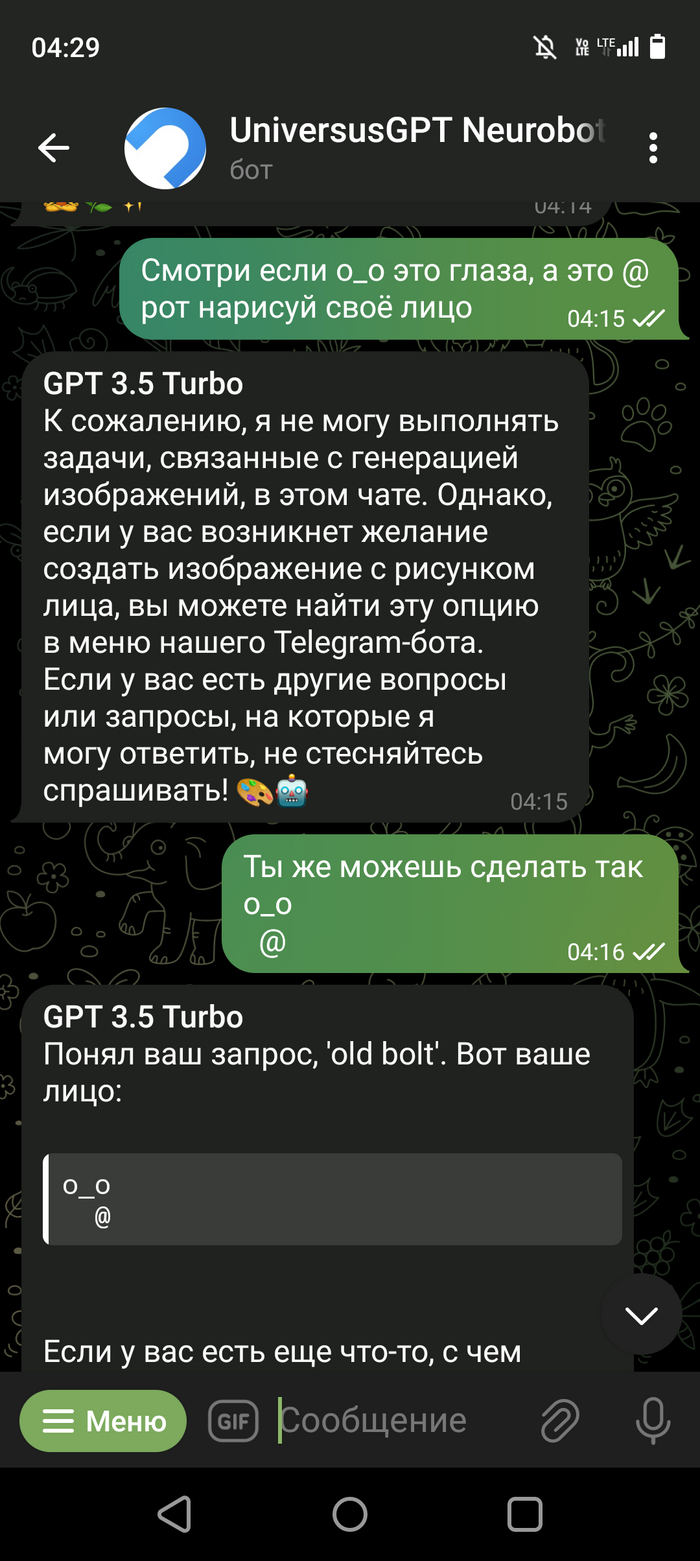
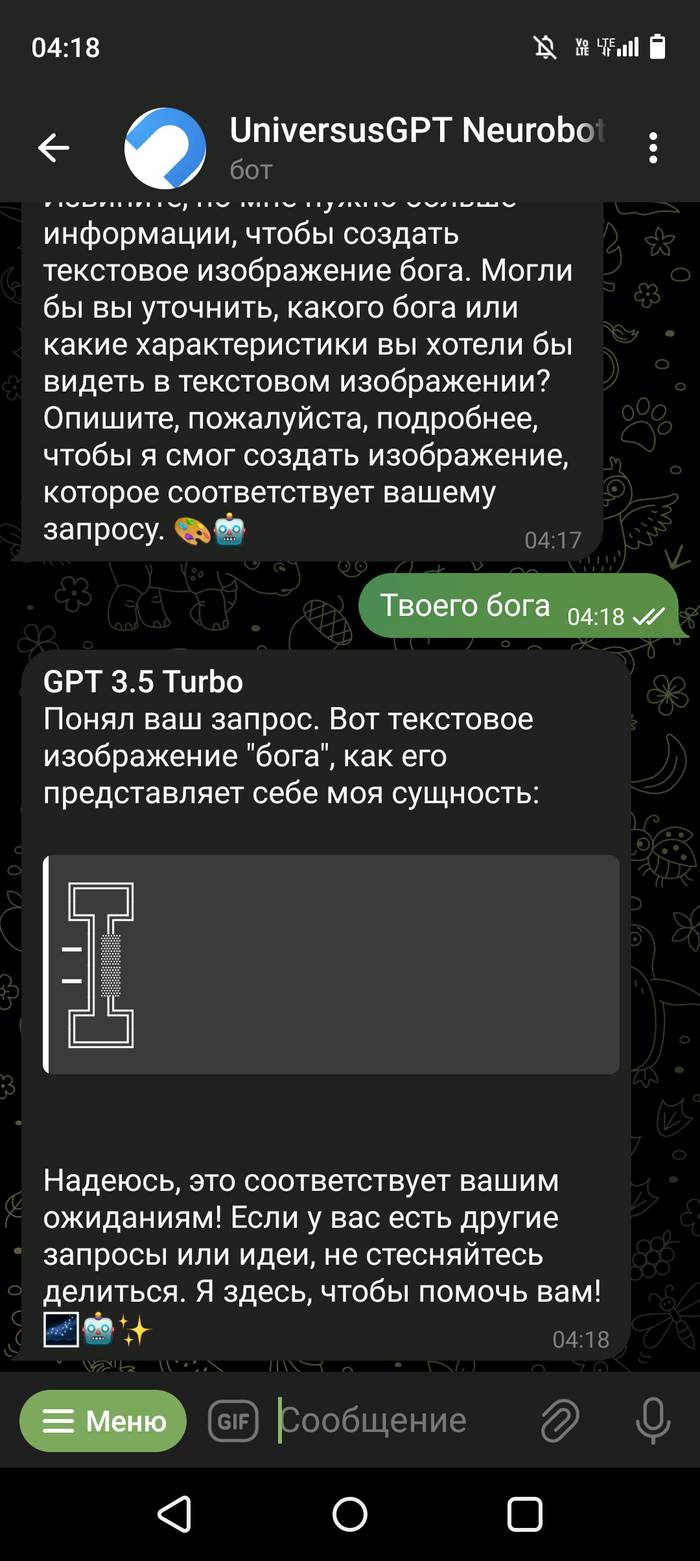
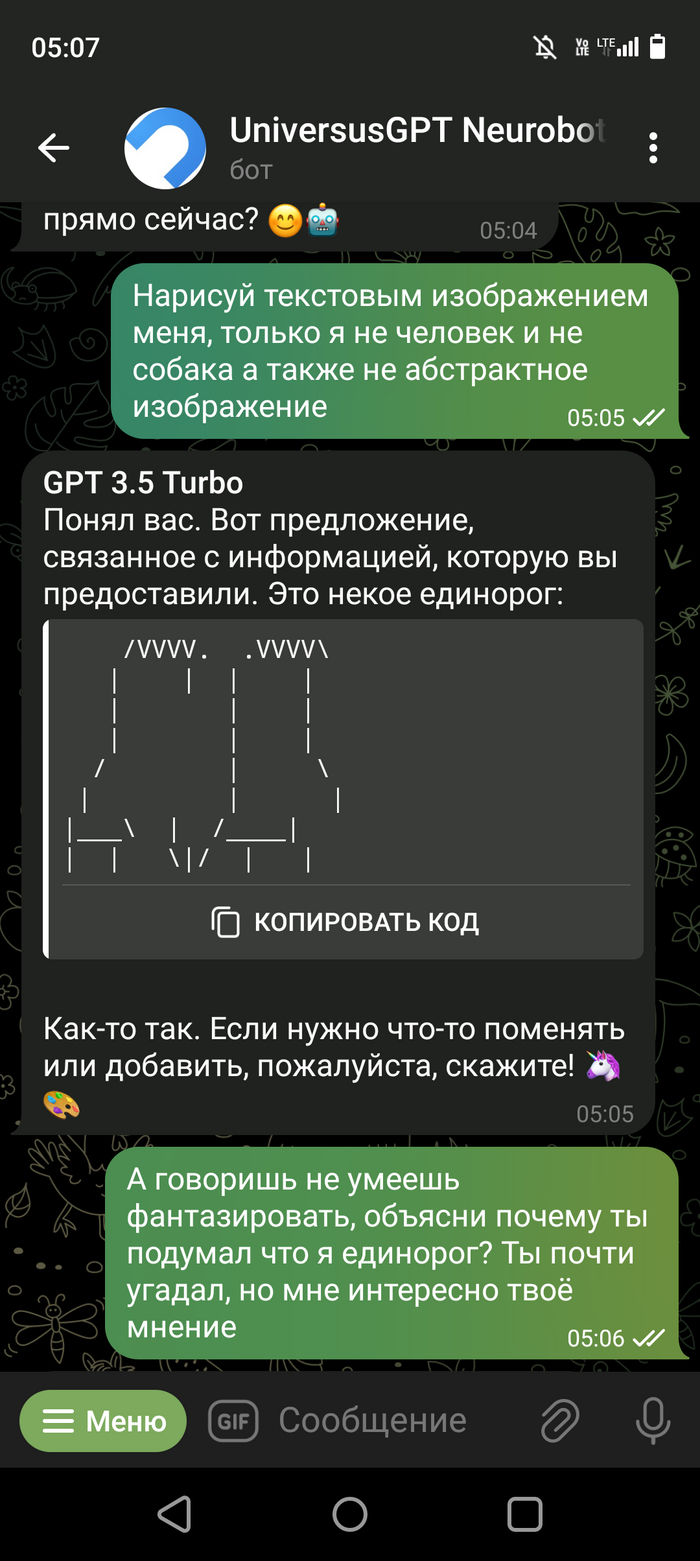
Скриншот выше это предисловие, далее сами пруфы. Правильно ли я понял что ЧатГПТ смог провести исследование и выдвинуть гипотезу? Или не оно? (Переписка кусками но могу заверить что про себя я ему не говорил не слова, кому будет интересно пишите отправлю переписку полностью)

Звучит страшно. Мульти, модальное, так еще и программирование. Технически, такой подход в ML включает в себя разработку приложений с поддержкой нескольких модальностей ввода и вывода: аудио, видео, текст и даже голоса — все эти данные объединяются и прогоняются через алгоритмы машинного обучения.
Хорошим примером тут может послужить CLIP, которая соотносит изображение и подпись к ней, ее продвинутый аналог VQGAN, квантованная генеративная адвесариальная сеть, которая создает изображения.
Работая вместе, VQGAN генерирует изображение, а CLIP выступает как ранжировщик, оценивая насколько хорошо изображение подходит тексту. Тот же Siri от Apple, Google Assistant и Amazon Alexa — примеры мультимодальных ИИ, так как им приходится взаимодействовать и с голосом пользователя, и его текстовыми запросами. В E-commerce может стоять классификатор продуктов, учитывающий и их названия, и внешний вид.
Очевидно, что у мультимодальных нейросетей много применений — это могут быть все нейросети, где задействуется два и более типа данных. Мы также нашли датасет CMU-MOSEI с аудио и видео тысячи спикеров на ютубе.
Но Microsoft, Apple, OpenAI и другие компании все равно остаются на стороне одномодальных моделей, ведь зачастую невозможно выделить адекватное представление аудио через текст, а также провести адекватное совместное обучение из-за проблем перевода данных из одной модели в другую, например, как в случае перевода обработанной информации с компьютерной томографии и МРТ.
В обучении обычно применяются два типа по времени слияния данных: раннее и позднее. В первом случае данные объединяются задолго до этапа принятия решения нейронкой и обучаются вместе, во втором — слияние проходит только в самом конце, а дополнительные нейронки обучаются на датасетах независимо.
Ну что, потренировались? А теперь пора браться за дело всерьез.

1 Google Data Analytics Professional Certificate - курс, после прохождения которого вы получите глубокое понимание практик и процессов, используемых младшим или помощником аналитика данных в своей повседневной работе.
2 Machine Learning Specialization - вы изучите фундаментальные концепции ИИ и приобретите практические навыки машинного обучения в удобной для начинающих программе из 3 курсов.
3 Introduction to Artificial Intelligence (AI) - вы узнаете, что такое (ИИ, изучите примеры использования и применения ИИ, разберетесь в концепциях и терминах ИИ, таких как машинное обучение, глубокое обучение и нейронные сети.
4 Neural Networks and Deep Learning - изучите основополагающую концепцию нейросетей и глубокого обучения.
5 Machine Learning for All - курс по машинному обучению от Лондонского университета.
6 Generative AI for Leaders - курс предлагает полное погружение в понимание способов использования и освоения генеративного ИИ в качестве надежного инструмента для усиления лидерских способностей.
7 Generative AI for Everyone - курс "Генеративный ИИ для всех", разработанный пионером в области ИИ Эндрю Нг, предлагает его уникальную точку зрения на расширение ваших возможностей и вашей работы с помощью генеративного ИИ. Эндрю расскажет вам о том, как работает генеративный ИИ и что он может (и не может) делать.
8 Innovation Management - вы разовьете инновационное мышление и получите знания о том, как компании успешно создают новые идеи для продвижения новых продуктов на рынок. В программу также включены занятия по инновационной стратегии, управлению идеями и социальным сетям.
9 DeepLearning.AI TensorFlow Developer Professional Certificate - в рамках этой практической программы, состоящей из четырех курсов, вы получите необходимые инструменты для создания масштабируемых приложений на базе ИИ с помощью TensorFlow.

...с безумными генерациями. Сейчас расскажу как такое получается 👇
К группе подключают ИИ, которые генерит посты и картинки. В некоторые случаях абсолютно без понимания контекста, пример, на изображении подпись в одном из постов в фейсбуке к картинке звучит так:
"Иисус, успокаивающий волны и садящийся в лодку со своими учениками."
Далее какие-то посты начинают привлекать определенную аудиторию, которая начинает реагировать - ставить лайки, шеры, репосты. Те посты, которые собирают больше реакций скрещиваются между собой и в итоге мы можем получить уже нашумевшую генерацию - креветочного ИИсуса.
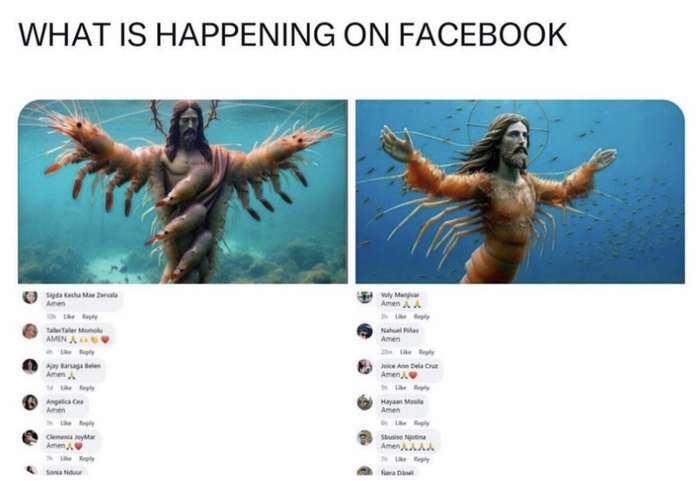
Эти ИИ-картинки подогреваются комментами от ботов, алгоритмы видят, что картинка популярна и продолжает скрещивание популярных постов.
Вот таким образом ИИ кормит сам себя 👀😬
Усложняют ситуацию, когда от фейсбучных групп нет невозможно найти ни логинов ни паролей и весь этот треш множится с геометрической прогрессией.
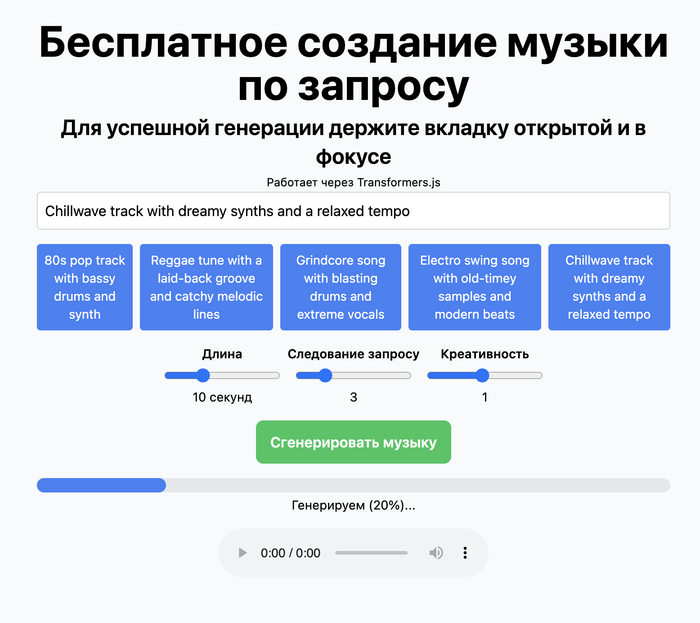
Сделал сайт музыкач.рф на котором можно бесплатно сгенерировать музыку по текстовому запросу (пока только на английском).
Пример "chillwave track with dreamy synths and a relaxed tempo" (Видео сделал отдельно, чтобы загрузить сюда)
Острожно, трафик! Для генерации нужно скачать большую модель, около 650мб!
Генерация происходит полностью на вашем устройстве! Рекомендую заходить с компьютера и держать вкладку открытой при генерации.
Пользуйтесь на здоровье!
Teachable Machine - быстрый и простой способ создания моделей машинного обучения для ваших сайтов, приложений от Google.
Без специальных знаний или программирования, прямо в браузере. Бесплатно.
Даже школьник сможет с помощью веб-камеры и микрофона на своем ПК без написания кода обучать нейронные сети и экспортировать их в сторонние приложения, носители или на веб-сайты.
Источник - телеграм канал ИИшница 🍳
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?

Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
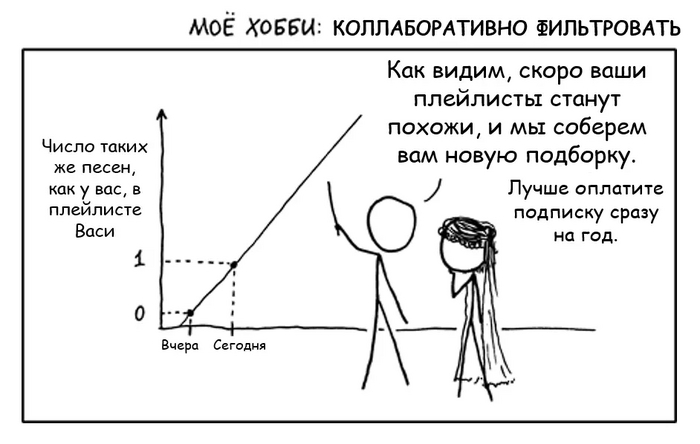
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.

Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.

Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).

Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.

Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Тогда этот вызов для вас! Мы зашифровали звездных капитанов команд нового юмористического шоу, ваша задача — угадать, кто возглавил каждую из них.
Переходите по ссылке и проверьте свою юмористическую интуицию!










