Кластеризация относится к задаче разделения набора данных на группы (кластеры) таким образом, чтобы объекты внутри одного кластера были более похожи друг на друга, чем на объекты из других кластеров.
Кластер содержит набор схожих элементов, которые нужно раскидать по группам в процессе последующего анализа. Зачастую кластерный анализ проводится в тех случаях, когда мы уверены, что все элементы можно как-то сгруппировать. Но предварительно не знаем, по каким признакам это можно сделать.
Мы открываем космос, а не заранее предписываем, как должны выглядеть звезды или галактики.
В отличие от классификации, в кластеризации метки классов не предоставляются, и алгоритмы кластеризации должны самостоятельно определить структуру данных. Главная цель кластеризации — выделить скрытые структуры в данных. Алгоритмы кластеризации идут под методы "k-средних", иерархической кластеризация, DBSCAN ну и так далее.
А вот классификация — задача прогнозирования меток классов для новых экземпляров данных на основе обучающего набора, в котором каждый экземпляр данных имеет уже известную метку класса. Короче говоря, нужно проводить предварительную разметку, распределить все данные по классам.
Задача “классификации” — найти функцию, которая отображает входные данные в заданные классы. Алгоритмы классификации строятся с использованием маркированных данных. Мы уже знаем, по каким признакам будем делить объекты в данных.
Итого:
В классификации имеются явно определенные метки классов для каждого обучающего примера, в то время как в кластеризации метки классов отсутствуют.
Цель классификации — предсказать класс нового экземпляра данных, тогда как цель кластеризации — выделить группы схожих объектов без предварительно определенных классов.
В классификации используются методы обучения с учителем, тот же метод опорных векторов, в то время как в кластеризации применяются методы обучения без учителя.
Выкручивайте остроумие на максимум и придумайте надпись для стикера из шаблонов ниже. Лучшие идеи войдут в стикерпак, а их авторы получат полугодовую подписку на сервис «Пакет».
Кто сделал и отправил мемас на конкурс — молодец! Результаты конкурса мы объявим уже 3 мая, поделимся лучшими шутками по мнению жюри и ссылкой на стикерпак в телеграме. Полные правила конкурса.
А пока предлагаем посмотреть видео, из которых мы сделали шаблоны для мемов. В главной роли Валентин Выгодный и «Пакет» от Х5 — сервис для выгодных покупок в «Пятёрочке» и «Перекрёстке».
Реклама ООО «Корпоративный центр ИКС 5», ИНН: 7728632689
Звучит страшно. Мульти, модальное, так еще и программирование. Технически, такой подход в ML включает в себя разработку приложений с поддержкой нескольких модальностей ввода и вывода: аудио, видео, текст и даже голоса — все эти данные объединяются и прогоняются через алгоритмы машинного обучения.
Хорошим примером тут может послужить CLIP, которая соотносит изображение и подпись к ней, ее продвинутый аналог VQGAN, квантованная генеративная адвесариальная сеть, которая создает изображения.
Работая вместе, VQGAN генерирует изображение, а CLIP выступает как ранжировщик, оценивая насколько хорошо изображение подходит тексту. Тот же Siri от Apple, Google Assistant и Amazon Alexa — примеры мультимодальных ИИ, так как им приходится взаимодействовать и с голосом пользователя, и его текстовыми запросами. В E-commerce может стоять классификатор продуктов, учитывающий и их названия, и внешний вид.
Очевидно, что у мультимодальных нейросетей много применений — это могут быть все нейросети, где задействуется два и более типа данных. Мы также нашли датасет CMU-MOSEI с аудио и видео тысячи спикеров на ютубе.
Но Microsoft, Apple, OpenAI и другие компании все равно остаются на стороне одномодальных моделей, ведь зачастую невозможно выделить адекватное представление аудио через текст, а также провести адекватное совместное обучение из-за проблем перевода данных из одной модели в другую, например, как в случае перевода обработанной информации с компьютерной томографии и МРТ.
В обучении обычно применяются два типа по времени слияния данных: раннее и позднее. В первом случае данные объединяются задолго до этапа принятия решения нейронкой и обучаются вместе, во втором — слияние проходит только в самом конце, а дополнительные нейронки обучаются на датасетах независимо.
Наверное, это будет самый сложный пост в моей жизни, так как я никогда ранее не вел блог или что-то подобное. Я хочу начать серию постов, которая будет содержать реальные проекты по программированию на фрилансе. Зачем это? Просто хочется делиться любым опытом с сообществом. Возможно кому-то даже удастся помочь или просто обсудить проект.
Сразу скажу, я не профессиональный программист. Все, что я знаю - черпал в разное время из книг и Youtube. Да, когда-то начинал по книге изучать Delphi, а с помощью форумов и HTML писал для себя простенькие сайты. Прошло довольно много времени, изучение было успешно отложено. Около года назад снова заинтересовало написание кода, выбор пал на распиаренный Python. В общем сейчас владею небольшим багажом знаний по Python, HTML верстке с CSS, JavaScript и немного C# (На C# имеется опыт в написании плагинов для игры Rust).
В данный момент есть огромное желание практиковаться, сталкиваться с трудностями и искать решения. Именно поэтому подался на фриланс. Конечно, я не буду рекламировать площадки при публикации проектов.
Ну и чтобы завершить данный поток написанных слов, расскажу о своем первом опыте на фрилансе. Как и ожидалось мной, опыт был негативным в силу моего доверия к людям. Мне удалось взять задание по редактированию шаблона сайта на Joomla. Ранее я уже сталкивался с этой CMS и базовые принципы работы имелись. Как это обычно бывает, заказчику потребовалось больше, чем было указано в описании задания. Я согласился, так как хотелось получить опыт в реальном заказе. Сейчас я не буду описывать в чем конкретно заключалась задача и ее многочисленные подзадачи в виде "мелких" правок и какова была реализация. Скажу только итог - я выполнил всю работу и не получил за свою работу ни копейки. Да, таков был первый опыт.
Я очень надеюсь, что найдутся те, кому это будет интересно. Надеюсь, что найдутся и те, кто будет тоже делиться своими знаниями. В общем, Пикабу, не кидай камни)
Что такое random_state в машинном обучении? Зачем нужен этот парметр и как его выбрать? А что вообще общего у числа 42 с культовой книгой “Автостопом по галактике”? И разве случайности не случайны?..
Что такое random_state и как его настройка влияет на обучение моделей?
Возможно, многие из вас уже слышали о параметре random_state, особенно если вы сейчас погружаетесь в ML-разработку. Или вы уже пробовали работать с этим параметром, разбивая набор данных на обучающую и тестовую выборки.
Если же забыли или сейчас столкнулись с randome_state впервые, рассказываем, что это такое.
Параметр `random_state` в ML-разработке обычно используется для установки начального состояния генератора случайных чисел. Этот параметр часто встречается в алгоритмах машинного обучения, которые включают случайные элементы. Например, инициализация весов модели, разделение данных на обучающий и тестовый наборы, случайная инициализация параметров и т. д.
Представьте, что вы выполняете задание, в котором нужно использовать случайные числа. Например, вы разделяете данные на обучающую и тестовую выборки, и вам нужно случайным образом выбрать часть данных для обучения и часть для тестирования модели.
`random_state` — это как начальное число, которое указывает компьютеру, как начать генерацию случайных чисел. Если вы каждый раз используете одно и то же значение `random_state`, то каждый раз, когда вы запускаете эксперимент, вы будете получать те же самые случайные числа. Это помогает сделать ваше исследование воспроизводимым. То есть каждый раз, когда вы запускаете эксперимент с одним и тем же `random_state`, вы получаете те же самые результаты.
Почему это важно?
Предположим, что у вас есть модель, которая дает вам хорошие результаты на определенном наборе данных. Вы хотите сравнить ее с другой моделью или настройками. Если вы используете один и тот же `random_state`, то обе модели будут тестироваться на тех же самых данных, что позволит вам честно сравнивать их результаты.
random_state = 0 or 42 or none
Чаще всего люди устанавливают значение random_state на 0 или 42. Но вы знаете, почему это так?
Простота запоминания
Числа 0 и 42 довольно легко запомнить, поэтому они часто используются как стандартные значения для `random_state`.
Распространенность
Эти числа стали популярными благодаря их частому использованию в примерах и обучающих материалах. Честно говоря, многие останавливаются на этих значениях, даже если они не понимают их смысла.
Теперь давайте рассмотрим каждое число отдельно:
- 0 — часто используемое значение, потому что оно приводит к одинаковым результатам при каждом запуске программы, что удобно для проверки и воспроизводимости экспериментов.
- 42 — это число стало популярным после того, как стало известно, что автор Дуглас Адамс использовал его в своей книге "Автостопом по галактике" как ответ на вопрос о смысле жизни, вселенной и всего такого. В итоге эта сцена стала культовой, поэтому теперь это число часто используется в качестве самого простого способа установить `random_state`.
Таким образом, когда люди говорят о том, что чаще всего используют числа 0 или 42 для `random_state`, они обычно имеют в виду, что это стандартные значения, которые многие выбирают из привычки, не всегда понимая, почему именно эти числа используются.
Что такое random_state?
В библиотеке Scikit-learn этот параметр управляет перетасовкой данных перед их разделением. Мы используем его в функции train_test_split для разделения данных на обучающую и тестовую выборки.
Он может принимать следующие значения:
1. Нет (по умолчанию). Если не указано значение, то используется глобальный экземпляр случайного состояния из библиотеки numpy.random. Если мы вызываем функцию с random_state=None, то каждый раз получаем разные результаты.
2. Целое число. Установка любого значения из целого числа для random_state дает один и тот же результат при каждом выполнении программы. Изменение значения random_state приведет к изменению результата.
Важно помнить, что random_state не может быть отрицательным числом!
Как это работает?
Допустим, у нас есть набор из 10 чисел, от 1 до 10. Теперь, когда мы хотим его разделить на обучающую и тестовую выборки, мы решаем, что размер тестовой выборки должен составить 20% от всего набора данных.
Получается, что в обучающем наборе будет 8 чисел, а в тестовом — 2. Это важно для того, чтобы каждый раз получать одинаковые результаты при запуске кода. Если мы не перетасуем данные, то каждый раз будем получать разные выборки. А это может некачественно сказаться на обучении модели.
Немного подробнее: когда мы устанавливаем значение `random_state` для наших случайных процессов, мы фактически фиксируем начальное состояние генератора случайных чисел. Это гарантирует, что каждый раз, когда мы запускаем наш код с тем же значением `random_state`, то получаем одинаковый набор случайных чисел. И в нашем случае, когда мы используем этот `random_state` для разделения данных на обучающий и тестовый наборы, мы получаем одинаковое разделение каждый раз, когда запускаем код.
На картинке ниже показано, как это работает:
Давайте разберемся в одном важном моменте. Многие люди используют значение random_state = 42. На изображении выше видно, что при установке random_state равным 42, мы получаем один и тот же фиксированный набор данных, который был перетасован. Это означает, что каждый раз, когда мы устанавливаем random_state равным 42, мы получаем один и тот же перетасованный набор данных.
Таким образом, число 42 не обладает особым значением для random_state.
Давайте посмотрим, как это можно использовать для разделения набора данных
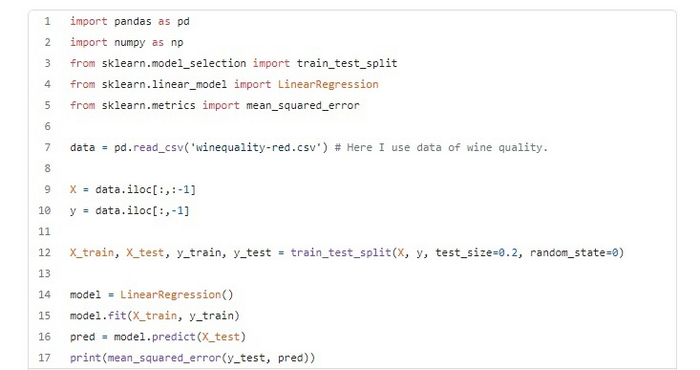
Здесь мы используем набор данных о качестве вина и модель линейной регрессии. Делаем просто, потому что наша основная цель — это random_state, а не точность.
Использование random_state при разделении
В представленном выше коде для random_state равного 0, mean_squared_error составила 0.384471197820124. Если мы попробуем разные значения для random_state, то каждый раз получим разные ошибки.
Для random_state = 1, mean_squared_error равна 0.38307198158142.
Для random_state = 69, mean_squared_error равна 0.47013897077423.
Для random_state = 143, mean_squared_error равна 0.42062134425032.
Сколько вообще возможных случайных состояний бывает?
Проведем эксперимент, чтобы определить, сколько различных комбинаций данных мы можем получить, переставляя исходный набор.
1. Мы берем набор из 5 чисел от 1 до 5.
2. Далее разделяем этот набор данных на обучающие и тестовые данные 2000 раз, используя значения random_state от 1 до 2000. Каждое значение random_state создает новую случайную последовательность разделения данных.
В итоге у нас будет список из 2000 перетасованных наборов данных, каждый полученный с использованием разного значения random_state.
Из всех этих перетасованных наборов данных только 120 окажутся уникальными. Это означает, что при использовании исходного набора данных из 5 чисел мы можем получить всего 120 различных комбинаций, переставляя их.
Установка значения random_state в диапазоне от 0 до 119 позволит нам получить одну из этих 120 уникальных комбинаций данных при каждом запуске алгоритма.
Эти выводы можно объяснить так:
Короче говоря, это про факториалы. При использовании набора данных из 5 чисел и их перестановкой, мы фактически создаем комбинации, а количество уникальных комбинаций, как можно заметить, равно факториалу числа 5, то есть 5! = 5 × 4 × 3 × 2 × 1 = 120.
Использование параметра `random_state` в этом контексте подобно выбору одной из 120 уникальных комбинаций данных. Каждое значение `random_state` соответствует одной из перестановок чисел, и они будут однозначно связаны с числами от 0 до 119, что совпадает с индексами возможных комбинаций факториала числа 5.
Этот эксперимент помогает нам понять, как параметр `random_state` влияет на разделение данных и на результаты моделирования в машинном обучении, потому что он определяет начальное состояние генератора псевдослучайных чисел. При разделении данных на обучающий и тестовый наборы с использованием `random_state` мы фиксируем последовательность случайных чисел, которая влияет на способ разделения данных.
Этот параметр важен, потому что он обеспечивает воспроизводимость результатов: при одном и том же значении `random_state` мы получаем одинаковую разбивку данных, что позволяет повторно воспроизвести эксперимент и проверить результаты моделирования. И именно таким образом, понимание того, как работает `random_state`, помогает нам контролировать случайность в нашем анализе данных и сделать его более надежным и воспроизводимым.
Зачем нам это нужно?
Давайте разберемся с random_state в контексте прогнозирования цен на жилье. Представьте, у нас есть данные о жилье, и по мере движения сверху вниз по этим данным, у нас становится либо больше комнат, либо увеличивается площадь квартир. Это то, что мы называем данными о смещении.
Теперь, если мы просто разделим наши данные без перетасовки, это даст нам неплохую производительность при обучении, но когда дело доходит до тестирования, она может быть не очень. Поэтому мы и используем перетасовку данных. Вот где random_state приходит на помощь!
Когда мы делим данные, то хотим, чтобы результаты каждый раз были одинаковыми. То есть, если мы перезапустим код, мы получим те же самые данные для обучения и тестирования, что и раньше.
Разные значения random_state могут дать нам разную производительность.
Например, разные значения random_state дают разные значения mean_squared_error.
Это означает, что если вы выберете случайное значение random_state, и вам повезет, то вы сможете свести к минимуму количество ошибок для этого значения.
Да и в других аспектах машинного обучения random_state пригодится. Например:
KMeans
В алгоритме KMeans параметр random_state определяет, как генерируются случайные числа для инициализации центроидов. Мы можем использовать целое число для того, чтобы сделать процесс генерации случайных чисел предсказуемым. Это полезно, когда нам нужно создавать одинаковые кластеры каждый раз.
Случайный лес
В классификаторе случайного леса и в модели регрессии параметр random_state контролирует начальное случайное состояние выборок, используемых при построении деревьев, и выборку объектов, учитываемых при поиске наилучшего разделения в каждом узле.
Дерево решений
В классификаторе дерева решений или регрессии, когда мы ищем наилучшие признаки для разделения узлов, тоже стоит задать параметр random_state. Этот определяет структуру дерева и гарантирует воспроизводимость результатов.
Ну, вот и всё, что вам нужно знать о random_state!